구글이 역대 가장 뛰어난 성능을 자랑하는 오픈 웨이트 모델 제품군인 ‘Gemma 4’를 출시했는데, 이는 일반 하드웨어에서 AI를 로컬로 실행하는 모든 사용자에게 매우 반가운 소식입니다. 2026년 3월 31일, 완전히 개방적인 아파치 2.0 라이선스 하에 공개된 Gemma 4는 구독료 없이도 일반 소비자용 GPU는 물론 노트북에서도 최첨단 수준의 지능을 제공하도록 설계되었습니다.
이 제품군은 E2B(유효 매개변수 23억 개), E4B(유효 매개변수 45억 개), 활성 매개변수가 40억 개에 불과한 26B Mixture-of-Experts 변형 모델, 그리고 31B 밀집 모델 등 총 4가지 규모로 구성되어 있습니다. 이를 통해 단일 제품군 내에서 엣지 컴퓨팅에 적합한 모델부터 최첨단 수준에 가까운 모델까지 모두 활용할 수 있으며, 모든 모델은 PC 조립 전문가들이 이미 구성하고 있는 수준의 사양으로도 원활하게 구동됩니다.

Gemma 4의 차별화된 점
Gemma 4는 단순히 규모가 더 커진 것뿐만 아니라, 각 매개변수별로 더 스마트해졌습니다. 주요 특징 몇 가지는 다음과 같습니다:
- 고급 추론 및 에이전트: 다단계 계획 수립, 수학, 코딩, 그리고 즉시 사용 가능한 자율 워크플로우.
- 다중 모드: 텍스트와 이미지를 기본적으로 처리하며, 소형 모델인 E2B 및 E4B에서는 오디오도 지원합니다. 문서 분석, 차트 인식, 필기체 OCR 기능이 모두 하나의 프롬프트로 작동합니다.
- 광범위한 컨텍스트: E2B/E4B 모델의 경우 128K 토큰, 26B MoE 및 31B 밀집 모델의 경우 무려 256K 토큰으로, 전체 코드베이스나 방대한 문서 묶음을 한 번에 처리하기에 충분한 규모입니다.
- 다국어 지원: 140개 이상의 언어로 훈련되었으며, 그중 수십 개 언어에 대해 강력한 기본 지원 기능을 제공합니다.
이 모델은 Hugging Face에서 사전 학습 및 지시어 튜닝 버전이 제공되며, Ollama, LM Studio, llama.cpp, vLLM, Transformers 등 이미 사용 중인 도구들과 즉시 연동됩니다.
소비자용 PC가 왜 젬마 4의 최적의 시장인가
Gemma 4는 로컬 추론을 최우선 목표로 설계되었으며, 수치적 결과도 이를 뒷받침합니다. NVIDIA와 Google은 RTX 그래픽 카드에 대한 초기 최적화를 위해 협력했으며, 최근 llama.cpp 프로젝트의 결과로 긴 컨텍스트 시나리오에서 KV 캐시 메모리 사용량이 약 40% 감소했습니다.
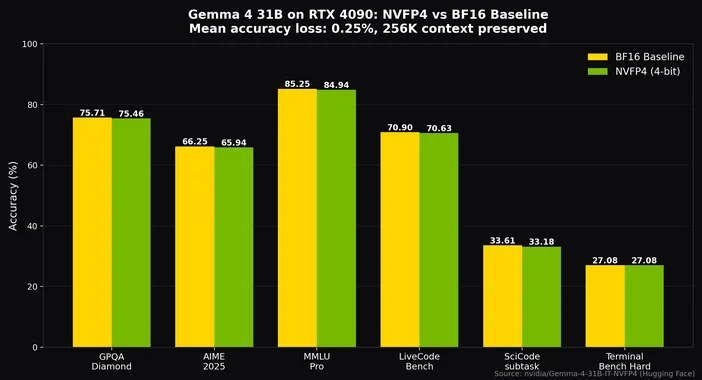
대부분의 빌드에서 최적의 성능을 발휘하는 Q4_K_M 양자화 방식을 사용하면, RTX 4090이나 3090과 같은 24GB 메모리 카드에 260억 MoE를 탑재하고도 8K 토큰 규모의 컨텍스트를 수용할 여유를 확보할 수 있으며, 여전히 초당 20토큰을 훌쩍 넘는 성능을 달성할 수 있습니다. NVIDIA의 NVFP4 양자화를 사용하면 310억 파라미터의 밀집 모델조차도 256K 컨텍스트를 완전히 유지하면서 정확도 손실을 약 0.25%만 감수하고 단일 RTX 4090에 탑재할 수 있습니다.
빠른 제작 가이드
E2B / E4B (엣지 및 저지연): 8GB 또는 12GB VRAM을 탑재한 RTX 3060이나 4060과 최신 Ryzen 5 또는 Core i5 프로세서면 충분합니다. 장시간 사용을 계획 중이라면 32GB DDR5 메모리와 소음이 적은 일체형 수냉 쿨러를 함께 구성하세요.
26B MoE / 31B dense (추론 및 다중 모달용): RTX 4090(이미 보유하고 있다면 3090), Ryzen 7 / Core i7 이상, 64GB DDR5, 모델 로딩을 위한 고속 Gen4 NVMe, 그리고 통풍이 잘 되는 케이스에 850W 이상의 전원 공급 장치를 갖추는 것을 목표로 하세요. CORSAIR iCUE LINK TITAN RX RGB 360mm AIO와 같은 제품을 사용하면 지속적인 추론 부하 하에서도 GPU와 CPU의 성능을 안정적으로 유지할 수 있습니다.

RTX 50 시리즈는 Gemma 4에 더 큰 규모의 작업과 더 빠른 추론 처리를 위한 여유를 제공합니다.
PC에서 빠르게 시작하기
1. Ollama 또는 LM Studio를 설치합니다.
2. Hugging Face에서 Gemma 4 모델을 가져옵니다(처음 사용하시는 분은 gemma4:e4b로 시작하고, VRAM 용량이 충분하다면 gemma4:31b를 사용하세요).
3. 추론 작업을 실행하면, RTX 40 시리즈에서 더 작은 모델의 경우 초당 50~100개 이상의 토큰을 처리할 수 있을 것으로 예상됩니다.
4. 다중 모드를 활용해 보세요: 이미지와 프롬프트를 함께 입력하여 스크린샷, 차트 또는 사진을 분석해 보게 하세요.
Gemma 4 온디바이스: 모바일 환경에서도 사용 가능
Gemma 4의 에지 컴퓨팅 기능은 스마트폰으로도 확장됩니다. 더 소형인 E2B 및 E4B 모델은 Arm CPU와 모바일 GPU를 기반으로 작동하며, 음성 인식, 이미지 분석, 기기 내 비서 기능 등을 클라우드 없이도 거의 지연 시간 없이 처리할 수 있습니다. 구글의 AI 에지 스택과 Android AICore를 통해 안드로이드 환경 전반에서 이를 활용할 수 있으며, iOS 개발자는 Metal을 통해 CPU와 GPU를 활용할 수 있습니다.
Gemma 4는 고성능 소비자용 PC가 단순한 게이밍용 시스템이 아니라 진정한 AI 워크스테이션임을 보여주는 가장 확실한 증거입니다. 공개된 가중치, 자유로운 라이선스, 최첨단 수준의 추론 능력, 그리고 단일 GPU에 실제로 수용 가능한 256K 컨텍스트 윈도우를 갖추고 있습니다. 이미 최신형 CORSAIR 시스템을 보유하고 있다면, 본격적인 로컬 AI 워크스테이션을 구축하는 데 거의 다 온 셈입니다. 새 시스템을 구성 중이라면, 24GB 그래픽 카드, 64GB DDR5 메모리, 그리고 지속적인 부하에도 흔들리지 않는 수냉 쿨링 시스템을 중심으로 계획을 세우세요.

Gemma를 로컬에서 실행하고 싶으신가요? CORSAIR AI Workstation 300을 만나보세요
Gemma 4(및 기타 오픈 소스 모델)를 자신의 하드웨어에서 완벽하게 구동할 수 있는 타협 없는 방법을 원한다면, CORSAIR AI Workstation 300이 바로 이를 위해 특별히 설계된 제품입니다. 이 시스템은 AMD Ryzen AI Max+ 395 프로세서와 Radeon 8060S iGPU를 탑재하고, 128GB LPDDR5X-8000 메모리 중 최대 96GB를 통합 VRAM으로 할당하여, 디스크 페이징 없이도 로컬에서 대용량 Gemma 변형을 로드하고 미세 조정할 수 있는 충분한 여유 공간을 제공합니다. 전용 50 TOPS NPU가 추론 속도를 가속화하며, 전체 시스템은 책상 위에 놓을 수 있는 4.4L 섀시에 모두 들어갑니다. 프라이버시, 낮은 지연 시간, 토큰당 비용 제로를 원하는 개발자와 연구원에게 이는 Gemma를 활용하는 최상의 방법 중 하나입니다.
기사의 제품
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.