HOW TO
Jak uruchomić lokalny model LLM w systemie Windows (bez konieczności korzystania z chmury)
Ostatnia aktualizacja:
Lokalne uruchamianie modelu LLM oznacza, że model znajduje się na Twoim komputerze, a Twoje polecenia (oraz wszelkie pliki, które mu przekazujesz) nie muszą opuszczać Twojego urządzenia. Żadnego konta w chmurze. Żadnych kluczy API. Żadnego „wyszkolimy model na Twoich danych… prawdopodobnie nie… może”. Tylko Ty, Twój komputer i model wykonujący każde zadanie, które mu zlecisz.
Czym właściwie jest „lokalny LLM”?
Lokalny model LLM to duży model językowy, który działa na Twoim komputerze, a nie na zdalnym serwerze. W praktyce oznacza to zazwyczaj, że pobierasz pliki modelu, wczytujesz je do lokalnej aplikacji i rozmawiasz z nimi tak samo, jak z asystentem w chmurze, z tą różnicą, że „serwerem” jest Twój komputer.
„Uruchamianie” modelu LLM lokalnie prawie zawsze oznacza generowanie odpowiedzi, a nie uczenie zupełnie nowego modelu od podstaw.
Po co uruchamiać lokalny model LLM?
Istnieje kilka powodów, dla których ludzie przechodzą z modeli LLM w chmurze na modele lokalne:
- Prywatność: Twoje polecenia pozostają na urządzeniu (o ile nie korzystasz z połączeń z chmurą).
- Korzystanie w trybie offline: Po pobraniu modelu można z niego korzystać bez połączenia z internetem.
- Bez limitów użytkowania: żadnych ograniczeń prędkości, żadnych komunikatów typu „wykorzystałeś dzisiejszy limit” i żadnych niespodziewanych rachunków.
- Wybór: Wybierz model, który Ci odpowiada – nie musisz wiązać się z abonamentem.
Oczywiście zamieniasz wygodę na kontrolę. Model chmurowy może wydawać się czymś w rodzaju magii; model lokalny może sprawiać wrażenie magii w zależności od posiadanego sprzętu.
Czego potrzeba, aby uruchomić lokalny model LLM?
W skrócie: procesor działa, karta graficzna pomaga, a pamięć ma znaczenie.
Oto, co faktycznie decyduje o tym, czy dobrze się bawisz:
- Pamięć RAM / VRAM: Większe modele wymagają więcej pamięci. Jeśli zabraknie pamięci, model nie zadziała.
- Pamięć: Modele mogą zajmować dużo miejsca. Niektóre biblioteki ostrzegają, że w zależności od pobranego modelu mogą one zajmować od kilkudziesięciu do kilkuset GB.
- Karta graficzna: Jeśli Twoja aplikacja obsługuje kartę graficzną, zazwyczaj zauważysz znaczny wzrost wydajności.
Nowoczesny komputer z systemem Windows 10/11 i co najmniej 32 GB pamięci RAM stanowi solidną podstawę do pracy z mniejszymi modelami lokalnymi, a większa ilość pamięci pozwala na wygodniejsze korzystanie z większych modeli.
Wybierz aplikację typu „lokalny serwer LLM”
LM Studio (przystępny interfejs graficzny)
LM Studio to aplikacja komputerowa, która umożliwia pobieranie modeli i prowadzenie z nimi rozmów w trybie lokalnym. Zawiera również programowalny lokalny interfejs API przeznaczony dla programistów.
Ollama (prosta interfejs CLI + lokalny interfejs API)
Ollama działa jako natywna aplikacja dla systemu Windows i oferuje obsługę wiersza poleceń oraz lokalny punkt końcowy API HTTP. Obsługuje ona bezpośrednio procesory graficzne NVIDIA i AMD Radeon w systemie Windows.
llama.cpp (dla majsterkowiczów)
Jeśli zależy Ci na maksymalnej kontroli, warto wypróbować llama.cpp – popularny silnik wnioskowania typu open source, który zawiera instrukcje kompilacji i obsługuje wiele backendów.

Zainstaluj i uruchom swój pierwszy model
Większe modele wymagają większej ilości pamięci RAM i/lub VRAM. Jeśli nie masz ich wystarczająco dużo, możesz spodziewać się spowolnienia działania, awarii lub ciągłego przenoszenia danych na dysk (co sprawia wrażenie, jakby komputer pracował w ślimaczym tempie).
Ogólna zasada dotycząca modeli z kwantyzacją typu int4:
- 8 GB pamięci RAM → około 3 miliardy modeli
- 16 GB pamięci RAM → około 7 miliardów modeli
- 32 GB pamięci RAM → około 13 miliardów modeli
A jeśli korzystasz z przyspieszenia graficznego:
- 6 GB pamięci VRAM → ~3 miliardy modeli
- 8 GB pamięci VRAM → ~7 miliardów modeli
- 12 GB pamięci VRAM → ~13 miliardów modeli
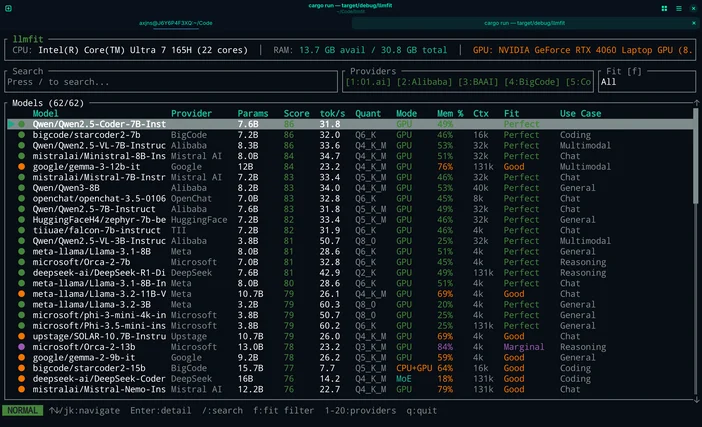
A jeśli nie chcesz zgadywać, możesz skorzystać z LLMfit, aby dopasować modele dokładnie do posiadanego sprzętu.
LLMfit to narzędzie uruchamiane w terminalu, które rozpoznaje procesor, pamięć RAM oraz kartę graficzną i pamięć VRAM, a następnie klasyfikuje modele pod względem dopasowania, przewidywanej szybkości działania, kontekstu i jakości, dzięki czemu jeszcze przed pobraniem pliku można sprawdzić, które z nich będą działać poprawnie.
Do czego się nadaje:
- Znalezienie modeli, które faktycznie mieszczą się w ramach limitów pamięci RAM/VRAM
- Sprawdzanie zalecanej kwantyzacji (aby nie przydzielić zbyt dużej ilości pamięci)
- Otrzymywanie listy najlepszych wyników zamiast przeglądania stron pełnych pesymistycznych wiadomości
Jak z tego korzystać w tym procesie:
- Uruchom program llmfit, aby przeskanować sprzęt systemowy
- Sprawdź najpopularniejsze propozycje / rekomendacje
- Wybierz rozmiar modelu pasujący do Twojej maszyny, a następnie pobierz go w LM Studio / Ollama / llama
Wszystko gotowe!
To wszystko. Wybierz środowisko uruchomieniowe, pobierz model dostosowany do Twojego sprzętu i zacznij wydawać polecenia! Wszystko pozostaje na Twoim komputerze. Nie potrzebujesz dyplomu z informatyki, abonamentu na usługi w chmurze ani weekendu spędzonego na rozwiązywaniu problemów. Cały proces trwa mniej więcej tyle samo, co instalacja gry. A gdy już wszystko zacznie działać, zyskasz prywatnego, działającego w trybie offline asystenta AI, który pracuje zgodnie z Twoimi wytycznymi.
Gdzie sprawdzi się CORSAIR AI300
Jeśli poważnie myślisz o uruchamianiu lokalnych modeli LLM w systemie Windows, zwłaszcza jeśli zależy Ci na większych modelach, szerszym oknie kontekstowym lub płynniejszym działaniu, to właśnie tutaj CORSAIR AI Workstation 300 (AI300) oraz pakiet oprogramowania CORSAIR AI pomogą Ci przejść na wyższy poziom.
W przypadku wnioskowania lokalnego najczęstszym wąskim gardłem są pamięć i przepustowość. Model AI300 został zaprojektowany z uwzględnieniem tej sytuacji:
- Kompaktowa stacja robocza stworzona z myślą o lokalnych procesach opartych na sztucznej inteligencji
- Konfiguracja z dużą ilością pamięci, która zapewnia wystarczającą przestrzeń na większe modele
- Zachowanie pamięci graficznej zaprojektowane z myślą o skalowalności w zastosowaniach związanych ze sztuczną inteligencją
- Selektor wydajności na poziomie sprzętowym (Cichy / Zrównoważony / Maksymalny), dzięki czemu możesz zdecydować, czy wolisz ciszę, czy szybkość

Czy do uruchomienia lokalnego modelu LLM w systemie Windows potrzebny jest procesor graficzny NVIDIA?
Nie. Niektóre narzędzia wyraźnie obsługują procesory graficzne AMD w systemie Windows; na przykład w dokumentacji Ollamy dla systemu Windows wspomniano o obsłudze zarówno procesorów graficznych NVIDIA, jak i AMD Radeon.
Czy mogę uruchomić lokalny model LLM całkowicie w trybie offline?
Tak, po pobraniu aplikacji i plików modeli. Pierwsza instalacja i pobieranie modeli zazwyczaj wymagają połączenia z internetem, ale po zainstalowaniu wszystkiego lokalnie procesy wnioskowania mogą przebiegać w trybie offline.
Czy lokalna sztuczna inteligencja jest z natury prywatna?
Może tak być, ale zależy to od Twojej konfiguracji. Wnioskowanie lokalne oznacza, że model działa na Twoim urządzeniu, ale niektóre aplikacje oferują opcjonalne połączenia z chmurą. Jeśli zależy Ci na tym, by „nie korzystać z chmury”, wyłącz integrację z chmurą i korzystaj wyłącznie z modeli lokalnych.
Dlaczego mój lokalny model działa tak wolno?
Zazwyczaj jedno z poniższych:
- Model jest zbyt duży w stosunku do dostępnej pamięci RAM/VRAM
- Korzystasz wyłącznie z procesora, mimo że dostępne jest przyspieszenie graficzne
- Wybrałeś długi kontekst i to pochłania pamięć
- Twoja pamięć jest pełna (tak, to ma znaczenie)
PRODUKTY W ARTYKULE
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.