At køre en stor sprogmodel (LLM) på din egen pc lyder skræmmende, men det er overraskende tilgængeligt. En "lokal LLM" betyder simpelthen, at AI'en kører på din hardware uden cloud, uden konto, og dine data forbliver hos dig. Tænk på privat brainstorming, kodehjælp og dokument-spørgsmål og svar, alt sammen uden at sende noget online. Hvis det lyder godt, så lad os få dig fra nul til første prompt.
Hvilke værktøjer bruger vi?
Den mest begyndervenlige mulighed lige nu er Ollama, en gratis app, der downloader og kører et bredt udvalg af åbne modeller med en-linjekommandoer (den leveres nu med en Windows- og macOS-desktopapp, så du ikke behøver at bruge en terminal).
Hvis du foretrækker en mere visuel, alt-i-én-oplevelse, er LM Studio (også gratis) et andet godt valg til at opdage, køre og administrere lokale modeller. Open WebUI er en letvægts, selvhostet chatgrænseflade, der kan sidde oven på Ollama. Vælg en eller bland og match.


Hvad du skal bruge (hardware og operativsystem)
- Operativsystem: Windows 10/11, macOS eller Linux (vi viser eksempler på Windows nedenfor).
- Hukommelse og lagerplads: 16–32 GB RAM er passende til modeller med 7–13B-parametre; mere RAM hjælper med større kontekster. Hold flere GB ledig plads på en SSD til modeller og caches.
- GPU (valgfrit, men nyttigt): En moderne GPU gør tingene hurtigere og giver dig mulighed for at køre større modeller. På Windows understøtter Ollama GPU-acceleration og udgiver AMD-optimerede builds.
- Bemærkning om AMD integreret grafik (APU'er): Nye Ryzen AI Max+ systemer kan dele systemhukommelse som "variabel grafikhukommelse" og dermed give iGPU'en adgang til op til 96 GB VRAM med den rette konfiguration – hvilket er nyttigt for større modeller i hjemmet.
Hurtig start (Windows): Den hurtigste vej til din første prompt
- Installer Ollama
- Download Windows-installationsprogrammet fra Ollama, eller installer via Winget: "winget install --id Ollama.Ollama"
Efter installationen har du både Ollama-appen (GUI) og kommandolinjeværktøjet.
- Start og verificer
- Åbn Ollama-skrivebordsappen og log ind, hvis du bliver bedt om det (ingen cloud kræves til lokal brug).
- Eller verificer CLI: "ollama --version". (Du vil se et versionsnummer.)
- Træk en startmodel
- I appen kan du gennemse og downloade en model. Eller i en terminal: "ollama run llama3:8b
- "Dette vil downloade modellen og føre dig til en prompt – skriv et spørgsmål og start. Du kan gennemse mange modeller (Gemma, Llama, Qwen, OLMo og flere) i Ollama Library.
- (Valgfrit) Aktivér GPU-acceleration
- Hold dine grafikkortdrivere opdaterede. Ollama leverer Windows-builds med AMD-acceleration, og AMD dokumenterer DirectML/ROCm-stier til LLM'er på Radeon. I Ollama-appen skal du kontrollere, at GPU'en er registreret (eller overvåge GPU-forbruget i Task Manager under genereringen).
Hvilken model skal du prøve først?
- "Lille og hurtig": gemma3:1b eller llama3:8b er gode til hurtige svar og lavtydende hardware.
- "Balanceret": 7B–13B-modeller (f.eks. olmo2:7b, llama3:8b instruct) er solide til generel brug.
- "Større hjerner": 20B+ modeller (f.eks. gpt-oss:20b, større Llama-varianter) kræver mere RAM/VRAM og tålmodighed, men udmærker sig ved sværere opgaver. Du kan hente enhver af disse direkte i appen eller via ollama run <model>.
Tips til optimering af din lokale LLM
- Kontekstlængde: Større er ikke altid bedre. Store kontekster (f.eks. 32k-64k tokens) kan gøre genereringen meget langsommere. Start med 4k–8k, og øg kun, når det er nødvendigt.
- Kvantisering: De fleste app-leverede modeller er allerede kvantiseret for dig, hvilket er praktisk, når du skal tilpasse større modeller til begrænset VRAM.
- Opbevaring: Opbevar modellerne på en SSD; HDD'er vil føles langsomme.
- Drivere: Opdater GPU-drivere og appen regelmæssigt Lokal AI udvikler sig hurtigt.
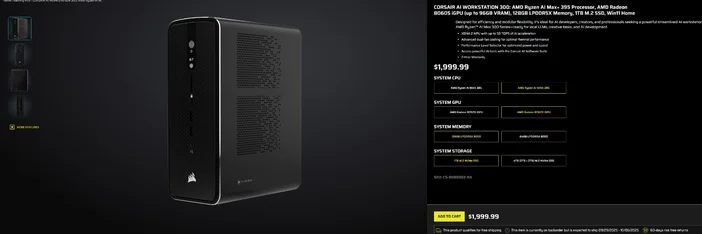
Brug af CORSAIR AI WORKSTATION 300
Hvis du hellere vil springe den stykkevise samling over og ønsker en kompakt, støjsvag desktop, der er klar til lokale LLM'er lige fra start, er CORSAIR AI WORKSTATION 300 opfylder mange krav for kreative og udviklere:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (op til 96 GB VRAM), XDNA 2 NPU op til 50 TOPS
- Hukommelse og lagerplads: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB+2 TB)
- OS: Windows 11 Home
- Design: 4,4 liters chassis i lille format med dobbelt blæserkøling og en ydeevnevalgsfunktion
Den "op til 96 GB VRAM" på Radeon iGPU passer særligt godt sammen med Windows-værktøjer, der kan allokere stor delt hukommelse til GPU'en, hvilket er praktisk til større lokale modeller og længere kontekster, når du har brug for dem. Det er en ren, kompakt vej til lokal AI-udvikling uden at gå på kompromis med kapaciteten.
Ofte stillede spørgsmål
Har jeg brug for en dedikeret GPU for at køre en lokal LLM?
Nej. Du kan køre mindre modeller på systemer, der kun har CPU, men responsen vil være langsommere. En moderne GPU eller en avanceret APU med stor delt hukommelse forbedrer hastigheden og giver dig mulighed for at øge modelstørrelsen.
Er dette privat?
Ja. Med lokale værktøjer som Ollama eller LM Studio forbliver prompts og data som standard på din maskine. (Integrationer, du tilføjer, kan opføre sig forskelligt, så tjek altid indstillingerne.)
Hvor finder jeg modeller?
Ollama Library viser populære, opdaterede muligheder (Llama, Gemma, Qwen, OLMo og flere). Hver modelside viser størrelser og eksempelkommandoer.
Kan CORSAIR AI WORKSTATION 300 håndtere store modeller?
Den er designet til lokale LLM'er med 128 GB hukommelse og en iGPU, der kan få adgang til op til 96 GB VRAM, hvilket giver fremragende headroom til avancerede lokale arbejdsbelastninger og lange kontekster, især da AMD's Windows-drivere udvider understøttelsen til store allokeringer. Den faktiske gennemstrømning afhænger af modelstørrelse, kvantisering og indstillinger.
PRODUKTER I ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.