HOW TO
Procesor a karta graficzna w lokalnej sztucznej inteligencji: co tak naprawdę przyspiesza działanie?
Ostatnia aktualizacja:
Jeśli korzystasz z lokalnych rozwiązań AI, pewnie spotkałeś się już z radą: „zaopatrz się w dobry procesor graficzny”. Ale co to właściwie oznacza? I czy procesor centralny naprawdę jest aż tak bezużyteczny? Odpowiedź nie jest tak prosta, jak „procesor graficzny dobry, procesor centralny zły”. Liczy się to, jak każdy z procesorów radzi sobie z obliczeniami niezbędnymi do wnioskowania AI oraz który z nich potrafi przesyłać dane wystarczająco szybko, by nadążyć za procesem.
Co tak naprawdę dzieje się podczas wnioskowania opartego na sztucznej inteligencji?
Podczas uruchamiania lokalnego modelu LLM lub modelu obrazowego sprzęt wykonuje w kółko jedną czynność: mnożenie macierzy. Model pobiera dane wejściowe, przekształca je na liczby, a następnie poddaje je miliardom operacji matematycznych w poszczególnych warstwach. Im szybciej sprzęt jest w stanie przetworzyć te operacje, tym szybciej otrzymujesz odpowiedź.
To jest proces wnioskowania, czyli generowanie wyników na podstawie wytrenowanego modelu. Nie trenujesz tu niczego. Po prostu przetwarzasz dane, krok po kroku, jeden token na raz.
W jaki sposób procesor obsługuje zadania związane ze sztuczną inteligencją
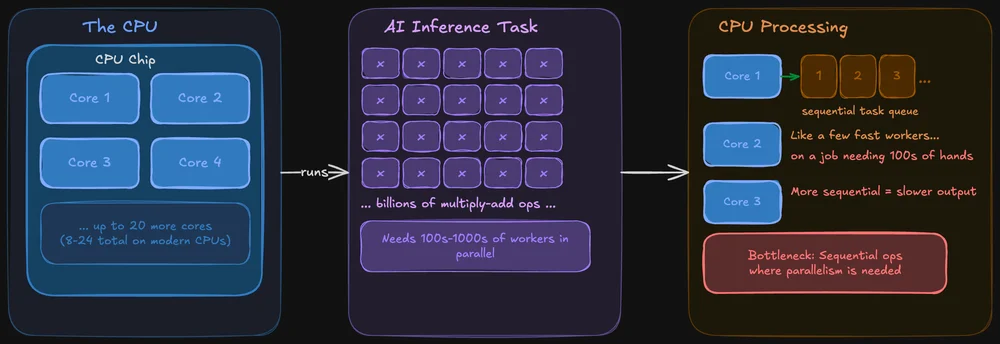
Procesor został zaprojektowany tak, by radzić sobie ze wszystkim. Obsługuje system operacyjny, karty przeglądarki, system plików, a także – oczywiście – może uruchamiać modele sztucznej inteligencji. Nowoczesne procesory mają wiele rdzeni (zazwyczaj od 8 do 24 w układach przeznaczonych dla użytkowników indywidualnych), a każdy z nich jest wydajny i elastyczny.
Problem polega na tym, że przetwarzanie danych przez sztuczną inteligencję wymaga jednoczesnego wykonywania tej samej operacji na ogromnych zbiorach danych. Procesor CPU jest w stanie to zrobić, ale operacje te przetwarza raczej sekwencyjnie. To tak, jakby kilku bardzo szybkich pracowników próbowało wykonać zadanie, które naprawdę wymaga setek rąk pracujących jednocześnie.
Nie oznacza to jednak, że procesory nie nadają się do lokalnej sztucznej inteligencji. Narzędzia takie jak llama.cpp są specjalnie zoptymalizowane pod kątem wnioskowania na procesorze, a jeśli model mieści się w pamięci RAM systemu, można go bez problemu uruchomić wyłącznie na procesorze. Będzie to po prostu działało wolniej – czasami zauważalnie, a czasami nie – w zależności od wielkości modelu.
Jak procesor graficzny radzi sobie z zadaniami związanymi ze sztuczną inteligencją
Karta graficzna została zaprojektowana z myślą o równoległości obliczeń. Podczas gdy procesor może mieć od 8 do 24 rdzeni, nowoczesna karta graficzna posiada tysiące mniejszych rdzeni, które mogą jednocześnie zajmować się fragmentami tego samego zadania. Dzięki temu karty graficzne doskonale sprawdzają się w wykonywaniu rozległych obliczeń matematycznych, od których zależą modele sztucznej inteligencji.
Co więcej, procesory graficzne dysponują własną pamięcią (VRAM) o znacznie większej przepustowości niż pamięć RAM systemu. Ta przepustowość ma ogromne znaczenie, ponieważ decyduje o tym, jak szybko dane mogą być przekazywane do tych tysięcy rdzeni. Większa przepustowość oznacza krótszy czas oczekiwania i więcej czasu na obliczenia.
W przypadku lokalnego wnioskowania w modelach LLM przewaga procesorów graficznych sprowadza się do dwóch czynników: mocy obliczeniowej w trybie równoległym oraz przepustowości pamięci. Oba te czynniki mają bezpośredni wpływ na liczbę tokenów na sekundę, jaką uzyskasz w wynikach.
Przepustowość pamięci
Oto coś, co zaskakuje większość ludzi: w przypadku lokalnego wnioskowania opartego na modelach LLM to nie sama moc obliczeniowa jest często czynnikiem ograniczającym, lecz przepustowość pamięci.
Podczas fazy wnioskowania wagi modelu muszą być odczytywane z pamięci dla każdego generowanego tokenu. Jeśli pamięć nie jest w stanie dostarczać danych do procesora wystarczająco szybko, to bez względu na to, ile masz rdzeni, będą one po prostu czekać bezczynnie.
Właśnie dlatego przepustowość pamięci VRAM ma tak duże znaczenie. Typowa konfiguracja pamięci systemowej DDR5 może zapewnić przepustowość na poziomie 50–90 GB/s. Natomiast nowoczesny procesor graficzny, taki jak RTX 5090, zapewnia przepustowość przekraczającą 1000 GB/s. To różnica rzędu wielkości.
Jeśli model mieści się w całości w pamięci VRAM, już z tego powodu wnioskowanie będzie prawie zawsze przebiegało szybciej na procesorze graficznym niż na procesorze centralnym.
Kiedy korzystanie wyłącznie z procesora ma sens
Karta graficzna nie zawsze jest najlepszym rozwiązaniem. Istnieją rzeczywiste sytuacje, w których lepszym wyborem jest wykorzystanie procesora:
- Używasz niewielkiego modelu (z maksymalnie 3 miliardami parametrów), w którym różnica w szybkości działania jest ledwo zauważalna.
- Nie masz kompatybilnej karty graficznej albo Twoja karta graficzna nie ma wystarczającej ilości pamięci VRAM, aby pomieścić ten model.
- Chcesz wykorzystać całą pamięć RAM komputera (która zazwyczaj jest znacznie większa niż pamięć VRAM), aby uruchomić większy model przy niższej prędkości.
- Korzystasz z laptopa lub komputera, w którym zużycie energii przez kartę graficzną lub jej wydzielanie ciepła stanowi problem.
Wydajność wnioskowania na procesorach znacznie wzrosła dzięki kwantyzacji (zmniejszeniu precyzji modelu w celu zmniejszenia zapotrzebowania na pamięć) oraz zoptymalizowanym pod tym kątem frameworkom. Kwantyzowany model o rozmiarze 7 miliardów parametrów działa na nowoczesnym procesorze z 32 GB pamięci RAM wystarczająco dobrze, by sprostać wielu zadaniom.


A co z odciążaniem?
Jeśli Twój model jest zbyt duży, by zmieścić się w pamięci VRAM, ale nadal chcesz korzystać z przyspieszenia GPU, większość lokalnych narzędzi do obsługi dużych modeli językowych (LLM) obsługuje częściowe odciążanie. Oznacza to, że niektóre warstwy modelu działają na procesorze graficznym, a pozostałe na procesorze centralnym.
To kwestia kompromisu: zyskujesz częściowo na szybkości pracy procesora graficznego, ale warstwy obciążające procesor stają się wąskim gardłem. Im więcej warstw zmieści się w pamięci VRAM, tym szybsze będzie działanie. A jeśli na procesorze graficznym znajdzie się tylko kilka warstw, obciążenie związane z przesyłaniem danych tam i z powrotem może sprawić, że działanie będzie wolniejsze niż w przypadku dedukcji wykonywanej wyłącznie na procesorze.
Ogólna zasada: jeśli nie jesteś w stanie zmieścić co najmniej połowy modelu w pamięci VRAM, prawdopodobnie lepiej będzie uruchomić go w całości na procesorze i oszczędzić sobie kłopotów.
NVIDIA kontra AMD w dziedzinie lokalnej sztucznej inteligencji
Obecnie firma NVIDIA dominuje na lokalnym rynku sztucznej inteligencji, głównie dzięki CUDA – własnej platformie obliczeniowej, na której opiera się niemal każde narzędzie AI. Jeśli korzystasz z LM Studio, Ollama lub llama.cpp w systemie Windows, procesory graficzne NVIDIA zapewnią Ci najpłynniejsze działanie przy minimalnej liczbie problemów technicznych.
AMD nadrabia zaległości. ROCm (odpowiedź AMD na CUDA) poczyniło znaczne postępy, a narzędzia takie jak Ollama wyraźnie obsługują procesory graficzne AMD Radeon w systemie Windows. Jednak ekosystem jest nadal bardziej ograniczony i w zależności od konkretnego procesora graficznego oraz używanego narzędzia mogą pojawić się problemy z kompatybilnością.
Jeśli zamierzasz kupić sprzęt specjalnie do lokalnej sztucznej inteligencji, obecnie bezpieczniejszym wyborem jest NVIDIA. Jeśli masz już kartę graficzną AMD, zdecydowanie warto spróbować – najpierw jednak sprawdź w dokumentacji swojego narzędzia, które modele są obsługiwane.

Gdzie sprawdzi się CORSAIR AI300
Jeśli Twoja obecna konfiguracja powoduje spowolnienia – czy to z powodu niewystarczającej ilości pamięci VRAM, niskiej przepustowości pamięci, czy też przegrzewania się systemu już po załadowaniu modelu 13B – to właśnie tego rodzaju problemy ma rozwiązywać obudowa CORSAIR AI Workstation 300 (AI300).
AI300 to kompaktowa stacja robocza zaprojektowana z myślą o realiach lokalnego przetwarzania wnioskowania opartego na sztucznej inteligencji:
- Konfiguracja z dużą ilością pamięci, umożliwiająca korzystanie z większych modeli i szerszych okien kontekstowych.
- Pamięć graficzna zaprojektowana z myślą o obciążeniach związanych ze sztuczną inteligencją (i odrobiną gier).
- Selektor wydajności na poziomie sprzętowym (Cichy / Zrównoważony / Maksymalny), dzięki czemu możesz priorytetowo traktować szybkość, gdy jej potrzebujesz, a ciszę, gdy nie jest to konieczne.
- Pakiet oprogramowania CORSAIR AI, który upraszcza konfigurację, dzięki czemu poświęcasz mniej czasu na ustawienia, a więcej na uruchamianie modeli.
Jeśli dotychczas próbowałeś wykorzystać lokalną sztuczną inteligencję w systemie, który nie został do tego zaprojektowany, AI300 oferuje urządzenie, w którym zarówno sprzęt, jak i oprogramowanie zostały stworzone specjalnie z myślą o tym zadaniu.

PRODUKTY W ARTYKULE
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.