BLOG
Gemma 4: Nowy otwarty model Google’a i dlaczego najlepiej działa na komputerach osobistych
Ostatnia aktualizacja:
Firma Google właśnie wprowadziła na rynek Gemma 4 – swoją dotychczas najwydajniejszą rodzinę modeli o otwartych parametrach – co stanowi przełom dla wszystkich, którzy korzystają z AI lokalnie na zwykłym sprzęcie. Wprowadzona 31 marca 2026 r. na całkowicie liberalnej licencji Apache 2.0, Gemma 4 została zaprojektowana tak, by zapewnić najnowocześniejsze możliwości przetwarzania na konsumenckich procesorach graficznych, a nawet laptopach, bez konieczności wykupywania abonamentu.
Oferta obejmuje cztery rozmiary: E2B (2,3 mld parametrów efektywnych), E4B (4,5 mld parametrów efektywnych), wersję 26B typu „Mixture-of-Experts” z zaledwie 4 mld aktywnych parametrów oraz gęsty model 31B. Dzięki temu w ramach jednej rodziny modeli otrzymujesz rozwiązania od tych przystosowanych do urządzeń brzegowych po modele zbliżone do najnowocześniejszych, a wszystkie z nich działają na komputerach PC, jakie obecnie montują entuzjaści.

Czym wyróżnia się Gemma 4
Gemma 4 jest nie tylko większa, ale także bardziej wydajna pod względem poszczególnych parametrów. Kilka najważniejszych cech:
- Zaawansowane procesy wnioskowania i agenci: wieloetapowe planowanie, matematyka, programowanie oraz gotowe do użycia autonomiczne procesy.
- Wielomedialny: obsługuje tekst i obrazy w trybie natywnym, a w mniejszych wersjach E2B i E4B oferuje również obsługę plików audio. Analiza dokumentów, rozpoznawanie wykresów i OCR pisma ręcznego działają w ramach jednego polecenia.
- Ogromny kontekst: 128 tys. tokenów dla modeli E2B/E4B oraz aż 256 tys. tokenów dla modeli 26B MoE i 31B – wystarczająco dużo, by zmieścić cały kod źródłowy lub stos dokumentów.
- Wielojęzyczny: przeszkolony w zakresie ponad 140 języków, z doskonałą obsługą kilkudziesięciu z nich już po instalacji.
Jest dostępny na platformie Hugging Face w wersjach wstępnie wytrenowanych i dostosowanych do konkretnych zadań oraz od samego początku współpracuje z narzędziami, z których już korzystasz, takimi jak Ollama, LM Studio, llama.cpp, vLLM i Transformers.
Dlaczego komputery osobiste są idealnym rynkiem dla Gemma 4
Gemma 4 została zaprojektowana z myślą o lokalnej inferencji jako priorytetowym celu, co potwierdzają dane liczbowe. Firmy NVIDIA i Google współpracowały nad optymalizacjami od samego początku dla kart RTX, a ostatnie prace nad biblioteką llama.cpp pozwoliły zmniejszyć zużycie pamięci pamięci podręcznej KV o prawie 40% w scenariuszach z długimi kontekstami.
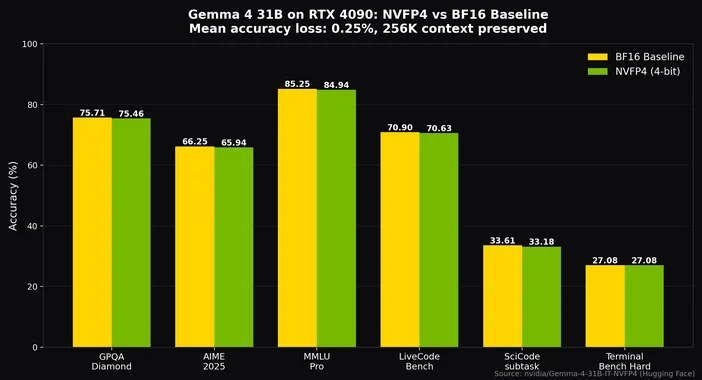
Dzięki kwantyzacji Q4_K_M, która stanowi optymalny wybór dla większości konfiguracji, model o rozmiarze 26 mld tokenów MoE zmieści się na karcie o pojemności 24 GB, takiej jak RTX 4090 lub 3090, pozostawiając miejsce na kontekst o rozmiarze 8 tys. tokenów, a mimo to pozwala osiągnąć wydajność znacznie przekraczającą 20 tokenów na sekundę. Dzięki kwantyzacji NVFP4 firmy NVIDIA nawet gęsty model 31B mieści się na jednej karcie RTX 4090 przy utracie dokładności wynoszącej zaledwie ~0,25%, zachowując jednocześnie pełny kontekst 256K.
Krótki przewodnik po montażu
E2B / E4B (rozwiązania brzegowe i o niskim opóźnieniu): Wystarczy karta graficzna RTX 3060 lub 4060 z 8 lub 12 GB pamięci VRAM oraz nowoczesny procesor Ryzen 5 lub Core i5. Jeśli planujesz długie sesje, warto dodać do tego 32 GB pamięci DDR5 i cichy zestaw AIO.
26B MoE / 31B (do wnioskowania i przetwarzania multimodalnego): Wybierz kartę graficzną RTX 4090 (lub 3090, jeśli już ją posiadasz), procesor Ryzen 7 / Core i7 lub lepszy, 64 GB pamięci DDR5, szybki dysk NVMe Gen4 do ładowania modeli oraz zasilacz o mocy co najmniej 850 W w obudowie zapewniającej dobry przepływ powietrza. Coś w rodzaju CORSAIR iCUE LINK TITAN RX RGB 360 mm AIO zapewnia optymalne działanie GPU i CPU przy długotrwałym obciążeniu wnioskowaniem.

Seria RTX 50 zapewnia platformie Gemma 4 jeszcze większy zapas mocy obliczeniowej, umożliwiający obsługę większych zbiorów danych i szybsze przetwarzanie wniosków.
Szybki start na komputerze
1. Zainstaluj program Ollama lub LM Studio.
2. Pobierz model Gemma 4 z serwisu Hugging Face (jeśli dopiero zaczynasz, wybierz wersję gemma4:e4b, a jeśli dysponujesz wystarczającą ilością pamięci VRAM – gemma4:31b).
3. Uruchom proces wnioskowania i spodziewaj się wydajności rzędu 50–100+ tokenów na sekundę na kartach graficznych z serii RTX 40 w przypadku mniejszych modeli.
4. Wypróbuj funkcję multimodalną: dodaj obraz i polecenie, a aplikacja przeanalizuje zrzut ekranu, wykres lub zdjęcie.
Gemma 4 na urządzeniu: teraz również w wersji mobilnej
Rozwiązania Gemma 4 do przetwarzania na urządzeniach końcowych obejmują również telefony. Mniejsze modele E2B i E4B wykorzystują procesory Arm i mobilne procesory graficzne, zapewniając niemal zerowe opóźnienia w rozpoznawaniu mowy, analizie obrazu i obsłudze asystentów lokalnych – bez konieczności korzystania z chmury. Dzięki pakietowi Google AI Edge i Android AICore rozwiązania te są dostępne w całym systemie Android, a programiści iOS mogą korzystać z procesorów i procesorów graficznych za pośrednictwem biblioteki Metal.
Gemma 4 to jak dotąd najwyraźniejszy dowód na to, że wysokiej klasy komputery konsumenckie to nie tylko maszyny do gier, ale prawdziwe stacje robocze do sztucznej inteligencji. Otwarte modele, liberalna licencja, rozumowanie na poziomie pionierskim oraz okno kontekstowe o rozmiarze 256 KB, które faktycznie mieści się na jednym procesorze graficznym. Jeśli masz już nowoczesny zestaw CORSAIR, jesteś już prawie gotowy do stworzenia prawdziwej lokalnej stacji roboczej do sztucznej inteligencji. Jeśli dopiero planujesz jej konfigurację, postaw na kartę graficzną o pojemności 24 GB, 64 GB pamięci DDR5 oraz układ chłodzenia, który nie zawiedzie nawet przy długotrwałym obciążeniu.

Chcesz uruchomić system Gemma lokalnie? Poznaj stację roboczą CORSAIR AI Workstation 300
Jeśli szukasz bezkompromisowego rozwiązania do uruchamiania Gemma 4 (i innych modeli otwartych) wyłącznie na własnym sprzęcie, stacja robocza CORSAIR AI Workstation 300 została stworzona właśnie z myślą o tym. Łączy procesor AMD Ryzen AI Max+ 395 z procesorem graficznym Radeon 8060S iGPU oraz do 96 GB zunifikowanej pamięci VRAM z 128 GB pamięci LPDDR5X-8000, zapewniając wystarczającą przestrzeń do lokalnego ładowania i precyzyjnego dostrajania dużych wariantów Gemma bez konieczności stronicowania na dysk. Dedykowany procesor NPU o wydajności 50 TOPS przyspiesza wnioskowanie, a cały system mieści się w obudowie o pojemności 4,4 l, którą można postawić na biurku. Dla programistów i badaczy, którzy cenią sobie prywatność, niskie opóźnienia i zerowe koszty za token, jest to jeden z najlepszych sposobów na wykorzystanie Gemma.
PRODUKTY W ARTYKULE
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.