Exécuter un LLM en local signifie que le modèle réside sur votre PC et que vos requêtes (ainsi que les fichiers que vous lui fournissez) ne quittent pas votre machine. Pas de compte cloud. Pas de clés API. Pas de « on va entraîner le modèle avec vos données… peut-être pas… qui sait ». Juste vous, votre PC et un modèle qui s'acquitte de toutes les tâches que vous lui confiez.
Qu'est-ce qu'un « LLM local », exactement ?
Un LLM local est un grand modèle linguistique qui fonctionne sur votre ordinateur plutôt que sur un serveur distant. Concrètement, cela signifie généralement que vous téléchargez les fichiers du modèle, que vous les chargez dans une application locale et que vous discutez avec eux de la même manière que vous le feriez avec un assistant cloud, à la différence près que le « serveur » est votre PC.
« Exécuter » un LLM en local signifie presque toujours effectuer une inférence (générer des réponses), et non entraîner un tout nouveau modèle à partir de zéro.
Pourquoi utiliser un LLM local ?
Il existe plusieurs raisons pour lesquelles les utilisateurs passent des modèles de langage (LLM) hébergés dans le cloud à des modèles locaux :
- Confidentialité : vos invites restent stockées sur l'appareil (à condition que vous n'utilisiez pas de connecteurs cloud).
- Utilisation hors ligne : une fois le modèle téléchargé, vous pouvez l'utiliser sans connexion Internet.
- Pas de limite d'utilisation : pas de restriction de débit, pas de message « vous avez atteint votre quota quotidien », pas de facture surprise.
- Contrôle : choisissez le modèle qui vous convient, vous n'êtes pas lié à un abonnement.
Bien sûr, vous sacrifiez la commodité au profit du contrôle. Un modèle cloud peut sembler magique ; un modèle local peut sembler tout aussi magique, selon votre matériel.
De quoi a-t-on besoin pour faire fonctionner un LLM en local ?
En bref : le processeur fait le travail, le processeur graphique apporte un plus, et la mémoire joue un rôle crucial.
Voici ce qui détermine réellement si vous passerez un bon moment :
- Mémoire vive / Mémoire vidéo : les modèles plus volumineux nécessitent davantage de mémoire. Si vous manquez de mémoire, le modèle ne fonctionnera pas.
- Stockage : les modèles peuvent être volumineux. Certaines bibliothèques signalent que l'espace de stockage nécessaire peut atteindre plusieurs dizaines, voire plusieurs centaines de Go, selon le modèle que vous téléchargez.
- GPU : Si votre application prend en charge votre GPU, vous constaterez généralement un gain de vitesse considérable.
Un ordinateur moderne sous Windows 10/11 doté d'au moins 32 Go de RAM constitue une base solide pour les modèles locaux de petite taille, et une mémoire plus importante vous permet d'exécuter plus facilement les modèles plus volumineux.
Choisissez une application « LLM Runner » locale
LM Studio (interface graphique intuitive)
LM Studio est une application de bureau qui vous permet de télécharger des modèles et de discuter avec eux en local. Elle comprend également une API locale programmable destinée aux développeurs.
Ollama (interface en ligne de commande simple + API locale)
Ollama fonctionne comme une application native Windows et vous offre un flux de travail en ligne de commande ainsi qu'un point de terminaison API HTTP local. Il prend explicitement en charge les GPU NVIDIA et AMD Radeon sous Windows.
llama.cpp (pour les bricoleurs)
Si vous recherchez un contrôle maximal, llama.cpp est un moteur d'inférence open source très apprécié, qui propose des instructions de compilation et plusieurs backends.

Installez et exécutez votre premier modèle
Les modèles plus volumineux nécessitent davantage de mémoire vive (RAM) et/ou de mémoire vidéo (VRAM). Si vous n'en disposez pas suffisamment, vous risquez de subir des ralentissements, des plantages ou des transferts constants vers le disque dur (ce qui donne l'impression que votre PC fonctionne au ralenti).
Une règle empirique fiable pour les modèles quantifiés en int4:
- 8 Go de RAM → environ 3 milliards de modèles
- 16 Go de RAM → environ 7 milliards de modèles
- 32 Go de RAM → environ 13 milliards de modèles
Et si vous comptez sur l'accélération par GPU :
- 6 Go de mémoire vidéo → environ 3 milliards de modèles
- 8 Go de VRAM → environ 7 milliards de modèles
- 12 Go de mémoire vidéo → environ 13 milliards de modèles
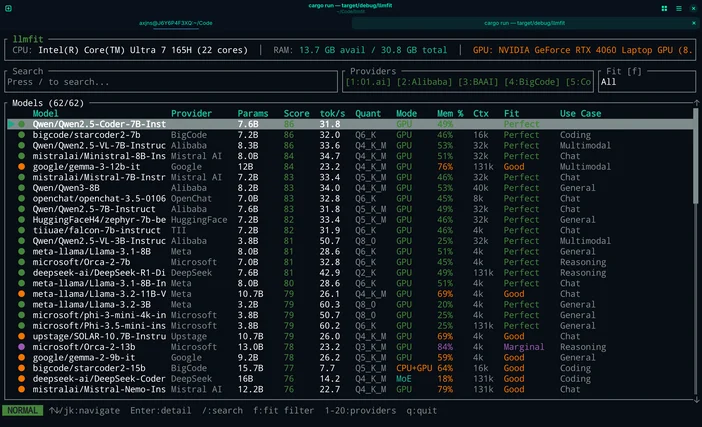
Ou, si vous ne voulez pas vous lancer dans des conjectures, vous pouvez utiliser LLMfit pour adapter les modèles à votre configuration matérielle exacte.
LLMfit est un outil en ligne de commande qui identifie votre processeur, votre mémoire vive et votre carte graphique/mémoire graphique, puis classe les modèles en fonction de leur compatibilité,de leur vitesse estimée,de leur contexte etde leur qualité, afin quevous puissiez voir lesquels fonctionneront correctement avant de télécharger quoi que ce soit.
À quoi ça sert :
- Trouver des modèles qui respectent réellement vos limites de RAM/VRAM
- Consulter la quantification recommandée (pour éviter de surcharger la mémoire)
- Obtenir une liste restreinte classée plutôt que de se perdre dans des hubs de modèles
Comment l'utiliser dans ce flux de travail :
- Lancez llmfit pour analyser le matériel de votre système
- Consultez les « suggestions » / recommandations en haut de la page
- Choisissez une taille de modèle adaptée à votre machine, puis téléchargez-la dans LM Studio / Ollama / llama
C'est parti !
C'est tout. Choisissez un moteur, téléchargez un modèle adapté à votre matériel, et lancez-vous ! Tout reste sur votre ordinateur. Pas besoin d'un diplôme en informatique, d'un abonnement au cloud ni d'un week-end à résoudre des problèmes. L'ensemble du processus prend à peu près autant de temps que l'installation d'un jeu. Et une fois qu'il est opérationnel, vous disposez d'un assistant IA privé et hors ligne qui fonctionne selon vos conditions.
À quoi sert le CORSAIR AI300 ?
Si vous envisagez sérieusement d'exécuter des modèles de langage (LLM) en local sous Windows, en particulier si vous souhaitez utiliser des modèles plus volumineux, des fenêtres de contexte plus étendues ou bénéficier de performances plus fluides, c'est ici que la CORSAIR AI Workstation 300 (AI300) et la suite logicielle CORSAIR AI vous aident à passer au niveau supérieur.
L'inférence locale se heurte généralement à des goulots d'étranglement au niveau de la mémoire et du débit. L'AI300 a été conçu pour répondre à cette réalité :
- Une station de travail compacte conçue pour les flux de travail d'IA en local
- Une configuration à grande capacité de mémoire qui vous offre une marge de manœuvre suffisante pour les modèles plus volumineux
- Comportement de la mémoire graphique conçu pour s'adapter aux cas d'utilisation de l'IA
- Un sélecteur de performances au niveau matériel (Silencieux / Équilibré / Max) qui vous permet de choisir entre le silence et la vitesse

Ai-je besoin d'un GPU NVIDIA pour faire fonctionner un LLM en local sous Windows ?
Non. Certains outils prennent explicitement en charge AMD sous Windows ; par exemple, la documentation Windows d'Ollama mentionne la prise en charge des GPU NVIDIA et AMD Radeon.
Puis-je faire fonctionner un LLM local entièrement hors ligne ?
Oui, une fois que vous avez téléchargé l'application et les fichiers de modèle. L'installation initiale et le téléchargement des modèles nécessitent généralement une connexion Internet, mais l'inférence peut s'effectuer hors ligne une fois que tout est disponible localement.
L'IA locale garantit-elle automatiquement la confidentialité ?
C'est possible, mais cela dépend de votre configuration. L'inférence locale signifie que le modèle s'exécute sur votre appareil, mais certaines applications proposent des connexions au cloud en option. Si votre objectif est de « ne pas avoir besoin du cloud », désactivez les intégrations au cloud et utilisez des modèles fonctionnant uniquement en mode local.
Pourquoi mon modèle local est-il lent ?
En général, l'un des suivants :
- Le modèle est trop volumineux pour la mémoire RAM/VRAM dont vous disposez
- Vous utilisez uniquement le processeur alors que l'accélération par GPU est disponible
- Tu as choisi une longueur de contexte élevée et ça monopolise la mémoire
- Votre espace de stockage est plein (oui, c'est important)
PRODUITS DANS L'ARTICLE
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.