BLOG
Gemma 4: Google's New Open Model and Why It Runs Best on Consumer PCs
Google just dropped Gemma 4, its most capable open-weights model family yet, and it's a big deal for anyone running AI locally on everyday hardware. Released March 31, 2026 under a fully permissive Apache 2.0 license, Gemma 4 is built to deliver frontier-level smarts on consumer GPUs and even laptops, no subscription needed.
The line-up spans four sizes: E2B (2.3B effective parameters), E4B (4.5B effective), a 26B Mixture-of-Experts variant with only 4B active parameters, and a 31B dense model. That gives you everything from edge-friendly to near-frontier in a single family, and all of it runs on the kind of PC builders are already putting together.

What Makes Gemma 4 Stand Out
Gemma 4 isn't just bigger, it's smarter per parameter. A few highlights:
- Advanced reasoning and agents: multi-step planning, math, coding, and autonomous workflows out of the box.
- Multimodal: handles text and images natively, with audio support on the smaller E2B and E4B variants. Document parsing, chart recognition, and handwriting OCR all work in a single prompt.
- Massive context: 128K tokens for E2B/E4B, and a full 256K tokens for the 26B MoE and 31B dense models, long enough to drop in a whole codebase or a stack of docs.
- Multilingual: trained on 140+ languages with strong out-of-box support for dozens of them.
It ships in pre-trained and instruction-tuned variants on Hugging Face, and works day one with the tools you're already using, Ollama, LM Studio, llama.cpp, vLLM, and Transformers.
Why Consumer PCs Are Gemma 4’s Sweet Spot
Gemma 4 was designed with local inference as a first-class target, and the numbers back it up. NVIDIA and Google collaborated on day-zero optimizations for RTX cards, and recent llama.cpp work has cut KV-cache memory usage by nearly 40% in long-context scenarios.
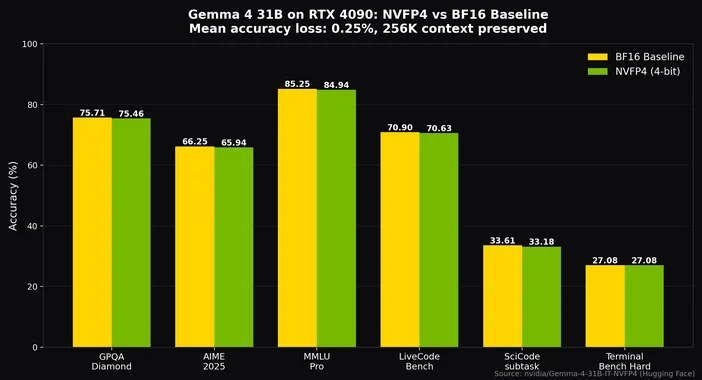
With Q4_K_M quantization, the sweet spot for most builds, you can fit the 26B MoE on a 24GB card like an RTX 4090 or 3090 with room for an 8K-token context, and still hit well over 20 tokens per second. With NVIDIA's NVFP4 quantization, even the 31B dense model fits on a single RTX 4090 with only ~0.25% accuracy loss while preserving the full 256K context.
A Quick Build Guide
E2B / E4B (edge and low-latency): An RTX 3060 or 4060 with 8, 12GB of VRAM and a modern Ryzen 5 or Core i5 is plenty. Pair it with 32GB of DDR5 and a quiet AIO if you plan on running long sessions.
26B MoE / 31B dense (pro reasoning and multimodal): Aim for an RTX 4090 (or 3090 if you already have one), a Ryzen 7 / Core i7 or better, 64GB of DDR5, a fast Gen4 NVMe for model loading, and an 850W+ PSU in a high-airflow case. Something like a CORSAIR iCUE LINK TITAN RX RGB 360mm AIO keeps the GPU and CPU happy under sustained inference loads.

The RTX 50 Series gives Gemma 4 even more headroom for larger contexts and faster inference.
Quick Start on Your PC
1. Install Ollama or LM Studio.
2. Pull a Gemma 4 model from Hugging Face (start with gemma4:e4b if you're new, or gemma4:31b if you've got the VRAM).
3. Run inference and expect 50, 100+ tokens/sec on RTX 40-series for the smaller variants.
4. Try the multimodal side: drop in an image plus a prompt and let it analyze a screenshot, a chart, or a photo.
Gemma 4 On-Device: It Goes Mobile Too
Gemma 4's edge focus extends to phones. The smaller E2B and E4B variants run on Arm CPUs and mobile GPUs with near-zero latency for speech recognition, image analysis, and on-device assistants, no cloud needed. Google's AI Edge stack and Android AICore make it accessible system-wide on Android, and iOS developers can target CPU and GPU via Metal.
Gemma 4 is the clearest sign yet that high-end consumer PCs aren't just gaming rigs, they're real AI workstations. Open weights, a permissive license, frontier-level reasoning, and a 256K context window that actually fits on a single GPU. If you've already got a modern CORSAIR build, you're most of the way to a proper local-AI workstation. If you're spec'ing one out, plan around a 24GB card, 64GB of DDR5, and a cooling loop that won't flinch under sustained load.

Want to run Gemma locally? Meet the CORSAIR AI Workstation 300
If you want a no-compromise way to run Gemma 4 (and other open models) entirely on your own hardware, the CORSAIR AI Workstation 300 is purpose-built for it. It pairs an AMD Ryzen AI Max+ 395 with the Radeon 8060S iGPU and up to 96GB of unified VRAM out of 128GB of LPDDR5X-8000 memory, giving you enough headroom to load and fine-tune large Gemma variants locally without paging to disk. A dedicated 50 TOPS NPU accelerates inference, and the whole system fits in a 4.4L chassis you can put on your desk. For developers and researchers who want privacy, low latency, and zero per-token costs, it's one of the best ways to put Gemma to work.
РЕГИСТРАЦИЯ ПРОДУКЦИИ
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.