Als je een LLM lokaal draait, staat het model op je pc en hoeven je prompts (en eventuele bestanden die je invoert) je computer niet te verlaten. Geen cloudaccount. Geen API-sleutels. Geen „we trainen het model met jouw gegevens… waarschijnlijk niet… misschien.“ Alleen jij, je pc en een model dat elke taak uitvoert die je het geeft.
Wat is een „lokale LLM“ precies?
Een lokaal LLM is een groot taalmodel dat op je computer draait in plaats van op een externe server. In de praktijk betekent dit meestal dat je modelbestanden downloadt, deze in een lokale app laadt en ermee chat zoals je met een cloudassistent zou chatten, met dit verschil dat de ‘server’ je pc is.
Een LLM lokaal ‘draaien’ betekent bijna altijd dat er inferentie plaatsvindt (het genereren van antwoorden), en niet dat er een geheel nieuw model vanaf nul wordt getraind.
Waarom een lokale LLM draaien?
Er zijn een aantal redenen waarom mensen overstappen van cloud-LLM’s naar lokale LLM’s:
- Privacy: Je invoer blijft op je apparaat staan (zolang je geen cloudverbindingen gebruikt).
- Offline gebruik: zodra het model is gedownload, kun je het zonder internet gebruiken.
- Geen gebruikslimieten: geen snelheidsbeperkingen, geen meldingen als „je dagelijkse limiet is bereikt“ en geen onverwachte rekeningen.
- Keuzevrijheid: Kies het model dat je wilt; je zit niet vast aan een abonnement.
Natuurlijk ruil je gemak in voor controle. Een cloudmodel kan aanvoelen als magie; een lokaal model kan aanvoelen als magie, afhankelijk van je hardware.
Wat heb je nodig om een lokale LLM te draaien?
Kort gezegd: de CPU doet zijn werk, de GPU helpt een handje, en het geheugen is van groot belang.
Dit zijn de factoren die er daadwerkelijk toe doen of je een leuke tijd zult hebben:
- RAM / VRAM: Grotere modellen hebben meer geheugen nodig. Als het geheugen opraakt, zal het model niet meer werken.
- Opslagruimte: Modellen kunnen groot zijn. Sommige bibliotheken waarschuwen dat de opslagruimte voor modellen kan oplopen tot tientallen of zelfs honderden GB, afhankelijk van het model dat je downloadt.
- GPU: Als je app je GPU ondersteunt, zul je meestal een flinke snelheidswinst merken.
Een moderne Windows 10/11-computer met minimaal 32 GB RAM vormt een solide basis voor kleinere lokale modellen, en met meer geheugen kun je grotere modellen soepeler uitvoeren.
Kies een app voor het uitvoeren van LLM’s
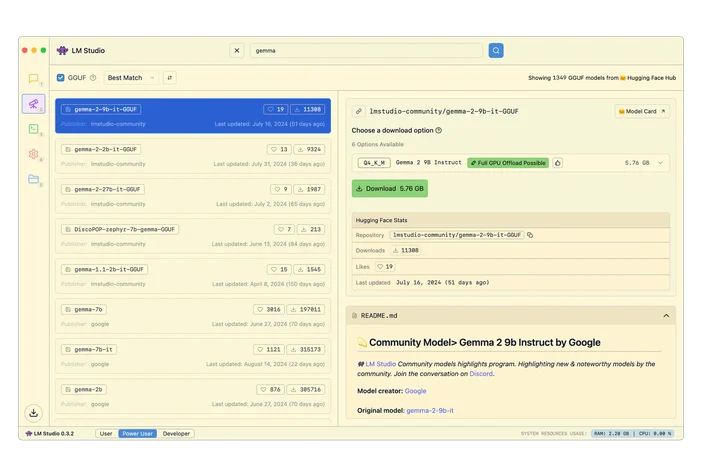
LM Studio (gebruiksvriendelijke gebruikersinterface)
LM Studio is een desktop-app waarmee je modellen kunt downloaden en lokaal met hen kunt chatten. De app bevat ook een programmeerbare lokale API voor ontwikkelaars.
Ollama (eenvoudige opdrachtregelinterface + lokale API)
Ollama draait als een native Windows-app en biedt je een workflow via de opdrachtregel en een lokaal HTTP-API-eindpunt. Het biedt expliciete ondersteuning voor NVIDIA- en AMD Radeon-GPU’s op Windows.
llama.cpp (voor knutselaars)
Als je maximale controle wilt, is llama.cpp een populaire open-source inferentie-engine met bouwinstructies en meerdere backends.

Installeer en voer je eerste model uit
Grotere modellen hebben meer RAM en/of VRAM nodig. Als je daar niet genoeg van hebt, krijg je te maken met trage prestaties, crashes of voortdurend wisselen naar de harde schijf (waardoor het lijkt alsof je pc door stroop heen denkt).
Een veilige vuistregel voor modellen met int4-kwantisering:
- 8 GB RAM → ~3 miljard modellen
- 16 GB RAM → ~7B-modellen
- 32 GB RAM → ~13 miljard modellen
En als je gebruikmaakt van GPU-versnelling:
- 6 GB VRAM → ~3 miljard modellen
- 8 GB VRAM → ~7 miljard modellen
- 12 GB VRAM → ~13 miljard modellen
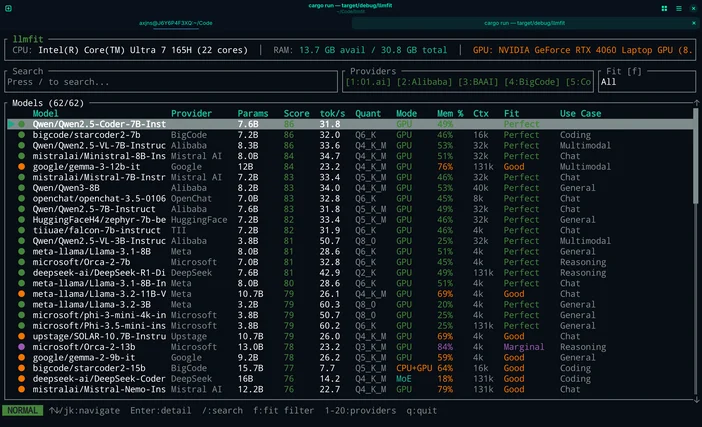
Of als je niet wilt gissen, kun je LLMfit gebruiken om modellen af te stemmen op jouw specifieke hardware.
LLMfit is een terminalprogramma dat je CPU, RAM en GPU/VRAM detecteert en vervolgens modellen rangschikt op basis van geschiktheid, verwachte snelheid, context en kwaliteit, zodatje al voordat je iets downloadt kunt zien welke modellen goed zullen werken.
Waarvoor het geschikt is:
- Modellen vinden die daadwerkelijk binnen je RAM/VRAM-limieten passen
- De aanbevolen kwantisering bekijken (zodat je niet te veel geheugen reserveert)
- Een gerangschikte shortlist krijgen in plaats van modelhubs waar je eindeloos doorheen scrolt
Hoe u dit in deze workflow kunt gebruiken:
- Voer llmfit uit om de hardware van uw systeem te scannen
- Bekijk de beste ‘fits’ / aanbevelingen
- Kies een modelmaat die bij je machine past en download het vervolgens in LM Studio / Ollama / llama
Je bent helemaal klaar!
Dat is alles. Kies een runner, download een model dat bij je hardware past en begin met het geven van opdrachten! Alles blijft op je eigen computer staan. Je hebt geen diploma in informatica, geen cloudabonnement en geen weekend vol probleemoplossingen nodig. Het hele proces duurt ongeveer even lang als het installeren van een game. En zodra het draait, heb je een persoonlijke, offline AI-assistent die werkt zoals jij dat wilt.
Waar de CORSAIR AI300 past
Als je serieus van plan bent om lokale LLM’s op Windows te draaien, vooral als je grotere modellen, grotere contextvensters of soepelere prestaties wilt, dan is dit de plek waar CORSAIR AI Workstation 300 (AI300) en de CORSAIR AI Software Stack je naar het volgende niveau helpen.
Lokale inferentie stuit meestal op beperkingen op het gebied van geheugen en doorvoercapaciteit. De AI300 is speciaal ontworpen met het oog op die realiteit:
- Een compact werkstation, speciaal ontworpen voor lokale AI-workflows
- Een configuratie met veel geheugen, die je voldoende ruimte biedt voor grotere modellen
- Het gedrag van het grafische geheugen dat is ontworpen om te schalen voor AI-toepassingen
- Een prestatieschakelaar op hardwareniveau (Stil / Gebalanceerd / Max) waarmee je kunt kiezen of je stilte of snelheid wilt

Heb ik een NVIDIA-GPU nodig om een lokale LLM op Windows te draaien?
Nee. Sommige tools bieden bijvoorbeeld expliciet ondersteuning voor AMD onder Windows; in de Windows-documentatie van Ollama wordt zowel ondersteuning voor NVIDIA- als AMD Radeon-GPU’s genoemd.
Kan ik een lokale LLM volledig offline gebruiken?
Ja, nadat je de app en de modelbestanden hebt gedownload. Voor de eerste installatie en het downloaden van modellen is meestal een internetverbinding nodig, maar zodra alles lokaal is opgeslagen, kun je de inferentie offline uitvoeren.
Is lokale AI automatisch privé?
Dat kan, maar het hangt af van je configuratie. Lokale inferentie houdt in dat het model op je apparaat draait, maar sommige apps bieden optionele cloudverbindingen. Als je geen gebruik wilt maken van de cloud, schakel dan de cloudintegraties uit en gebruik alleen lokale modellen.
Waarom werkt mijn lokale model zo traag?
Meestal een van deze:
- Het model is te groot voor je beschikbare RAM/VRAM
- Je gebruikt alleen de CPU terwijl GPU-versnelling beschikbaar is
- Je hebt een hoge contextlengte gekozen en dat kost veel geheugen
- Je opslagruimte is vol (ja, dat is belangrijk)
PRODUCTEN IN ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.