BLOG
Gemma 4: Googles nya öppna modell och varför den fungerar bäst på vanliga datorer
Senast uppdaterad:
Google har just släppt Gemma 4, sin hittills mest kapabla modellserie med öppna vikter, och det är en stor nyhet för alla som kör AI lokalt på vanlig hårdvara. Gemma 4 släpptes den 31 mars 2026 under en helt fri Apache 2.0-licens och är utvecklad för att leverera avancerad intelligens på vanliga grafikkort och till och med bärbara datorer, utan att någon prenumeration krävs.
Sortimentet omfattar fyra storlekar: E2B (2,3 miljarder effektiva parametrar), E4B (4,5 miljarder effektiva parametrar), en Mixture-of-Experts-variant på 26 miljarder med endast 4 miljarder aktiva parametrar samt en kompakt modell på 31 miljarder. Det ger dig allt från kantanpassade till nästan gränsöverskridande modeller i en och samma serie, och alla kan köras på den typ av datorer som PC-byggare redan sätter ihop.

Vad som utmärker Gemma 4
Gemma 4 är inte bara större, den är också smartare i varje avseende. Några höjdpunkter:
- Avancerat resonemang och agenter: flerstegsplanering, matematik, kodning och autonoma arbetsflöden direkt ur lådan.
- Multimodal: hanterar text och bilder direkt, med stöd för ljud i de mindre modellerna E2B och E4B. Dokumentanalys, diagramigenkänning och OCR för handskrift fungerar alla i en och samma kommandofråga.
- Stort sammanhang: 128 000 token för E2B/E4B och hela 256 000 token för 26B MoE- och 31B-modellerna med hög densitet – tillräckligt mycket för att kunna lägga in en hel kodbas eller en hög med dokument.
- Flerspråkigt: tränat på över 140 språk med utmärkt stöd för dussintals av dem redan från start.
Den levereras i förtränade och instruktionsanpassade varianter på Hugging Face och fungerar direkt med de verktyg du redan använder: Ollama, LM Studio, llama.cpp, vLLM och Transformers.
Varför konsumentdatorer är Gemma 4:s starkaste område
Gemma 4 har utformats med lokal inferens som ett prioriterat mål, och siffrorna talar sitt tydliga språk. NVIDIA och Google har samarbetat kring optimeringar redan från start för RTX-kort, och det senaste arbetet med llama.cpp har minskat minnesanvändningen för KV-cachen med nästan 40 % i scenarier med långa kontexter.
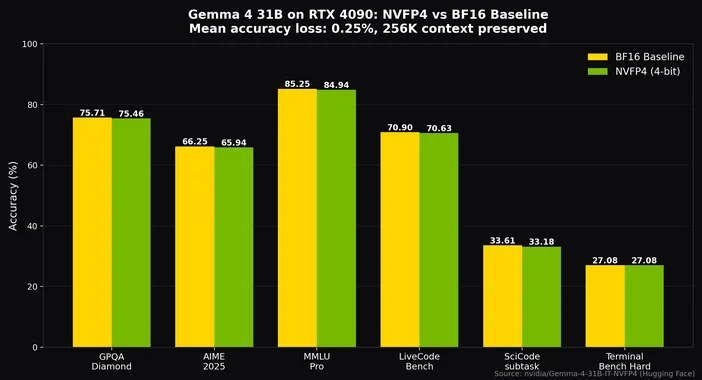
Med Q4_K_M-kvantisering, som är den optimala inställningen för de flesta konfigurationer, ryms 26B MoE på ett 24 GB-kort som ett RTX 4090 eller 3090 med utrymme för ett 8K-token-kontext, samtidigt som man fortfarande når långt över 20 token per sekund. Med NVIDIAs NVFP4-kvantisering får till och med den täta 31B-modellen plats på ett enda RTX 4090-kort med endast ~0,25 % noggrannhetsförlust samtidigt som hela 256K-kontexten bevaras.
En snabbguide till byggandet
E2B / E4B (edge och låg latens): Ett RTX 3060- eller 4060-grafikkort med 8 eller 12 GB VRAM och en modern Ryzen 5- eller Core i5-processor räcker gott och väl. Kombinera det med 32 GB DDR5-minne och ett tyst AIO-kylsystem om du planerar att köra långa sessioner.
26B MoE / 31B dense (för resonemang och multimodal): Satsa på ett RTX 4090 (eller 3090 om du redan har ett), en Ryzen 7 / Core i7 eller bättre, 64 GB DDR5, en snabb Gen4 NVMe för modellinläsning och ett nätaggregat på minst 850 W i ett chassi med hög luftgenomströmning. Något i stil med en CORSAIR iCUE LINK TITAN RX RGB 360 mm AIO håller GPU och CPU nöjda under ihållande inferensbelastningar.

RTX 50-serien ger Gemma 4 ännu mer prestandareserv för större sammanhang och snabbare inferens.
Snabbstart på din dator
1. Installera Ollama eller LM Studio.
2. Hämta en Gemma 4-modell från Hugging Face (börja med gemma4:e4b om du är nybörjare, eller gemma4:31b om du har tillräckligt med VRAM).
3. Kör inferens och räkna med 50–100+ token/sekund på RTX 40-serien för de mindre modellerna.
4. Prova den multimodala funktionen: ladda upp en bild tillsammans med en uppmaning och låt den analysera en skärmdump, ett diagram eller ett foto.
Gemma 4 On-Device: Nu även i mobilversion
Gemma 4:s fokus på edge-beräkning omfattar även mobiltelefoner. De mindre varianterna E2B och E4B drivs av Arm-processorer och mobila grafikkort med nästan obefintlig fördröjning för taligenkänning, bildanalys och enhetsbaserade assistenter – utan behov av molntjänster. Googles AI Edge-stack och Android AICore gör det tillgängligt i hela Android-systemet, och iOS-utvecklare kan utnyttja processorn och grafikkortet via Metal.
Gemma 4 är det tydligaste tecknet hittills på att avancerade konsumentdatorer inte bara är spelmaskiner, utan riktiga AI-arbetsstationer. Öppna vikter, en tillåtande licens, banbrytande resonemang och ett kontextfönster på 256K som faktiskt ryms på en enda GPU. Om du redan har en modern CORSAIR-dator är du redan på god väg mot en fullfjädrad lokal AI-arbetsstation. Om du håller på att sätta ihop en, planera för ett 24 GB-kort, 64 GB DDR5 och ett kylsystem som inte viker sig under kontinuerlig belastning.

Vill du köra Gemma lokalt? Upptäck CORSAIR AI Workstation 300
Om du vill ha ett kompromisslöst sätt att köra Gemma 4 (och andra öppna modeller) helt på din egen hårdvara är CORSAIR AI Workstation 300 specialbyggd för just detta. Den kombinerar en AMD Ryzen AI Max+ 395 med Radeon 8060S iGPU och upp till 96 GB enhetligt VRAM av 128 GB LPDDR5X-8000-minne, vilket ger dig tillräckligt med utrymme för att ladda och finjustera stora Gemma-varianter lokalt utan att behöva växla till disk. En dedikerad 50 TOPS NPU accelererar inferensen, och hela systemet ryms i ett 4,4-liters chassi som du kan placera på skrivbordet. För utvecklare och forskare som vill ha integritet, låg latens och noll kostnad per token är detta ett av de bästa sätten att sätta Gemma i arbete.
PRODUKTER I ARTIKEL
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.