Ein CUDA-Kern ist eine der winzigen Recheneinheiten in einer NVIDIA-GPU, die die Routineaufgaben für Grafik und parallele Berechnungen übernimmt. Jeder Kern befindet sich in einem größeren Block, der als Streaming-Multiprozessor (SM) bezeichnet wird, und auf modernen GeForce „Blackwell”-GPUs enthält jeder SM 128 CUDA-Kerne. Deshalb sehen Sie auf einer RTX 5090 eine Gesamtzahl von 21.760 CUDA-Kernen. Der Chip verfügt einfach über viele SMs, die jeweils mit diesen Kernen ausgestattet sind.
CUDA (die Parallelrechnerplattform von NVIDIA) ist die Softwareseite der Geschichte: Sie ermöglicht es Apps und Frameworks, massiv parallele Aufgaben wie Rendering, KI und Simulation effizient an diese Kerne zu senden.

Wie funktionieren CUDA-Kerne?
Stellen Sie sich eine GPU wie eine Fabrik vor, die für Massenaufträge ausgelegt ist. CUDA-Kerne verarbeiten Aufgaben in Warp-Gruppen von 32 Threads, die dieselbe Anweisung für unterschiedliche Daten ausführen (ein Modell, das NVIDIA als SIMT bezeichnet). Auf diese Weise können GPUs Tausende von Operationen gleichzeitig ausführen. Jeder SM verfügt über Scheduler, die viele Warps in Betrieb halten, um Speicherlatenzen zu verbergen und diese Kerne ausgelastet zu halten.
Ein nützliches mentales Bild:
- CUDA-Kern = ein einzelner Worker (führt arithmetische Operationen wie Additionen und Multiplikationen durch).
- SM = ein Shop Floor mit eigenen Schedulern, Caches, Spezialfunktions-Einheiten, Tensor Core(s) usw.
- GPU = die gesamte Fabrik, in der viele SMs parallel arbeiten.
CUDA-Kerne vs. CPU-Kerne (und andere GPU-Kerne)
- Keine CPU-Kerne: Ein CUDA-Kern ist eine einfachere Rechenbahn, die für den Durchsatz optimiert ist, und kein großer, auf Latenz abgestimmter Allzweck-CPU-Kern. GPUs skalieren, indem viele dieser kleinen Bahnen zusammenarbeiten. (Der CUDA-Programmierleitfaden erklärt dieses durchsatzorientierte Design.)
- Unterschied zu spezialisierten GPU-Kernen:
- Tensor Cores sind Matrix-Mathematik-Engines, die KI/ML und Funktionen wie DLSS beschleunigen.
- RT-Kerne beschleunigen das Raytracing (BVH-Durchlauf, Ray-/Triangle-Tests).
Diese entlasten bestimmte Aufgaben, sodass sich die CUDA-Kerne auf Shading/Berechnungen konzentrieren können.

Bildnachweis: NVIDIA
Bedeuten mehr CUDA-Kerne immer mehr Leistung?
Normalerweise schon, aber nicht allein. Die Architektur spielt eine große Rolle. Beispielsweise hat die Ampere-Generation von NVIDIA den FP32-Durchsatz pro SM im Vergleich zu Turing verdoppelt, sodass sich die Leistung „pro Kern“ zwischen den Generationen verändert hat. Ada hat auch die Caches (insbesondere L2) erheblich erweitert, was viele Workloads beschleunigt, ohne die Kernanzahl zu verändern. Kurz gesagt: Der Vergleich der CUDA-Kernanzahl verschiedener Generationen ist nicht aussagekräftig.
Weitere wichtige Einflussfaktoren:
- Taktfrequenzen und Leistungsreserven (wie schnell die Kerne laufen).
- Speicherbandbreite und Cache-Größen (Versorgung der Kerne).
- Verwendung von Tensor-/RT-Kernen (KI und Raytracing entlasten die CUDA-Kerne).
- Treiber und Software (wie gut eine App die GPU über CUDA nutzt).
Was machen CUDA-Kerne in der Praxis eigentlich?
- Gaming/Grafik: Sie führen Shader-Programme (Vertex, Pixel, Compute) im Hintergrund aus. RT-Kerne übernehmen die rechenintensiven Raytracing-Schritte, während CUDA-Kerne weiterhin einen Großteil der Shading- und Rechenaufgaben übernehmen.
- Erstellung und Simulation von Inhalten: Physik-Solver, Denoiser, Render-Kernel, Videoeffekte – viele davon wurden geschrieben, um die Vorteile des parallelen Modells von CUDA zu nutzen.
- KI/ML: Tensor-Operationen werden an Tensor-Kerne weitergeleitet, aber ein Großteil der Vor- und Nachbearbeitung sowie nicht matrixbezogene Aufgaben werden weiterhin auf CUDA-Kernen ausgeführt.
Wie viele CUDA-Kerne benötige ich?
Eine praktische Faustregel:
- Gaming mit hoher Bildrate (FPS) in 1080p–1440p: Betrachten Sie die gesamte GPU (Architektur, Taktfrequenzen, Speicher, RT-/Tensor-Funktionen) und nicht nur die Anzahl der Kerne. Benchmarks sind wichtiger als die reine Anzahl.
- 4K oder Heavy Raytracing: Sie profitieren von mehr SMs/CUDA-Kernen und starken RT/Tensor-Blöcken sowie Bandbreite und Cache.
- KI/Rechenleistung: Die Anzahl der Kerne ist hilfreich, aber häufig bestimmen die Tensor-Core-Fähigkeit, die VRAM-Größe und die Speicherbandbreite den Durchsatz.
Wenn Sie eine schnelle Überprüfung der Skalierbarkeit wünschen, listet RTX 5090 21.760 CUDA-Kerne auf und zeigt damit, wie NVIDIA die Kerne pro SM über viele SMs hinweg zählt. Aber auch hier gilt: Die Leistungssteigerungen resultieren aus dem Gesamtdesign und nicht allein aus der Anzahl.
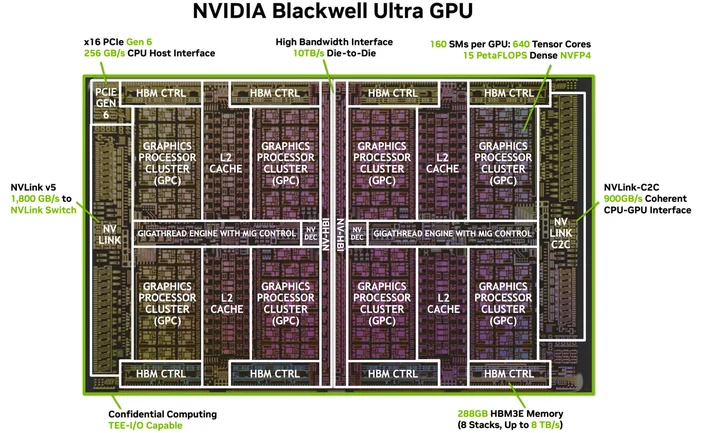
Bildnachweis: NVIDIA
Benötige ich spezielle Software oder Kabel? (Das „HDMI für 4K” von CUDA)
Sie benötigen kein spezielles Kabel, aber Sie benötigen die richtige Software-Stack. CUDA ist die Plattform von NVIDIA; Anwendungen nutzen sie über Treiber, Toolkits und Bibliotheken. Viele beliebte Anwendungen und Frameworks sind bereits so konzipiert, dass sie die CUDA-Beschleunigung nutzen, sobald Ihre NVIDIA-Treiber und (falls erforderlich) das CUDA-Toolkit installiert sind. Unterstützte Anwendungen nutzen sie einfach.
Welche GPUs unterstützen CUDA?
CUDA läuft auf CUDA-fähigen NVIDIA-GPUs aller Produktreihen (GeForce/RTX für Gaming und Kreativarbeit, professionelle RTX- und Rechenzentrums-GPUs). Der Programmierleitfaden weist darauf hin, dass das Modell für viele GPU-Generationen und SKUs skalierbar ist. NVIDIA führt eine Liste der CUDA-fähigen GPUs und ihrer Rechenleistung.
Ist ein CUDA-Kern dasselbe wie ein „Shader-Kern“?
Im GPU-Alltagssprachgebrauch beziehen sich „CUDA-Kerne” bei NVIDIA-GPUs auf die programmierbaren FP32/INT32-ALUs, die für Shading und allgemeine Berechnungen innerhalb jedes SM verwendet werden.
Warum unterscheiden sich die CUDA-Kernzahlen zwischen den verschiedenen Generationen so stark?
Weil sich Architekturen weiterentwickeln. Ampere hat die FP32-Datenpfade geändert (mehr Arbeit pro Takt) und Ada hat die Caches überarbeitet, sodass die Leistung nicht linear mit der Anzahl der Kerne skaliert.
Was ist nochmal eine Kette?
Eine Gruppe von 32 Threads, die synchron auf dem SM ausgeführt werden. Apps starten Tausende von Threads; die GPU plant sie als Warps, um die Hardware auszulasten.
Sind CUDA-Kerne hilfreich für KI?
Ja, aber die großen Beschleuniger für moderne KI sind Tensor-Kerne. CUDA-Kerne übernehmen nach wie vor viele damit verbundene Aufgaben in diesen Pipelines.
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.