Executar um modelo de linguagem grande (LLM) no seu próprio PC pode parecer intimidante, mas é surpreendentemente acessível. Um «LLM local» significa simplesmente que a IA é executada no seu hardware, sem nuvem, sem conta, e os seus dados permanecem consigo. Pense em brainstorming privado, ajuda com código e perguntas e respostas sobre documentos, tudo sem enviar nada online. Se isso lhe parece bom, vamos levá-lo do zero ao primeiro prompt.
Que ferramentas estamos a utilizar?
A opção mais adequada para iniciantes no momento é o Ollama, uma aplicação gratuita que descarrega e executa um vasto catálogo de modelos abertos com comandos de uma linha (agora inclui uma aplicação para Windows e macOS, para que não tenha de viver num terminal).
Se preferir uma experiência mais visual e completa, LM Studio (também gratuito) é outra ótima opção para descobrir, executar e gerir modelos locais. O Open WebUI é uma interface de chat leve e auto-hospedada que pode ser instalada sobre o Ollama. Escolha um ou misture e combine.


O que você vai precisar (hardware e sistema operativo)
- Sistema operativo: Windows 10/11, macOS ou Linux (mostraremos exemplos do Windows abaixo).
- Memória e armazenamento: 16–32 GB de RAM são suficientes para modelos com 7–13 bilhões de parâmetros; mais RAM ajuda em contextos maiores. Mantenha dezenas de GB livres num SSD para modelos e caches.
- GPU (opcional, mas útil): uma GPU moderna acelera as coisas e permite executar modelos maiores. No Windows, o Ollama suporta aceleração por GPU e publica compilações otimizadas para AMD.
- Nota sobre placas gráficas integradas AMD (APUs): Os novos sistemas Ryzen AI Max+ podem partilhar a memória do sistema como «memória gráfica variável», expondo até 96 GB de VRAM à iGPU com a configuração correta — útil para modelos maiores em casa.
Início rápido (Windows): o caminho mais rápido para o seu primeiro prompt
- Instalar o Ollama
- Faça o download do instalador do Windows da Ollama ou instale através do Winget: "winget install --id Ollama.Ollama"
Após a instalação, você terá o aplicativo Ollama (GUI) e a ferramenta de linha de comando.
- Iniciar e verificar
- Abra a aplicação Ollama para computador e inicie sessão, se solicitado (não é necessária uma nuvem para utilização local).
- Ou verifique a CLI: «ollama --version».(Verá um número de versão.)
- Puxe um modelo inicial
- No aplicativo, procure e baixe um modelo. Ou num terminal: "ollama run llama3:8b
- Istoirá descarregar o modelo e levá-lo a um prompt — digite uma pergunta e pronto. Pode navegar por vários modelos (Gemma, Llama, Qwen, OLMo e outros) na Biblioteca Ollama.
- (Opcional) Ativar aceleração por GPU
- Mantenha os seus controladores gráficos atualizados. O Ollama fornece compilações do Windows com aceleração AMD, e a AMD documenta os caminhos DirectML/ROCm para LLMs no Radeon. Na aplicação Ollama, confirme se a GPU foi detetada (ou observe a utilização da GPU no Gestor de Tarefas durante a geração).
Qual modelo deve experimentar primeiro?
- «Pequeno e ágil»: gemma3:1b ou llama3:8b, bons para respostas rápidas e hardware de baixo custo.
- «Equilibrado»: modelos 7B–13B (por exemplo, olmo2:7b, llama3:8b instruct) sólidos para uso geral.
- «Cérebros maiores»: modelos com mais de 20B (por exemplo, gpt-oss:20b, variantes maiores do Llama) precisam de mais RAM/VRAM e paciência, mas se destacam em tarefas mais difíceis. Pode aceder a qualquer um deles diretamente na aplicação ou através do comando ollama run <model>.
Dicas para otimizar o seu LLM local
- Comprimento do contexto: maior nem sempre é melhor. Contextos enormes (por exemplo, 32k-64k tokens) podem tornar a geração muito mais lenta. Comece com 4k–8k e aumente apenas quando necessário.
- Quantização: a maioria dos modelos fornecidos pelos aplicativos já vem quantizada, o que é útil para ajustar modelos maiores em uma VRAM limitada.
- Armazenamento: Mantenha os modelos num SSD; os HDDs serão lentos.
- Controladores: atualize regularmente os controladores da GPU e a aplicação A IA local está a evoluir rapidamente.
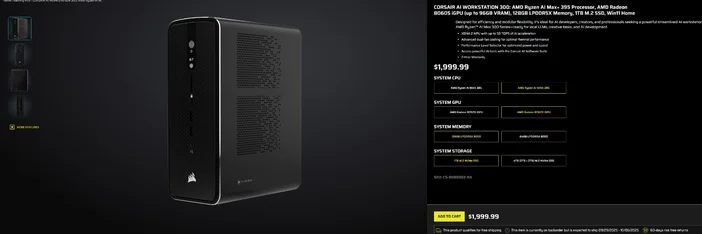
Utilizando a CORSAIR AI WORKSTATION 300
Se preferir evitar a montagem fragmentada e desejar um desktop compacto e silencioso, pronto para LLMs locais assim que sair da caixa, o CORSAIR AI WORKSTATION 300 atende a muitos requisitos de criadores e programadores:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (até 96 GB de VRAM), XDNA 2 NPU até 50 TOPS
- Memória e armazenamento: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB + 2 TB)
- SO: Windows 11 Home
- Design: chassis de formato pequeno de 4,4 L com refrigeração por duas ventoinhas e um seletor de nível de desempenho
Essa «VRAM de até 96 GB» na iGPU Radeon combina especialmente bem com as ferramentas do Windows, que podem alocar uma grande memória partilhada para a GPU, útil para modelos locais maiores e contextos mais longos quando necessário. É um caminho limpo e compacto para o desenvolvimento local de IA, sem comprometer a capacidade.
Perguntas frequentes
Preciso de uma GPU dedicada para executar um LLM local?
Não. É possível executar modelos menores em sistemas apenas com CPU, mas as respostas serão mais lentas. Uma GPU moderna ou uma APU avançada com grande memória partilhada melhora a velocidade e permite aumentar o tamanho do modelo.
Isso é privado?
Sim. Com ferramentas locais como Ollama ou LM Studio, os prompts e os dados permanecem na sua máquina por predefinição. (As integrações que adicionar podem comportar-se de forma diferente, por isso verifique sempre as definições.)
Onde posso encontrar modelos?
A Biblioteca Ollama lista opções populares e atualizadas (Llama, Gemma, Qwen, OLMo e outras). Cada página do modelo mostra tamanhos e exemplos de comandos.
A CORSAIR AI WORKSTATION 300 consegue lidar com modelos grandes?
Ele foi projetado para LLMs locais, com 128 GB de memória e uma iGPU que pode aceder até 96 GB de VRAM, excelente margem para cargas de trabalho locais avançadas e contextos longos, especialmente à medida que os controladores Windows da AMD expandem o suporte para grandes alocações. A taxa de transferência real depende do tamanho do modelo, quantização e configurações.
PRODUTOS NO ARTIGO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.