BLOG
Gemma 4: El nuevo modelo abierto de Google y por qué funciona mejor en ordenadores personales
Última actualización:
Google acaba de lanzar Gemma 4, su familia de modelos de peso abierto más potente hasta la fecha, lo que supone una gran noticia para cualquiera que utilice la IA de forma local en equipos comunes. Lanzada el 31 de marzo de 2026 bajo una licencia Apache 2.0 totalmente permisiva, Gemma 4 está diseñada para ofrecer una inteligencia de vanguardia en GPU de consumo e incluso en ordenadores portátiles, sin necesidad de suscripción.
La gama abarca cuatro tamaños: E2B (2.300 millones de parámetros efectivos), E4B (4.500 millones de parámetros efectivos), una variante «Mixture-of-Experts» de 26.000 millones con solo 4.000 millones de parámetros activos, y un modelo denso de 31.000 millones. Esto te ofrece desde modelos aptos para el borde hasta modelos cercanos a la frontera en una sola familia, y todos ellos se ejecutan en el tipo de PC que los ensambladores ya están montando.

¿Qué hace que Gemma 4 destaque?
Gemma 4 no solo es más grande, sino que también es más inteligente en cada parámetro. Algunos aspectos destacados:
- Razonamiento avanzado y agentes: planificación en varios pasos, matemáticas, programación y flujos de trabajo autónomos listos para usar.
- Multimodal: gestiona texto e imágenes de forma nativa, con soporte de audio en las variantes más pequeñas, E2B y E4B. El análisis de documentos, el reconocimiento de gráficos y el OCR de escritura manuscrita funcionan todos en una sola solicitud.
- Contexto masivo: 128 000 tokens para E2B/E4B, y nada menos que 256 000 tokens para los modelos densos de 26 000 millones y 31 000 millones, lo suficientemente amplio como para incluir un código fuente completo o un montón de documentos.
- Multilingüe: entrenado en más de 140 idiomas, con una sólida compatibilidad inmediata para docenas de ellos.
Se ofrece en Hugging Face en variantes preentrenadas y ajustadas para instrucciones, y funciona desde el primer día con las herramientas que ya utilizas: Ollama, LM Studio, llama.cpp, vLLM y Transformers.
Por qué los ordenadores personales son el punto fuerte de Gemma 4
Gemma 4 se diseñó teniendo como objetivo principal la inferencia local, y las cifras lo confirman. NVIDIA y Google colaboraron en las optimizaciones iniciales para las tarjetas RTX, y el reciente trabajo en llama.cpp ha reducido el uso de memoria de la caché KV en casi un 40 % en escenarios con contextos largos.
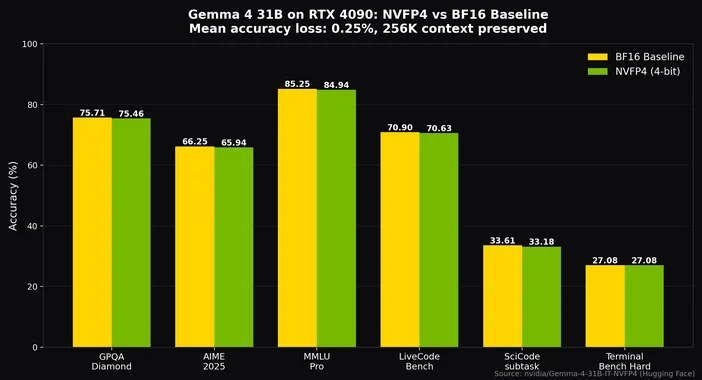
Con la cuantificación Q4_K_M, el punto óptimo para la mayoría de las configuraciones, es posible ejecutar el modelo MoE de 26 000 millones de parámetros en una tarjeta de 24 GB, como una RTX 4090 o una 3090, con espacio suficiente para un contexto de 8 000 tokens, y seguir alcanzando una velocidad de más de 20 tokens por segundo. Con la cuantización NVFP4 de NVIDIA, incluso el modelo denso de 31 000 millones de pesos cabe en una sola RTX 4090 con solo una pérdida de precisión de aproximadamente el 0,25 %, al tiempo que se conserva el contexto completo de 256 000 tokens.
Guía rápida de montaje
E2B / E4B (periferia y baja latencia): Una RTX 3060 o 4060 con 8 o 12 GB de VRAM y un Ryzen 5 o Core i5 moderno es más que suficiente. Combínala con 32 GB de DDR5 y un sistema de refrigeración AIO silencioso si tienes pensado realizar sesiones prolongadas.
26B MoE / 31B denso (para razonamiento y multimodal): opta por una RTX 4090 (o una 3090 si ya tienes una), un Ryzen 7 / Core i7 o superior, 64 GB de DDR5, un disco NVMe Gen4 rápido para la carga de modelos y una fuente de alimentación de 850 W o más en una carcasa con gran flujo de aire. Algo como un CORSAIR iCUE LINK TITAN RX RGB 360 mm AIO mantiene la GPU y la CPU a buen rendimiento bajo cargas de inferencia sostenidas.

La serie RTX 50 ofrece a Gemma 4 aún más margen para contextos más amplios y una inferencia más rápida.
Guía de inicio rápido en tu PC
1. Instala Ollama o LM Studio.
2. Descarga un modelo Gemma 4 de Hugging Face (empieza con gemma4:e4b si eres nuevo, o con gemma4:31b si dispones de VRAM).
3. Ejecuta la inferencia y espera alcanzar más de 50 o 100 tokens por segundo en la serie RTX 40 para las variantes más pequeñas.
4. Prueba la función multimodal: sube una imagen junto con una indicación y deja que analice una captura de pantalla, un gráfico o una foto.
Gemma 4 On-Device: ahora también para dispositivos móviles
El enfoque en el procesamiento en el borde de Gemma 4 se extiende a los teléfonos. Las variantes más pequeñas, E2B y E4B, funcionan con CPU Arm y GPU móviles con una latencia prácticamente nula para el reconocimiento de voz, el análisis de imágenes y los asistentes integrados en el dispositivo, sin necesidad de recurrir a la nube. La pila de IA en el borde de Google y Android AICore permiten su uso en todo el sistema Android, mientras que los desarrolladores de iOS pueden acceder a la CPU y la GPU a través de Metal.
Gemma 4 es la prueba más clara hasta la fecha de que los ordenadores personales de gama alta no son solo equipos para juegos, sino auténticas estaciones de trabajo de IA. Peso abierto, una licencia permisiva, razonamiento de vanguardia y una ventana de contexto de 256 K que realmente cabe en una sola GPU. Si ya tienes un equipo moderno de CORSAIR, tienes casi todo lo necesario para una auténtica estación de trabajo de IA local. Si estás configurando una, planifícala con una tarjeta de 24 GB, 64 GB de DDR5 y un sistema de refrigeración por circuito cerrado que no se resienta bajo una carga sostenida.

¿Quieres ejecutar Gemma en tu equipo? Te presentamos la CORSAIR AI Workstation 300
Si buscas una forma sin concesiones de ejecutar Gemma 4 (y otros modelos abiertos) íntegramente en tu propio hardware, la CORSAIR AI Workstation 300 está diseñada específicamente para ello. Combina un AMD Ryzen AI Max+ 395 con la iGPU Radeon 8060S y hasta 96 GB de VRAM unificada de los 128 GB de memoria LPDDR5X-8000, lo que te ofrece suficiente margen para cargar y ajustar variantes grandes de Gemma localmente sin necesidad de paginar al disco. Una NPU dedicada de 50 TOPS acelera la inferencia, y todo el sistema cabe en un chasis de 4,4 litros que puedes colocar en tu escritorio. Para los desarrolladores e investigadores que buscan privacidad, baja latencia y cero costes por token, es una de las mejores formas de poner Gemma a trabajar.
PRODUCTOS EN EL ARTÍCULO
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.