Exécuter un modèle linguistique de grande taille (LLM) sur votre propre PC peut sembler intimidant, mais c'est étonnamment accessible. Un « LLM local » signifie simplement que l'IA fonctionne sur votre matériel, sans cloud ni compte, et que vos données restent chez vous. Imaginez des séances de brainstorming privées, une aide au codage et des questions-réponses sur des documents, le tout sans rien envoyer en ligne. Si cela vous intéresse, passons de zéro à la première invite.
Quels outils utilisons-nous ?
L'option la plus adaptée aux débutants à l'heure actuelle est Ollama, une application gratuite qui télécharge et exécute un large catalogue de modèles ouverts à l'aide de commandes d'une seule ligne (elle est désormais disponible sous forme d'application de bureau pour Windows et macOS, vous n'avez donc plus besoin de passer votre vie dans un terminal).
Si vous préférez une expérience plus visuelle et tout-en-un, LM Studio (également gratuit) est un autre excellent choix pour découvrir, exécuter et gérer des modèles locaux. Open WebUI est une interface de chat légère et auto-hébergée qui peut être installée sur Ollama. Choisissez-en une ou combinez-les.


Ce dont vous aurez besoin (matériel et système d'exploitation)
- Système d'exploitation : Windows 10/11, macOS ou Linux (nous vous montrerons des exemples sous Windows ci-dessous).
- Mémoire et stockage : une mémoire vive (RAM) de 16 à 32 Go est suffisante pour les modèles à 7-13 milliards de paramètres ; une mémoire vive plus importante facilite le traitement de contextes plus volumineux. Gardez plusieurs dizaines de Go libres sur un SSD pour les modèles et les caches.
- GPU (facultatif mais utile) : un GPU moderne accélère les opérations et vous permet d'exécuter des modèles plus volumineux. Sous Windows, Ollama prend en charge l'accélération GPU et publie des versions optimisées pour AMD.
- Remarque sur les cartes graphiques intégrées AMD (APU) : les nouveaux systèmes Ryzen AI Max+ peuvent partager la mémoire système en tant que « mémoire graphique variable », exposant jusqu'à 96 Go de VRAM à l'iGPU avec la bonne configuration, ce qui est utile pour les modèles plus grands à domicile.
Démarrage rapide (Windows) : le chemin le plus rapide vers votre première invite
- Installer Ollama
- Téléchargez le programme d'installation Windows depuis Ollama ou installez-le via Winget : «winget install --id Ollama.Ollama »
Après l'installation, vous disposerez à la fois de l'application Ollama (interface graphique) et de l'outil en ligne de commande.
- Lancer et vérifier
- Ouvrez l'application de bureau Ollama et connectez-vous si vous y êtes invité (aucun cloud n'est nécessaire pour une utilisation locale).
- Ou vérifiez l'interface CLI : «ollama --version ».(Vous verrez s'afficher un numéro de version.)
- Tirer un modèle de démarrage
- Dans l'application, parcourez et téléchargez un modèle. Ou dans un terminal : « ollama run llama3:8b ».
- «Cela téléchargera le modèle et vous amènera à une invite : tapez une question et lancez-vous. Vous pouvez parcourir de nombreux modèles (Gemma, Llama, Qwen, OLMo, etc.) dans la bibliothèque Ollama.
- (Facultatif) Activer l'accélération GPU
- Maintenez vos pilotes graphiques à jour. Ollama fournit des versions Windows avec accélération AMD, et AMD documente les chemins DirectML/ROCm pour les LLM sur Radeon. Dans l'application Ollama, vérifiez que le GPU est détecté (ou surveillez l'utilisation du GPU dans le Gestionnaire des tâches pendant la génération).
Quel modèle devriez-vous essayer en premier ?
- « Petit et rapide » : gemma3:1b ou llama3:8b, idéal pour les réponses rapides et le matériel bas de gamme.
- « Équilibré » : modèles 7B–13B (par exemple, olmo2:7b, llama3:8b instruct) solides pour une utilisation générale.
- « Des cerveaux plus puissants » : les modèles de plus de 20 milliards (par exemple, gpt-oss:20b, les variantes Llama plus importantes) nécessitent davantage de RAM/VRAM et de patience, mais excellent dans les tâches plus complexes. Vous pouvez les utiliser directement dans l'application ou via ollama run <model>.
Conseils pour optimiser votre LLM local
- Longueur du contexte: plus long n'est pas toujours mieux. Les contextes très longs (par exemple, 32 000 à 64 000 tokens) peuvent ralentir considérablement la génération. Commencez par 4 000 à 8 000 tokens, et augmentez uniquement si nécessaire.
- Quantification: la plupart des modèles fournis par les applications sont déjà quantifiés, ce qui est pratique pour adapter des modèles plus volumineux à une mémoire VRAM limitée.
- Stockage: conservez les modèles sur un SSD ; les disques durs seront trop lents.
- Pilotes: mettez régulièrement à jour les pilotes GPU et l'application. L'IA locale évolue rapidement.
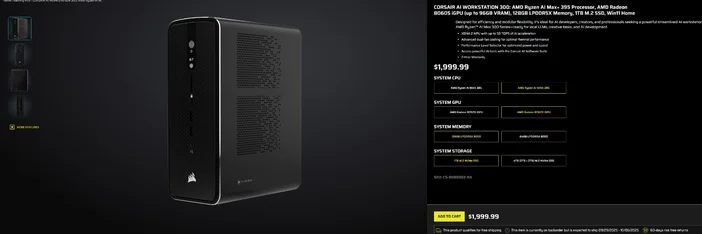
Utilisation de la CORSAIR AI WORKSTATION 300
Si vous préférez éviter l'assemblage pièce par pièce et que vous souhaitez un ordinateur de bureau compact et silencieux, prêt à l'emploi pour les LLM locaux, le CORSAIR AI WORKSTATION 300 répond à de nombreux critères pour les créateurs et les développeurs :
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (jusqu'à 96 Go de VRAM), XDNA 2 NPU jusqu'à 50 TOPS
- Mémoire et stockage: 128 Go LPDDR5X‑8000, 4 To NVMe (2 To + 2 To)
- Système d'exploitation: Windows 11 Famille
- Conception: châssis compact de 4,4 litres avec refroidissement à double ventilateur et sélecteur de niveau de performance
La « mémoire VRAM pouvant atteindre 96 Go » de l'iGPU Radeon s'associe particulièrement bien aux outils Windows qui peuvent allouer une grande mémoire partagée au GPU, ce qui est pratique pour les modèles locaux plus volumineux et les contextes plus longs lorsque vous en avez besoin. Il s'agit d'une voie claire et compacte vers le développement local de l'IA sans compromettre la capacité.
FAQ
Ai-je besoin d'un GPU dédié pour exécuter un LLM local ?
Non. Vous pouvez exécuter des modèles plus petits sur des systèmes équipés uniquement d'un processeur, mais les réponses seront plus lentes. Un GPU moderne ou un APU avancé avec une grande mémoire partagée améliore la vitesse et vous permet d'augmenter la taille du modèle.
Est-ce privé ?
Oui. Avec des outils locaux tels que Ollama ou LM Studio, les invites et les données restent par défaut sur votre ordinateur. (Les intégrations que vous ajoutez peuvent se comporter différemment, vérifiez toujours les paramètres.)
Où puis-je trouver des modèles ?
La bibliothèque Ollama répertorie les options populaires et à jour (Llama, Gemma, Qwen, OLMo, etc.). Chaque page de modèle indique les tailles et des exemples de commandes.
La CORSAIR AI WORKSTATION 300 peut-elle gérer des modèles volumineux ?
Il est conçu pour les LLM locaux, avec une mémoire de 128 Go et un iGPU pouvant accéder à jusqu'à 96 Go de VRAM, ce qui offre une excellente marge pour les charges de travail locales avancées et les contextes longs, d'autant plus que les pilotes Windows d'AMD étendent la prise en charge des allocations importantes. Le débit réel dépend de la taille du modèle, de la quantification et des paramètres.
PRODUITS DANS L'ARTICLE
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.