Hvis du kører AI lokalt, har du sikkert set rådet: »Skaf dig en god GPU.« Men hvad betyder det egentlig? Og er din CPU virkelig så ubrugelig? Svaret er ikke så simpelt som »GPU god, CPU dårlig«. Det afgørende er, hvordan de to processorer håndterer de matematiske beregninger bag AI-inferens, og hvilken af dem der kan flytte data hurtigt nok til at følge med.
Hvad sker der egentlig under AI-inferens?
Når du kører en lokal LLM-model eller billedmodel, udfører din hardware én og samme opgave igen og igen: matrixmultiplikation. Modellen tager din indtastning, omdanner den til tal og sender disse tal gennem milliarder af matematiske operationer på tværs af sine lag. Jo hurtigere din hardware kan udføre disse operationer, jo hurtigere får du et svar.
Dette er en inferens, hvor der genereres et resultat ud fra en trænet model. Du træner ikke noget. Du kører blot beregningerne igennem, ét token ad gangen.
Hvordan en CPU håndterer AI-opgaver
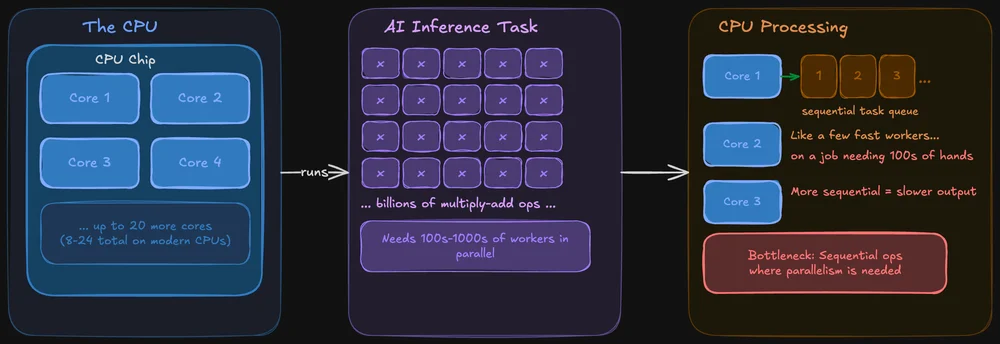
En CPU er designet til at klare det hele. Den styrer dit operativsystem, dine browserfaner, dit filsystem, og ja, den kan også køre AI-modeller. Moderne CPU'er har flere kerner (typisk 8–24 i chips til forbrugermarkedet), og hver kerne er kraftfuld og fleksibel.
Problemet er, at AI-inferens indebærer, at man udfører den samme operation på enorme datamængder samtidigt. En CPU kan godt klare det, men den behandler disse operationer mere sekventielt. Det er som at have nogle få meget hurtige medarbejdere, der skal klare en opgave, der egentlig kræver, at hundredvis af hænder arbejder på samme tid.
Når det er sagt, er CPU'er ikke helt uegnede til lokal AI. Værktøjer som llama.cpp er specifikt optimeret til CPU-inferens, og hvis din model kan være i systemets RAM, kan du sagtens køre den udelukkende på CPU'en. Det vil blot være langsommere – nogle gange mærkbart, andre gange ikke – afhængigt af modellens størrelse.
Sådan håndterer en GPU AI-opgaver
En GPU er bygget op omkring parallelisme. Mens en CPU typisk har 8–24 kerner, har en moderne GPU tusindvis af mindre kerner, der alle kan arbejde på forskellige dele af det samme problem på samme tid. Det gør GPU'er særdeles velegnede til den slags omfattende beregninger, som AI-modeller er afhængige af.
Derudover har GPU'er deres egen dedikerede hukommelse (VRAM) med en langt større båndbredde end systemets RAM. Den båndbredde er af afgørende betydning, da den bestemmer, hvor hurtigt data kan sendes til de tusindvis af kerner. Større båndbredde betyder kortere ventetid og mere tid til beregninger.
Når det specifikt drejer sig om lokal LLM-inferens, kan fordelene ved GPU'en koges ned til to ting: parallel processorkraft og hukommelsesbåndbredde. Begge dele har direkte indflydelse på, hvor mange tokens pr. sekund du vil se i dit output.
Hukommelsesbåndbredde
Her er noget, der overrasker de fleste: Når det gælder lokal LLM-inferens, er den rå regnekraft ofte ikke den begrænsende faktor. Det er hukommelsesbåndbredden.
Under inferens skal modellens vægte hentes fra hukommelsen for hvert eneste token, der genereres. Hvis din hukommelse ikke kan levere data til processoren hurtigt nok, er det ligegyldigt, hvor mange kerner du har – de står bare og venter.
Derfor er VRAM-båndbredden så vigtig. Et typisk DDR5-systemhukommelsessæt kan levere en båndbredde på 50–90 GB/s. Et moderne grafikkort som et RTX 5090 leverer over 1.000 GB/s. Det er en forskel på en hel størrelsesorden.
Hvis din model kan rummes fuldt ud i VRAM, vil inferens næsten altid være hurtigere på GPU end på CPU alene af denne grund.
Når det faktisk giver mening at bruge CPU alene
GPU er ikke altid løsningen. Der findes konkrete situationer, hvor det er bedst at køre på CPU:
- Du kører en lille model (3B-parametre eller færre), hvor hastighedsforskellen næsten ikke kan mærkes.
- Du har ikke et kompatibelt grafikkort, eller dit grafikkort har ikke nok VRAM til at kunne håndtere modellen.
- Du vil gerne udnytte hele systemets RAM (som normalt er meget større end VRAM) til at køre en større model ved lavere hastighed.
- Du bruger en bærbar computer eller et system, hvor GPU'ens strømforbrug eller varmeudvikling er et problem.
CPU-inferens er blevet markant bedre takket være kvantisering (hvor modelpræcisionen reduceres for at bruge mindre hukommelse) og rammer, der er optimeret til dette formål. En kvantiseret 7B-model på en moderne CPU med 32 GB RAM fungerer godt nok til mange opgaver.


Hvad med aflastning?
Hvis din model er for stor til VRAM, men du alligevel ønsker GPU-acceleration, understøtter de fleste lokale LLM-værktøjer delvis aflastning. Det betyder, at nogle lag i modellen kører på GPU'en, mens resten kører på CPU'en.
Det er et kompromis: Man får en del af GPU'ens hastighedsfordel, men de CPU-afhængige lag bliver en flaskehals. Jo flere lag man kan få plads til i VRAM, desto hurtigere bliver det. Og hvis kun en håndfuld lag ender på GPU'en, kan den ekstra belastning ved at flytte data frem og tilbage faktisk gøre det langsommere end ren CPU-inferens.
Tommelfingerreglen er: Hvis du ikke kan få plads til mindst halvdelen af modellen i VRAM, er det nok bedst at køre den udelukkende på CPU'en og spare dig selv for besværet.
NVIDIA kontra AMD inden for lokal AI
NVIDIA dominerer i øjeblikket det lokale AI-marked, hovedsageligt på grund af CUDA – deres egenudviklede beregningsramme, som næsten alle AI-værktøjer er bygget på. Hvis du bruger LM Studio, Ollama eller llama.cpp på Windows, vil NVIDIA-GPU'er give dig den mest problemfri oplevelse med færrest mulige problemer.
AMD er ved at indhente forspringet. ROCm (AMDs svar på CUDA) har gjort reelle fremskridt, og værktøjer som Ollama understøtter udtrykkeligt AMD Radeon-GPU'er på Windows. Men økosystemet er stadig mere begrænset, og du kan støde på kompatibilitetsproblemer afhængigt af din specifikke GPU og det værktøj, du bruger.
Hvis du specifikt køber udstyr til lokal AI, er NVIDIA det sikreste valg i øjeblikket. Hvis du allerede har et AMD-grafikkort, er det absolut værd at prøve – men tjek først dokumentationen til dit værktøj for at se, hvilke modeller der understøttes.

Hvor passer CORSAIR AI300 ind?
Hvis din nuværende opsætning skaber flaskehalse – hvad enten det skyldes for lidt VRAM, langsom hukommelsesbåndbredde eller et system, der overophedes, så snart du indlæser en 13B-model – er det netop den slags problemer, som CORSAIR AI Workstation 300 (AI300) er udviklet til at løse.
AI300 er en kompakt arbejdsstation, der er udviklet med udgangspunkt i de faktiske forhold ved lokal AI-inferens:
- Konfiguration med stor hukommelse, der giver plads til større modeller og større kontekstvinduer.
- Grafikhukommelse, der er designet til at kunne skaleres til AI-opgaver (og lidt gaming).
- En ydelsesvælger på hardwareniveau (Stille / Afbalanceret / Maks.) så du kan prioritere hastighed, når du har brug for det, og stilhed, når du ikke har.
- CORSAIR AI-softwarestakken, der gør opsætningen nemmere, så du bruger mindre tid på konfiguration og mere tid på at køre modeller.
Hvis du har forsøgt at få lokal AI til at fungere i et system, der ikke er designet til det, giver AI300 dig en maskine, hvor både hardware og software er udviklet specifikt med henblik på denne arbejdsopgave.

PRODUKTER I ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.