HOW TO
Cómo ejecutar un modelo de lenguaje grande (LLM) local en Windows (sin necesidad de la nube)
Última actualización:
Ejecutar un modelo de lenguaje grande (LLM) de forma local significa que el modelo reside en tu ordenador, y que tus indicaciones (y cualquier archivo que le envíes) no tienen que salir de tu equipo. Sin cuenta en la nube. Sin claves API. Sin «entrenaremos el modelo con tus datos… probablemente no… quizá». Solo tú, tu ordenador y un modelo que realiza cualquier tarea que le encomiendes.
¿Qué es exactamente un «LLM local»?
Un LLM local es un modelo de lenguaje a gran escala que se ejecuta en tu ordenador en lugar de en un servidor remoto. En la práctica, esto suele significar que descargas los archivos del modelo, los cargas en una aplicación local y chateas con ellos de la misma forma que lo harías con un asistente en la nube, salvo que el «servidor» es tu ordenador.
«Ejecutar» un modelo de lenguaje grande (LLM) de forma local casi siempre implica realizar inferencias (generar respuestas), y no entrenar un modelo completamente nuevo desde cero.
¿Por qué utilizar un modelo de lenguaje grande (LLM) local?
Hay varias razones por las que la gente pasa de los modelos de lenguaje grandes (LLM) en la nube a los locales:
- Privacidad: Tus indicaciones permanecen en el dispositivo (siempre que no utilices conectores en la nube).
- Uso sin conexión: una vez descargado el modelo, puedes ejecutarlo sin conexión a Internet.
- Sin límites de uso: sin restricciones de velocidad, sin mensajes del tipo «has agotado tu cuota diaria» y sin facturas inesperadas.
- Control: Elige el modelo que prefieras, sin estar obligado a contratar una suscripción.
Por supuesto, estás cambiando la comodidad por el control. Un modelo en la nube puede parecer mágico; un modelo local puede parecer mágico dependiendo de tu hardware.
¿Qué se necesita para ejecutar un modelo de lenguaje grande (LLM) de forma local?
En resumen: la CPU es fundamental, la GPU ayuda y la memoria es importante.
Esto es lo que realmente influye en que te lo pases bien:
- RAM / VRAM: Los modelos más grandes necesitan más memoria. Si te quedas sin memoria, el modelo dejará de funcionar.
- Almacenamiento: Los modelos pueden ocupar mucho espacio. Algunas bibliotecas advierten de que el almacenamiento de los modelos puede alcanzar entre decenas y cientos de GB, dependiendo del modelo que se descargue.
- GPU: Si tu aplicación es compatible con tu GPU, normalmente notarás un gran aumento de la velocidad.
Un ordenador moderno con Windows 10/11 y 32 GB o más de RAM es una buena base para modelos locales más pequeños, y disponer de más memoria te permite ejecutar los más grandes con mayor comodidad.
Elige una aplicación de «ejecución local de LLM»
LM Studio (interfaz gráfica de usuario sencilla)
LM Studio es una aplicación de escritorio que te permite descargar modelos y chatear con ellos de forma local. También incluye una API local programable para desarrolladores.
Ollama (interfaz de línea de comandos sencilla + API local)
Ollama se ejecuta como una aplicación nativa de Windows y ofrece un flujo de trabajo de línea de comandos, además de un punto de conexión API HTTP local. Es totalmente compatible con las GPU NVIDIA y AMD Radeon en Windows.
llama.cpp (para los más curiosos)
Si quieres el máximo control, llama.cpp es un popular motor de inferencia de código abierto que incluye instrucciones de compilación y múltiples backends.

Instala y ejecuta tu primer modelo
Los modelos más grandes necesitan más RAM y/o VRAM. Si no tienes suficiente, notarás un rendimiento lento, fallos del sistema o un intercambio constante con el disco (lo que da la sensación de que tu PC va a paso de tortuga).
Una regla general fiable para los modelos cuantificados en int4:
- 8 GB de RAM → ~3000 modelos
- 16 GB de RAM → ~7 000 millones de modelos
- 32 GB de RAM → ~13 000 millones de modelos
Y si utilizas la aceleración por GPU:
- 6 GB de VRAM → ~3000 millones de modelos
- 8 GB de VRAM → ~7 000 millones de modelos
- 12 GB de VRAM → ~13 000 millones de modelos
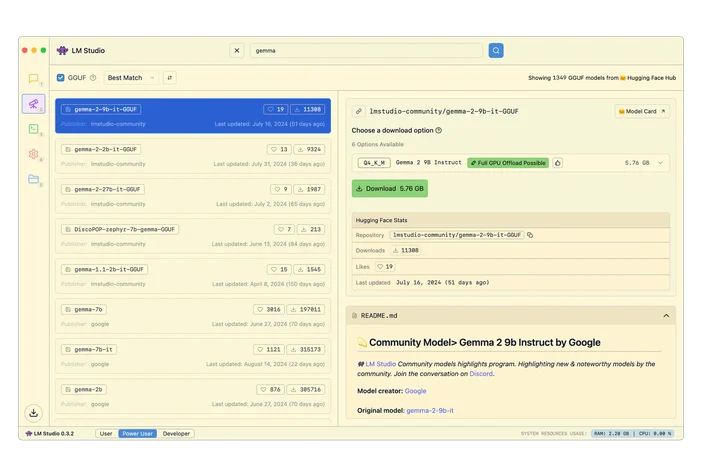
O, si no quieres ir a ciegas, puedes usar LLMfit para adaptar los modelos a tu hardware concreto.
LLMfit es una herramienta de terminal que detecta tu CPU, RAM y GPU/VRAM, y luego clasifica los modelos según su compatibilidad, velocidad prevista, contexto y calidad, para quepuedas ver cuáles funcionarán bien antes de descargar nada.
Para qué sirve:
- Encontrar modelos que se ajusten realmente a tus límites de RAM/VRAM
- Ver la cuantificación recomendada (para no sobreutilizar la memoria)
- Obtener una lista de candidatos preseleccionados en lugar de centros de modelos que invitan a el pasar el tiempo sin fin en las redes sociales
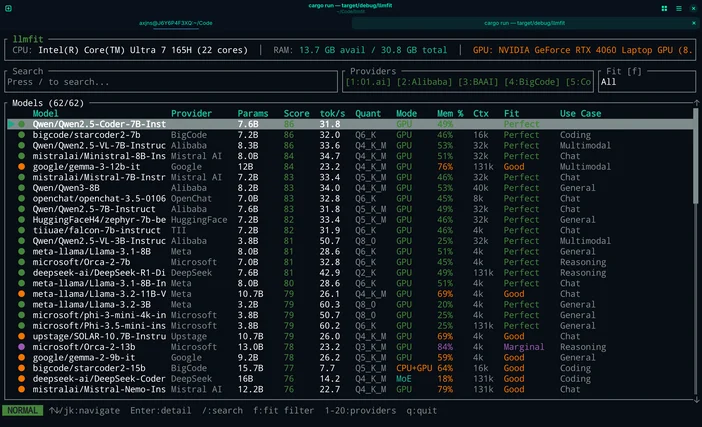
Cómo utilizarlo en este flujo de trabajo:
- Ejecuta llmfit para analizar el hardware de tu sistema
- Echa un vistazo a las «combinaciones» o recomendaciones que aparecen en la parte superior
- Elige un tamaño de modelo que se adapte a tu máquina y, a continuación, descárgalo en LM Studio / Ollama / llama
¡Ya está todo listo!
Eso es todo. Elige un entorno de ejecución, descarga un modelo que se adapte a tu equipo y ¡empieza a dar órdenes! Todo se queda en tu ordenador. No necesitas un título en informática, una suscripción a la nube ni pasar el fin de semana solucionando problemas. Todo el proceso dura más o menos lo mismo que instalar un juego. Y una vez que esté en marcha, tendrás un asistente de IA privado y sin conexión que funciona según tus condiciones.
Dónde encaja el CORSAIR AI300
Si de verdad te interesa ejecutar modelos de lenguaje grandes (LLM) locales en Windows, sobre todo si buscas modelos más grandes, ventanas de contexto más amplias o un rendimiento más fluido, aquí es donde la CORSAIR AI Workstation 300 (AI300) y el paquete de software CORSAIR AI te ayudan a dar un salto cualitativo.
La inferencia local suele verse limitada por la memoria y el rendimiento. El AI300 se ha diseñado teniendo en cuenta esta realidad:
- Una estación de trabajo compacta diseñada para flujos de trabajo de IA locales
- Configuración con gran capacidad de memoria que te ofrece margen suficiente para modelos más grandes
- Comportamiento de la memoria gráfica diseñado para adaptarse a los casos de uso de la IA
- Un selector de rendimiento a nivel de hardware (Silencioso / Equilibrado / Máximo) para que puedas decidir si prefieres el silencio o la velocidad

¿Necesito una GPU NVIDIA para ejecutar un modelo de lenguaje grande (LLM) local en Windows?
No. Algunas herramientas son compatibles explícitamente con AMD en Windows; por ejemplo, la documentación de Ollama para Windows menciona la compatibilidad tanto con NVIDIA como con las GPU AMD Radeon.
¿Puedo ejecutar un modelo de lenguaje grande (LLM) local sin conexión?
Sí, una vez que hayas descargado la aplicación y los archivos del modelo. La instalación inicial y la descarga de los modelos suelen requerir conexión a Internet, pero la inferencia se puede ejecutar sin conexión una vez que todo está almacenado localmente.
¿La IA local es privada por defecto?
Puede serlo, pero depende de tu configuración. La inferencia local significa que el modelo se ejecuta en tu dispositivo, aunque algunas aplicaciones ofrecen conexiones opcionales a la nube. Si tu objetivo es «no necesitar la nube», mantén desactivadas las integraciones con la nube y utiliza modelos exclusivamente locales.
¿Por qué mi modelo local va tan lento?
Normalmente, una de estas:
- El modelo es demasiado grande para la RAM/VRAM disponible
- Estás utilizando solo la CPU cuando hay aceleración por GPU disponible
- Has elegido una longitud de contexto elevada y está consumiendo mucha memoria
- Tu espacio de almacenamiento está lleno (sí, es importante)
PRODUCTOS EN EL ARTÍCULO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.