Wenn Sie KI lokal betreiben, haben Sie wahrscheinlich schon den Ratschlag gehört: „Besorgen Sie sich eine gute GPU.“ Aber was bedeutet das eigentlich? Und ist Ihre CPU wirklich so nutzlos? Die Antwort ist nicht so einfach wie „GPU gut, CPU schlecht“. Entscheidend ist, wie die einzelnen Prozessoren die mathematischen Berechnungen hinter der KI-Inferenz bewältigen und welcher davon Daten schnell genug verarbeiten kann, um Schritt zu halten.
Was passiert eigentlich während der KI-Inferenz?
Wenn Sie ein lokales LLM- oder Bildmodell ausführen, führt Ihre Hardware immer wieder dieselbe Aufgabe aus: Matrixmultiplikation. Das Modell nimmt Ihre Eingabe entgegen, wandelt sie in Zahlen um und lässt diese Zahlen Milliarden von mathematischen Operationen durchlaufen, die über alle Schichten verteilt sind. Je schneller Ihre Hardware diese Operationen verarbeiten kann, desto schneller erhalten Sie eine Antwort.
Das ist Inferenz, also die Erzeugung von Ergebnissen anhand eines trainierten Modells. Du trainierst dabei nichts. Du führst lediglich die Berechnungen Schritt für Schritt durch, Token für Token.
Wie eine CPU KI-Aufgaben verarbeitet
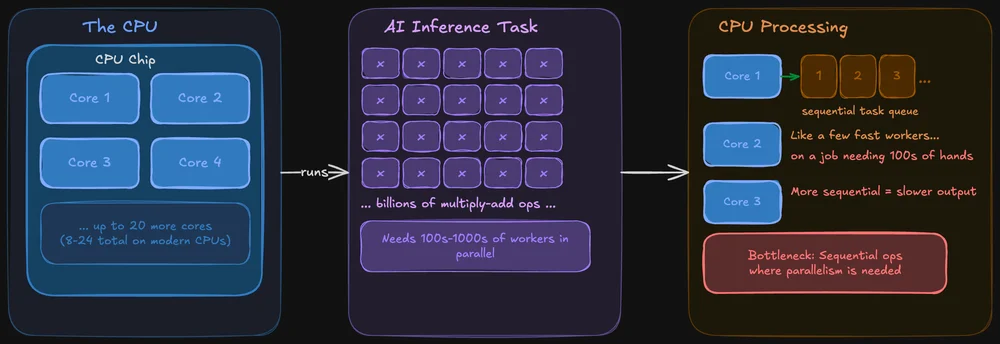
Eine CPU ist so konzipiert, dass sie in allen Bereichen gute Leistungen erbringt. Sie verwaltet Ihr Betriebssystem, Ihre Browser-Tabs und Ihr Dateisystem – und ja, sie kann auch KI-Modelle ausführen. Moderne CPUs verfügen über mehrere Kerne (bei Chips für Endverbraucher sind es in der Regel 8 bis 24), und jeder Kern ist leistungsstark und flexibel.
Das Problem: Bei der KI-Inferenz müssen dieselben Rechenoperationen gleichzeitig auf riesige Datenmengen angewendet werden. Eine CPU ist dazu zwar in der Lage, verarbeitet diese Operationen jedoch eher sequenziell. Das ist so, als hätte man nur wenige sehr schnelle Arbeiter, die eine Aufgabe bewältigen sollen, für die eigentlich Hunderte von Händen gleichzeitig nötig wären.
Dennoch sind CPUs für lokale KI keineswegs unbrauchbar. Tools wie llama.cpp sind speziell für die Inferenz auf der CPU optimiert, und wenn Ihr Modell in den Arbeitsspeicher des Systems passt, können Sie es durchaus allein auf der CPU ausführen. Je nach Modellgröße wird es dabei manchmal spürbar langsamer sein, manchmal aber auch nicht.
Wie eine GPU KI-Aufgaben verarbeitet
Eine GPU ist auf Parallelität ausgelegt. Während eine CPU über 8 bis 24 Kerne verfügt, hat eine moderne GPU Tausende kleinerer Kerne, die alle gleichzeitig an Teilen desselben Problems arbeiten können. Dadurch eignen sich GPUs besonders gut für die umfangreichen Berechnungen, auf die KI-Modelle angewiesen sind.
Darüber hinaus verfügen GPUs über einen eigenen Speicher (VRAM) mit einer deutlich höheren Bandbreite als der System-RAM. Diese Bandbreite ist von entscheidender Bedeutung, da sie bestimmt, wie schnell Daten an diese Tausenden von Kernen weitergeleitet werden können. Mehr Bandbreite bedeutet weniger Wartezeit und mehr Rechenzeit.
Speziell bei der lokalen LLM-Inferenz lässt sich der Vorteil der GPU auf zwei Faktoren zurückführen: parallele Rechenleistung und Speicherbandbreite. Beide Faktoren wirken sich direkt darauf aus, wie viele Token pro Sekunde in Ihrer Ausgabe erscheinen.
Speicherbandbreite
Das überrascht die meisten Menschen: Bei der lokalen LLM-Inferenz ist nicht die reine Rechenleistung der limitierende Faktor, sondern die Speicherbandbreite.
Während der Inferenz müssen die Modellgewichte für jedes einzelne generierte Token aus dem Speicher ausgelesen werden. Wenn Ihr Speicher die Daten nicht schnell genug an den Prozessor weiterleiten kann, spielt es keine Rolle, wie viele Kerne Sie haben – sie sitzen einfach nur da und warten.
Deshalb ist die VRAM-Bandbreite so wichtig. Ein typischer DDR5-Systemspeicher bietet eine Bandbreite von 50 bis 90 GB/s. Eine moderne GPU wie die RTX 5090 liefert hingegen über 1.000 GB/s. Das ist ein Unterschied um eine ganze Größenordnung.
Wenn Ihr Modell vollständig in den VRAM passt, läuft die Inferenz allein schon aus diesem Grund auf der GPU fast immer schneller als auf der CPU.
Wann der ausschließliche Einsatz der CPU tatsächlich sinnvoll ist
Die GPU ist nicht immer die Lösung. Es gibt konkrete Fälle, in denen die Ausführung auf der CPU die richtige Entscheidung ist:
- Sie verwenden ein kleines Modell (mit maximal 3B Parametern), bei dem der Geschwindigkeitsunterschied kaum wahrnehmbar ist.
- Du hast keine kompatible Grafikkarte oder deine Grafikkarte verfügt nicht über genügend VRAM, um das Modell darzustellen.
- Sie möchten den gesamten Arbeitsspeicher Ihres Systems (der in der Regel viel größer ist als der VRAM) nutzen, um ein größeres Modell mit geringerer Geschwindigkeit auszuführen.
- Sie nutzen einen Laptop oder einen Computer, bei dem die Leistungsaufnahme oder die Wärmeentwicklung der GPU ein Problem darstellt.
Die Inferenz auf der CPU hat sich dank Quantisierung (Reduzierung der Modellgenauigkeit, um weniger Speicher zu beanspruchen) und dafür optimierten Frameworks deutlich verbessert. Ein quantisiertes 7-Milliarden-Modell läuft auf einer modernen CPU mit 32 GB RAM für viele Aufgaben gut genug.


Wie sieht es mit der Auslagerung aus?
Wenn Ihr Modell zu groß für den VRAM ist, Sie aber dennoch eine GPU-Beschleunigung wünschen, unterstützen die meisten lokalen LLM-Tools eine teilweise Auslagerung. Das bedeutet, dass einige Schichten des Modells auf der GPU ausgeführt werden, während der Rest auf der CPU läuft.
Es ist ein Kompromiss: Man profitiert zwar teilweise von der höheren Geschwindigkeit der GPU, aber die CPU-gebundenen Schichten werden zum Engpass. Je mehr Schichten in den VRAM passen, desto schneller läuft das Ganze. Und wenn nur wenige Schichten auf der GPU landen, könnte der Aufwand für den Datenaustausch zwischen den Komponenten das Ganze sogar langsamer machen als eine reine CPU-Inferenz.
Als Faustregel gilt: Wenn nicht mindestens die Hälfte des Modells in den VRAM passt, ist es wahrscheinlich besser, es vollständig auf der CPU auszuführen und sich so den Aufwand zu ersparen.
NVIDIA vs. AMD bei lokaler KI
NVIDIA dominiert derzeit den lokalen KI-Markt, vor allem dank CUDA – dem firmeneigenen Rechenframework, auf dem fast jedes KI-Tool basiert. Wenn Sie LM Studio, Ollama oder llama.cpp unter Windows nutzen, sorgen NVIDIA-GPUs für ein reibungsloses Erlebnis mit minimalem Fehlerbehebungsaufwand.
AMD holt auf. ROCm (AMDs Antwort auf CUDA) hat echte Fortschritte gemacht, und Tools wie Ollama unterstützen AMD Radeon-GPUs unter Windows ausdrücklich. Das Ökosystem ist jedoch nach wie vor eingeschränkter, und je nach Ihrer spezifischen GPU und dem verwendeten Tool können Kompatibilitätsprobleme auftreten.
Wenn Sie speziell für lokale KI-Anwendungen einkaufen, ist NVIDIA derzeit die sicherere Wahl. Wenn Sie bereits eine AMD-GPU besitzen, lohnt es sich auf jeden Fall, es auszuprobieren – schauen Sie jedoch zunächst in der Dokumentation Ihres Tools nach, welche Modelle unterstützt werden.

Wo der CORSAIR AI300 zum Einsatz kommt
Wenn Ihre aktuelle Konfiguration Sie an ihre Grenzen bringt – sei es aufgrund von zu wenig VRAM, einer langsamen Speicherbandbreite oder einem System, das schon beim Laden eines 13B-Modells überhitzt –, dann ist dies genau die Art von Problem, für deren Lösung die CORSAIR AI Workstation 300 (AI300) entwickelt wurde.
Die AI300 ist eine kompakte Workstation, die speziell für die Anforderungen der lokalen KI-Inferenz entwickelt wurde:
- Konfiguration mit großem Arbeitsspeicher, die Platz für umfangreichere Modelle und größere Kontextfenster bietet.
- Grafikspeicher, der speziell für KI-Anwendungen (und ein bisschen Gaming) ausgelegt ist.
- Ein Leistungswähler auf Hardware-Ebene (Leise / Ausgewogen / Max), damit Sie bei Bedarf der Geschwindigkeit Vorrang geben und ansonsten auf leisen Betrieb umschalten können.
- Der CORSAIR AI Software Stack vereinfacht die Einrichtung, sodass Sie weniger Zeit mit der Konfiguration und mehr Zeit mit der Ausführung von Modellen verbringen.
Wenn Sie bisher versucht haben, lokale KI aus einem System herauszuholen, das nicht dafür ausgelegt war, bietet Ihnen der AI300 eine Maschine, bei der Hardware und Software tatsächlich speziell auf diese Anforderung zugeschnitten sind.

PRODUKTE IM ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.