HOW TO
CPU versus GPU voor lokale AI: wat zorgt er nu eigenlijk voor dat het sneller gaat?
Laatst bijgewerkt:
Als je AI lokaal gebruikt, heb je vast wel eens het advies gehoord: „Zorg voor een goede GPU.“ Maar wat houdt dat eigenlijk in? En is je CPU dan echt zo nutteloos? Het antwoord is niet zo simpel als „GPU goed, CPU slecht“. Het gaat erom hoe elke processor de rekenkundige bewerkingen achter AI-inferentie verwerkt en welke processor gegevens snel genoeg kan verwerken om bij te blijven.
Wat gebeurt er eigenlijk tijdens AI-inferentie?
Wanneer je een lokaal LLM- of beeldmodel uitvoert, doet je hardware steeds weer hetzelfde: matrixvermenigvuldiging. Het model neemt je invoer, zet deze om in getallen en voert met die getallen miljarden wiskundige bewerkingen uit in de verschillende lagen. Hoe sneller je hardware die bewerkingen kan verwerken, hoe sneller je een reactie krijgt.
Dit is inferentie: het genereren van output op basis van een getraind model. Je traint hier niets. Je voert gewoon de berekeningen uit, token voor token.
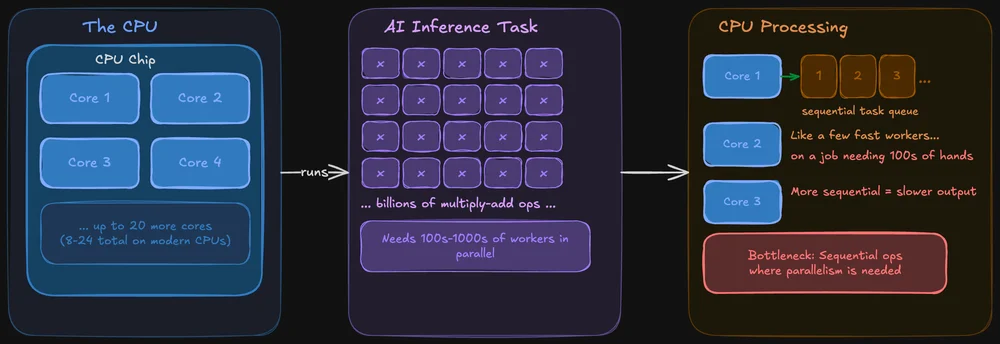
Hoe een CPU AI-taken verwerkt
Een CPU is ontworpen om overal goed in te zijn. Hij zorgt voor je besturingssysteem, je browsertabbladen, je bestandssysteem, en ja, hij kan ook AI-modellen draaien. Moderne CPU’s hebben meerdere kernen (meestal 8 tot 24 bij chips voor consumenten), en elke kern is krachtig en flexibel.
Het probleem: bij AI-inferentie moet dezelfde bewerking gelijktijdig op enorme hoeveelheden gegevens worden toegepast. Een CPU kan dit wel, maar verwerkt die bewerkingen meer achtereenvolgens. Het is alsof je een paar zeer snelle werknemers hebt die een klus moeten klaren waarvoor eigenlijk honderden handen tegelijk nodig zijn.
Dat gezegd hebbende, zijn CPU’s niet ongeschikt voor lokale AI. Tools zoals llama.cpp zijn specifiek geoptimaliseerd voor inferentie op de CPU, en als je model in het systeem-RAM past, kun je het prima alleen op de CPU draaien. Het zal alleen soms merkbaar langzamer zijn, en soms niet, afhankelijk van de grootte van het model.
Hoe een GPU AI-taken verwerkt
Een GPU is ontworpen met het oog op parallellisme. Waar een CPU 8 tot 24 kernen heeft, beschikt een moderne GPU over duizenden kleinere kernen die allemaal tegelijkertijd aan delen van hetzelfde probleem kunnen werken. Hierdoor zijn GPU’s buitengewoon geschikt voor het soort rekenintensieve taken waar AI-modellen van afhankelijk zijn.
Bovendien beschikken GPU’s over hun eigen speciale geheugen (VRAM) met een veel grotere bandbreedte dan het systeem-RAM. Die bandbreedte is van groot belang: zij bepaalt hoe snel gegevens naar die duizenden kernen kunnen worden gestuurd. Meer bandbreedte betekent minder wachttijd en meer rekenkracht.
Specifiek voor lokale LLM-inferentie komt het voordeel van de GPU neer op twee zaken: parallelle rekenkracht en geheugenbandbreedte. Beide factoren hebben een directe invloed op het aantal tokens per seconde dat je in je uitvoer ziet.
Geheugenbandbreedte
Dit zal de meeste mensen verbazen: bij lokale LLM-inferentie is ruwe rekenkracht vaak niet de beperkende factor. Dat is de geheugenbandbreedte wel.
Tijdens de inferentie moeten de modelgewichten voor elk gegenereerd token uit het geheugen worden opgehaald. Als je geheugen de gegevens niet snel genoeg naar de processor kan sturen, maakt het niet uit hoeveel cores je hebt: ze zitten daar gewoon te wachten.
Daarom is de bandbreedte van het VRAM zo belangrijk. Een standaard DDR5-systeemgeheugen biedt doorgaans een bandbreedte van 50 tot 90 GB/s. Een moderne GPU zoals een RTX 5090 biedt daarentegen meer dan 1.000 GB/s. Dat is een verschil van een hele orde van grootte.
Als je model volledig in het VRAM past, zal de inferentie alleen al om die reden bijna altijd sneller verlopen op de GPU dan op de CPU.
Wanneer het gebruik van alleen de CPU echt zinvol is
Een GPU is niet altijd de oplossing. Er zijn situaties waarin het gebruik van de CPU de juiste keuze is:
- Je gebruikt een klein model (met maximaal 3 miljard parameters) waarbij het verschil in snelheid nauwelijks merkbaar is.
- Je hebt geen compatibele grafische kaart, of je grafische kaart heeft onvoldoende VRAM om het model te laden.
- Je wilt je volledige systeem-RAM (dat meestal veel groter is dan het VRAM) gebruiken om een groter model op een lagere snelheid te draaien.
- Je werkt op een laptop of computer waarbij het stroomverbruik of de warmteontwikkeling van de grafische kaart een punt van zorg is.
De prestaties van CPU-inferentie zijn aanzienlijk verbeterd dankzij kwantisering (het verminderen van de precisie van het model om minder geheugen te gebruiken) en daarvoor geoptimaliseerde frameworks. Een gekwantiseerd model van 7 miljard parameters draait op een moderne CPU met 32 GB RAM goed genoeg voor veel taken.


Hoe zit het met het uitbesteden?
Als je model te groot is voor het VRAM, maar je toch gebruik wilt maken van GPU-versnelling, ondersteunen de meeste lokale LLM-tools gedeeltelijke offloading. Dit houdt in dat sommige lagen van het model op de GPU worden uitgevoerd, terwijl de rest op de CPU draait.
Het is een afweging: je profiteert gedeeltelijk van de snelheid van de GPU, maar de CPU-gebonden lagen vormen dan een bottleneck. Hoe meer lagen je in het VRAM kunt plaatsen, hoe sneller het gaat. En als er uiteindelijk maar een handvol lagen op de GPU terechtkomen, kan de overhead van het heen-en-weer verplaatsen van gegevens het proces zelfs langzamer maken dan pure CPU-inferentie.
De vuistregel: als je niet minstens de helft van het model in het VRAM kunt laden, kun je het beter volledig op de CPU draaien en jezelf de rompslomp besparen.
NVIDIA versus AMD voor lokale AI
NVIDIA domineert momenteel de lokale AI-markt, vooral dankzij CUDA. Dit is hun eigen rekenframework waarop vrijwel elke AI-tool is gebaseerd. Als je LM Studio, Ollama of llama.cpp op Windows gebruikt, zorgen NVIDIA-GPU’s voor de soepelste ervaring met de minste problemen.
AMD is bezig met een inhaalslag. ROCm (AMD’s antwoord op CUDA) heeft flinke vooruitgang geboekt, en tools zoals Ollama bieden expliciete ondersteuning voor AMD Radeon-GPU’s op Windows. Maar het ecosysteem is nog steeds beperkter, en afhankelijk van je specifieke GPU en de tool die je gebruikt, kun je te maken krijgen met compatibiliteitsproblemen.
Als je specifiek voor lokale AI koopt, is NVIDIA op dit moment de veiligere keuze. Als je al een AMD-GPU hebt, is het zeker de moeite waard om het te proberen; kijk alleen eerst even in de documentatie van je tool welke modellen worden ondersteund.

Waar de CORSAIR AI300 past
Als je huidige opstelling voor knelpunten zorgt – of het nu gaat om te weinig VRAM, een trage geheugenbandbreedte of een systeem dat oververhit raakt zodra je een 13B-model laadt – dan is dit precies het soort probleem waarvoor de CORSAIR AI Workstation 300 (AI300) is ontworpen.
De AI300 is een compact werkstation dat is ontworpen met het oog op de praktijk van lokale AI-inferentie:
- Configuratie met veel geheugen, geschikt voor grotere modellen en grotere contextvensters.
- Grafisch geheugen dat is ontworpen om mee te groeien met AI-werkbelastingen (en een beetje gamen).
- Een prestatieschakelaar op hardwareniveau (Stil / Gebalanceerd / Max) zodat je de voorkeur kunt geven aan snelheid wanneer dat nodig is en aan stilte wanneer dat niet het geval is.
- De CORSAIR AI-softwarestack, die de installatie vereenvoudigt, zodat u minder tijd kwijt bent aan het configureren en meer tijd hebt om modellen uit te voeren.
Als u tot nu toe hebt geprobeerd om lokale AI te gebruiken in een systeem dat daar niet voor is ontworpen, biedt AI300 u een machine waarbij de hardware en software daadwerkelijk zijn afgestemd op die specifieke taak.

PRODUCTEN IN ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.