Se estiver a utilizar IA localmente, provavelmente já ouviu o conselho: «compre uma boa GPU». Mas o que é que isso significa, afinal? E será que a sua CPU é mesmo tão inútil assim? A resposta não é tão simples como «GPU boa, CPU má». O que importa é a forma como cada processador lida com os cálculos por trás da inferência de IA e qual deles consegue transferir dados com rapidez suficiente para acompanhar o ritmo.
O que acontece realmente durante a inferência de IA?
Quando executa um modelo LLM ou um modelo de imagem local, o seu hardware está a realizar uma única operação repetidamente: a multiplicação de matrizes. O modelo recebe a sua entrada, converte-a em números e submete esses números a milhares de milhões de operações matemáticas ao longo das suas camadas. Quanto mais rapidamente o seu hardware conseguir processar essas operações, mais rapidamente obterá uma resposta.
Isto é inferência, ou seja, gerar resultados a partir de um modelo treinado. Não estás a treinar nada. Estás apenas a aplicar os cálculos, um token de cada vez.
Como uma CPU processa tarefas de IA
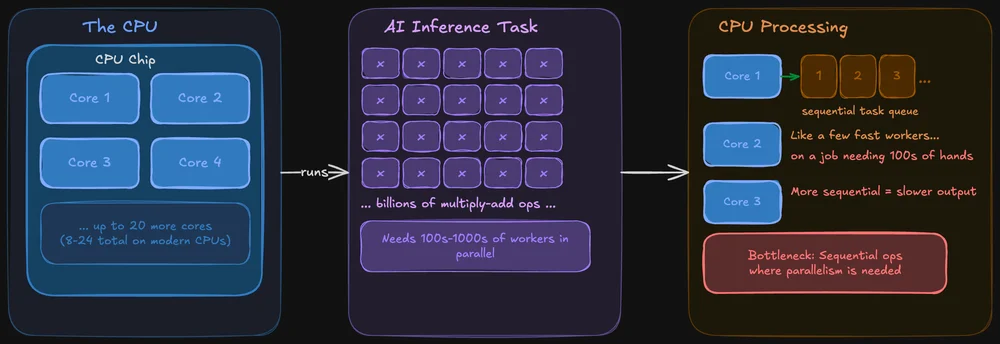
Uma CPU foi concebida para ser versátil. Ela gere o sistema operativo, os separadores do navegador, o sistema de ficheiros e, sim, também consegue executar modelos de IA. As CPUs modernas têm vários núcleos (normalmente entre 8 e 24 nos chips destinados ao consumidor), sendo cada núcleo potente e flexível.
O problema: a inferência de IA implica realizar a mesma operação em enormes quantidades de dados simultaneamente. Uma CPU consegue fazer isso, mas processa essas operações de forma mais sequencial. É como ter alguns trabalhadores muito rápidos a tentar realizar uma tarefa que, na verdade, precisa de centenas de pessoas a trabalhar ao mesmo tempo.
Dito isto, as CPUs não são uma opção inviável para a IA local. Ferramentas como o llama.cpp estão especificamente otimizadas para a inferência na CPU e, se o seu modelo couber na memória RAM do sistema, pode, sem dúvida, executá-lo apenas na CPU. Apenas será mais lento — por vezes de forma perceptível, outras vezes não —, dependendo do tamanho do modelo.
Como uma GPU processa tarefas de IA
Uma GPU foi concebida com base no paralelismo. Enquanto uma CPU pode ter entre 8 e 24 núcleos, uma GPU moderna possui milhares de núcleos mais pequenos, capazes de trabalhar simultaneamente em partes do mesmo problema. Isto torna as GPUs excepcionalmente eficientes no tipo de cálculos matemáticos em grande escala de que os modelos de IA dependem.
Além disso, as GPUs têm a sua própria memória dedicada (VRAM) com uma largura de banda muito superior à da RAM do sistema. Essa largura de banda é extremamente importante, pois determina a rapidez com que os dados podem ser enviados para esses milhares de núcleos. Mais largura de banda significa menos tempo de espera e mais tempo de processamento.
No que diz respeito especificamente à inferência de modelos de linguagem local (LLM), a vantagem da GPU resume-se a dois aspetos: capacidade de processamento paralelo e largura de banda de memória. Ambos afetam diretamente o número de tokens por segundo que se obtém na saída.
Largura de banda da memória
Eis algo que surpreende a maioria das pessoas: no que diz respeito à inferência de modelos de linguagem (LLM) locais, o poder de computação bruto nem sempre é o fator limitante. O que o é, na verdade, é a largura de banda da memória.
Durante a inferência, os pesos do modelo têm de ser lidos da memória para cada token gerado. Se a memória não conseguir fornecer dados ao processador com rapidez suficiente, não importa quantos núcleos tenha: eles ficam simplesmente à espera.
É por isso que a largura de banda da VRAM é tão importante. Uma configuração típica de memória de sistema DDR5 pode oferecer uma largura de banda de 50 a 90 GB/s. Uma GPU moderna, como uma RTX 5090, oferece mais de 1 000 GB/s. Trata-se de uma diferença de uma ordem de grandeza.
Se o seu modelo couber inteiramente na VRAM, a inferência será quase sempre mais rápida na GPU do que na CPU, apenas por esta razão.
Quando o uso exclusivo da CPU faz realmente sentido
A GPU nem sempre é a solução. Existem situações reais em que é mais adequado utilizar a CPU:
- Está a utilizar um modelo pequeno (com 3B parâmetros ou menos), em que a diferença de velocidade é quase imperceptível.
- Não possui uma placa gráfica compatível, ou a sua placa gráfica não tem memória de vídeo suficiente para carregar o modelo.
- Quer utilizar toda a memória RAM do sistema (que normalmente é muito maior do que a VRAM) para executar um modelo maior a uma velocidade mais baixa.
- Está a utilizar um computador portátil ou um sistema em que o consumo de energia ou o aquecimento da GPU são motivo de preocupação.
A inferência em CPU melhorou significativamente graças à quantização (redução da precisão do modelo para utilizar menos memória) e às estruturas otimizadas para esse fim. Um modelo quantizado de 7 mil milhões de parâmetros numa CPU moderna com 32 GB de RAM funciona suficientemente bem para muitas tarefas.


E quanto à transferência de tarefas?
Se o seu modelo for demasiado grande para a VRAM, mas ainda assim pretender utilizar a aceleração por GPU, a maioria das ferramentas LLM locais suporta o descarregamento parcial. Isto significa que algumas camadas do modelo são executadas na GPU, enquanto as restantes são executadas na CPU.
É uma questão de compromisso: obtém-se parte do ganho de velocidade da GPU, mas as camadas limitadas pela CPU tornam-se um estrangulamento. Quanto mais camadas for possível encaixar na VRAM, mais rápido será o processo. E se apenas algumas camadas forem processadas na GPU, a sobrecarga de transferir dados de um lado para o outro pode, na verdade, tornar o processo mais lento do que a inferência exclusivamente na CPU.
A regra geral: se não conseguir caber pelo menos metade do modelo na VRAM, provavelmente é melhor executá-lo inteiramente na CPU e poupar-se dessa complexidade.
NVIDIA vs AMD na IA local
A NVIDIA domina atualmente o mercado local de IA, principalmente graças à CUDA. Trata-se da sua plataforma de computação proprietária, na qual se baseiam praticamente todas as ferramentas de IA. Se estiver a utilizar o LM Studio, o Ollama ou o llama.cpp no Windows, as GPUs da NVIDIA proporcionar-lhe-ão a experiência mais fluida e com o mínimo de problemas.
A AMD está a recuperar o atraso. O ROCm (a resposta da AMD ao CUDA) registou progressos reais, e ferramentas como o Ollama suportam explicitamente as GPUs AMD Radeon no Windows. No entanto, o ecossistema continua a ser mais limitado, e poderá deparar-se com problemas de compatibilidade, dependendo da sua GPU específica e da ferramenta que estiver a utilizar.
Se pretende comprar especificamente para IA local, a NVIDIA é atualmente a aposta mais segura. Se já possui uma GPU AMD, vale absolutamente a pena experimentar; basta verificar primeiro a documentação da sua ferramenta para ver quais os modelos compatíveis.

Onde se encaixa o CORSAIR AI300
Se a sua configuração atual está a causar-lhe gargalos, seja por falta de VRAM, largura de banda de memória insuficiente ou um sistema que sobreaquece assim que carrega um modelo de 13 mil milhões de polígonos, este é precisamente o tipo de problema que a CORSAIR AI Workstation 300 (AI300) foi concebida para resolver.
A AI300 é uma estação de trabalho compacta concebida a pensar nas realidades da inferência de IA local:
- Configuração com grande capacidade de memória, com espaço para modelos mais complexos e janelas de contexto maiores.
- Memória gráfica concebida para se adaptar a cargas de trabalho de IA (e a alguns jogos).
- Um seletor de desempenho ao nível do hardware (Silencioso / Equilibrado / Máximo) para que possa dar prioridade à velocidade quando precisar e ao silêncio quando não precisar.
- A suíte de software CORSAIR AI, que simplifica a instalação para que gaste menos tempo a configurar e mais tempo a executar modelos.
Se tem tentado tirar o máximo partido da IA local num sistema que não foi concebido para esse fim, o AI300 oferece-lhe uma máquina em que o hardware e o software foram realmente concebidos a pensar nessa carga de trabalho.

PRODUTOS NO ARTIGO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.