HOW TO
CPU frente a GPU para la IA local: ¿qué es lo que realmente la hace más rápida?
Última actualización:
Si estás ejecutando IA de forma local, probablemente hayas visto el consejo: «hazte con una buena GPU». Pero, ¿qué significa eso realmente? ¿Y es tu CPU realmente tan inútil? La respuesta no es tan sencilla como «la GPU es buena, la CPU es mala». Lo que importa es cómo gestiona cada procesador los cálculos matemáticos que hay detrás de la inferencia de IA y cuál de ellos es capaz de mover los datos con la rapidez suficiente para seguir el ritmo.
¿Qué ocurre realmente durante la inferencia de IA?
Cuando ejecutas un modelo LLM o un modelo de imágenes local, tu hardware realiza una y otra vez la misma operación: la multiplicación de matrices. El modelo toma tus datos de entrada, los convierte en números y los somete a miles de millones de operaciones matemáticas a lo largo de sus capas. Cuanto más rápido pueda tu hardware procesar esas operaciones, más rápido obtendrás una respuesta.
Esto es la inferencia, es decir, generar resultados a partir de un modelo entrenado. No estás entrenando nada. Simplemente estás aplicando los cálculos, token a token.
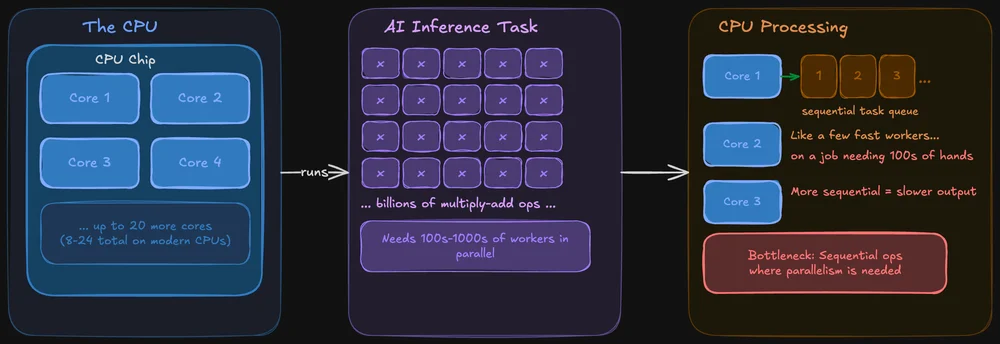
Cómo gestiona una CPU las tareas de IA
Una CPU está diseñada para rendir bien en todo. Se encarga del sistema operativo, de las pestañas del navegador, del sistema de archivos y, sí, también puede ejecutar modelos de IA. Las CPU modernas cuentan con múltiples núcleos (normalmente entre 8 y 24 en los chips de consumo), y cada núcleo es potente y flexible.
El problema: la inferencia de IA consiste en realizar la misma operación en enormes cantidades de datos de forma simultánea. Una CPU puede hacerlo, pero procesa esas operaciones de forma más secuencial. Es como tener unos pocos trabajadores muy rápidos encargándose de una tarea que realmente requiere cientos de manos trabajando a la vez.
Dicho esto, las CPU no son una opción descartable para la IA local. Herramientas como llama.cpp están optimizadas específicamente para la inferencia en CPU y, si tu modelo cabe en la memoria RAM del sistema, puedes ejecutarlo perfectamente solo con la CPU. Simplemente será más lento, a veces de forma notable y otras no, dependiendo del tamaño del modelo.
Cómo gestiona una GPU las tareas de IA
Una GPU está diseñada en torno al paralelismo. Mientras que una CPU puede tener entre 8 y 24 núcleos, una GPU moderna cuenta con miles de núcleos más pequeños que pueden trabajar simultáneamente en partes del mismo problema. Esto hace que las GPU sean excepcionalmente eficaces en el tipo de cálculos matemáticos a gran escala de los que dependen los modelos de IA.
Además, las GPU cuentan con su propia memoria dedicada (VRAM), con un ancho de banda mucho mayor que el de la RAM del sistema. Ese ancho de banda es muy importante, ya que determina la rapidez con la que se pueden enviar datos a esos miles de núcleos. Un mayor ancho de banda se traduce en menos tiempo de espera y más tiempo de cálculo.
En lo que respecta específicamente a la inferencia de modelos de lenguaje grande (LLM) locales, la ventaja de la GPU se reduce a dos aspectos: la potencia de procesamiento paralelo y el ancho de banda de la memoria. Ambos factores influyen directamente en el número de tokens por segundo que se obtienen en la salida.
Ancho de banda de memoria
Hay algo que sorprende a la mayoría de la gente: en el caso de la inferencia de modelos de lenguaje grande (LLM) locales, la potencia de cálculo bruta no suele ser el factor limitante. Lo es el ancho de banda de la memoria.
Durante la inferencia, es necesario leer los pesos del modelo de la memoria para cada token generado. Si la memoria no es capaz de suministrar datos al procesador con la suficiente rapidez, da igual cuántos núcleos tengas: estos se quedarán ahí esperando.
Por eso el ancho de banda de la VRAM es tan importante. Una configuración típica de memoria del sistema DDR5 puede ofrecer un ancho de banda de entre 50 y 90 GB/s. Una GPU moderna, como una RTX 5090, ofrece más de 1.000 GB/s. Se trata de una diferencia de un orden de magnitud.
Si tu modelo cabe por completo en la VRAM, la inferencia será casi siempre más rápida en la GPU que en la CPU, aunque solo sea por esta razón.
Cuándo realmente tiene sentido utilizar solo la CPU
La GPU no siempre es la solución. Hay situaciones reales en las que es mejor ejecutar el proceso en la CPU:
- Estás ejecutando un modelo pequeño (3B parámetros o menos) en el que la diferencia de velocidad apenas se nota.
- No tienes una tarjeta gráfica compatible, o tu tarjeta gráfica no tiene suficiente memoria VRAM para cargar el modelo.
- Quieres utilizar toda la memoria RAM del sistema (que suele ser mucho mayor que la VRAM) para ejecutar un modelo más grande a una velocidad menor.
- Estás utilizando un ordenador portátil o un sistema en el que el consumo energético o el calor de la GPU son un problema.
La inferencia en CPU ha mejorado considerablemente gracias a la cuantificación (que reduce la precisión del modelo para utilizar menos memoria) y a los marcos optimizados para ello. Un modelo cuantificado de 7 000 millones de parámetros en una CPU moderna con 32 GB de RAM funciona lo suficientemente bien para muchas tareas.


¿Y qué hay de la descarga?
Si tu modelo es demasiado grande para la VRAM pero aún así quieres aprovechar la aceleración por GPU, la mayoría de las herramientas locales de LLM admiten la descarga parcial. Esto significa que algunas capas del modelo se ejecutan en la GPU, mientras que el resto se ejecuta en la CPU.
Es una cuestión de equilibrio: se obtiene parte de la ventaja de velocidad de la GPU, pero las capas que dependen de la CPU se convierten en un cuello de botella. Cuantas más capas quepan en la VRAM, más rápido será el proceso. Y si solo unas pocas capas terminan en la GPU, la sobrecarga que supone el traslado de datos de un lado a otro podría, de hecho, ralentizarlo más que una inferencia realizada exclusivamente en la CPU.
Una regla general: si no puedes cargar al menos la mitad del modelo en la VRAM, probablemente te convenga más ejecutarlo íntegramente en la CPU y ahorrarte así complicaciones.
NVIDIA frente a AMD en IA local
En estos momentos, NVIDIA domina el sector local de la IA, sobre todo gracias a CUDA, su marco de computación propio en el que se basan casi todas las herramientas de IA. Si utilizas LM Studio, Ollama o llama.cpp en Windows, las GPU de NVIDIA te ofrecerán la experiencia más fluida y te ahorrarán problemas técnicos.
AMD está ganando terreno. ROCm (la respuesta de AMD a CUDA) ha logrado avances significativos, y herramientas como Ollama son totalmente compatibles con las GPU AMD Radeon en Windows. Sin embargo, el ecosistema sigue siendo más limitado, y es posible que te encuentres con problemas de compatibilidad dependiendo de tu GPU concreta y de la herramienta que utilices.
Si vas a comprar un producto específicamente para IA local, NVIDIA es la opción más segura en este momento. Si ya tienes una GPU de AMD, sin duda merece la pena probarlo; eso sí, comprueba primero en la documentación de tu herramienta cuáles son los modelos compatibles.

Dónde encaja el CORSAIR AI300
Si tu configuración actual te está limitando, ya sea por falta de VRAM, un ancho de banda de memoria lento o un sistema que se sobrecalienta en cuanto cargas un modelo de 13B, este es precisamente el tipo de problema para el que se ha diseñado la CORSAIR AI Workstation 300 (AI300).
La AI300 es una estación de trabajo compacta diseñada teniendo en cuenta las realidades de la inferencia de IA local:
- Configuración con gran capacidad de memoria, que permite utilizar modelos más complejos y ventanas de contexto más amplias.
- Memoria gráfica diseñada para adaptarse a las cargas de trabajo de IA (y a algunos juegos).
- Un selector de rendimiento a nivel de hardware (Silencioso / Equilibrado / Máximo) para que puedas dar prioridad a la velocidad cuando la necesites y al silencio cuando no la necesites.
- El paquete de software CORSAIR AI, que simplifica la instalación para que dediques menos tiempo a la configuración y más tiempo a ejecutar modelos.
Si has estado intentando sacar el máximo partido a la IA local en un sistema que no fue diseñado para ello, AI300 te ofrece una máquina en la que tanto el hardware como el software se han diseñado específicamente para esa carga de trabajo.

PRODUCTOS EN EL ARTÍCULO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.