Het gebruik van een groot taalmodel (LLM) op je eigen pc klinkt intimiderend, maar het is verrassend toegankelijk. Een 'lokaal LLM' betekent simpelweg dat de AI op je hardware draait, zonder cloud, zonder account, en dat je gegevens bij jou blijven. Denk aan privé brainstormen, hulp bij code en vragen en antwoorden over documenten, allemaal zonder iets online te versturen. Als dat je aanspreekt, laten we je dan van nul naar de eerste prompt brengen.
Welke tools gebruiken we?
De meest beginnersvriendelijke optie op dit moment is Ollama, een gratis app die een uitgebreide catalogus van open modellen downloadt en uitvoert met éénregelige commando's (de app wordt nu geleverd met een Windows- en macOS-desktopapp, zodat je niet in een terminal hoeft te leven).
Als u de voorkeur geeft aan een meer visuele, alles-in-één ervaring, LM Studio (ook gratis) een andere uitstekende keuze voor het ontdekken, uitvoeren en beheren van lokale modellen. Open WebUI is een lichtgewicht, zelfgehoste chatinterface die bovenop Ollama kan worden geplaatst. Kies er één of combineer ze.


Wat u nodig hebt (hardware en besturingssysteem)
- Besturingssysteem: Windows 10/11, macOS of Linux (hieronder geven we voorbeelden voor Windows).
- Geheugen en opslag: 16–32 GB RAM is voldoende voor modellen met 7–13 miljard parameters; meer RAM helpt bij grotere contexten. Houd tientallen GB's vrij op een SSD voor modellen en caches.
- GPU (optioneel maar handig): een moderne GPU versnelt de verwerking en maakt het mogelijk om grotere modellen te gebruiken. Op Windows ondersteunt Ollama GPU-versnelling en publiceert het AMD-geoptimaliseerde builds.
- Opmerking over geïntegreerde grafische kaarten van AMD (APU's): nieuwe Ryzen AI Max+-systemen kunnen systeemgeheugen delen als 'variabel grafisch geheugen', waardoor tot 96 GB VRAM beschikbaar is voor de iGPU met de juiste configuratie. Dit is handig voor grotere modellen thuis.
Snel aan de slag (Windows): de snelste weg naar uw eerste prompt
- Installeer Ollama
- Download het Windows-installatieprogramma van Ollama of installeer het via Winget: "winget install --id Ollama.Ollama"
Na de installatie beschikt u zowel over de Ollama-app (GUI) als over het opdrachtregelprogramma.
- Starten en verifiëren
- Open de Ollama-desktopapp en log in als daarom wordt gevraagd (voor lokaal gebruik is geen cloud nodig).
- Of controleer de CLI: "ollama --version". (U ziet dan een versienummer.)
- Trek een startmodel
- Blader in de app door de modellen en download er een. Of in een terminal: "ollama run llama3:8b
- Hiermeewordt het model gedownload en komt u in een prompt terecht. Typ een vraag en ga aan de slag. U kunt in de Ollama Library door vele modellen bladeren (Gemma, Llama, Qwen, OLMo en meer).
- (Optioneel) GPU-versnelling inschakelen
- Houd uw grafische stuurprogramma's up-to-date. Ollama biedt Windows-builds met AMD-versnelling en AMD documenteert DirectML/ROCm-paden voor LLMs op Radeon. Controleer in de Ollama-app of de GPU wordt gedetecteerd (of bekijk het GPU-gebruik in Taakbeheer tijdens het genereren).
Welk model moet je als eerste proberen?
- "Klein en snel": gemma3:1b of llama3:8b, geschikt voor snelle reacties en eenvoudige hardware.
- "Evenwichtig": 7B–13B-modellen (bijv. olmo2:7b, llama3:8b instruct) solide voor algemeen gebruik.
- "Grotere hersenen": 20B+ modellen (bijv. gpt-oss:20b, grotere Llama-varianten) hebben meer RAM/VRAM en geduld nodig, maar blinken uit in moeilijkere taken. Je kunt elk van deze modellen rechtstreeks in de app of via ollama run <model> ophalen.
Tips voor het optimaliseren van uw lokale LLM
- Contextlengte: groter is niet altijd beter. Enorme contexten (bijvoorbeeld 32k-64k tokens) kunnen het genereren aanzienlijk vertragen. Begin met 4k–8k en verhoog alleen wanneer dat nodig is.
- Kwantificering: De meeste door apps geleverde modellen zijn al voor u gekwantificeerd, wat handig is om grotere modellen in beperkte VRAM te passen.
- Opslag: Bewaar modellen op een SSD; HDD's zullen traag aanvoelen.
- Stuurprogramma's: Werk GPU-stuurprogramma's en de app regelmatig bij. Lokale AI ontwikkelt zich snel.
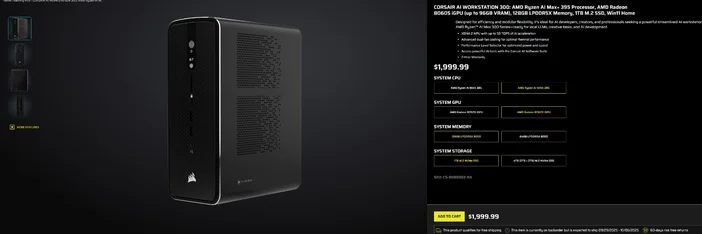
Gebruik van de CORSAIR AI WORKSTATION 300
Als u liever geen losse onderdelen wilt samenstellen en een compacte, stille desktop wilt die direct klaar is voor lokale LLM's, dan is de CORSAIR AI WORKSTATION 300 voldoet aan veel eisen van makers en ontwikkelaars:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (tot 96 GB VRAM), XDNA 2 NPU tot 50 TOPS
- Geheugen en opslag: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB + 2 TB)
- Besturingssysteem: Windows 11 Home
- Ontwerp: 4,4 liter chassis met kleine vormfactor, dubbele ventilatorkoeling en een prestatieniveauselectieknop
Die "tot 96 GB VRAM" op de Radeon iGPU past bijzonder goed bij Windows-tools die groot gedeeld geheugen aan de GPU kunnen toewijzen, wat handig is voor grotere lokale modellen en langere contexten wanneer u die nodig hebt. Het is een overzichtelijke, compacte weg naar lokale AI-ontwikkeling zonder in te boeten aan capaciteit.
Veelgestelde vragen
Heb ik een speciale GPU nodig om een lokale LLM te draaien?
Nee. Je kunt kleinere modellen op systemen met alleen een CPU draaien, maar de reacties zullen dan wel trager zijn. Een moderne GPU of een geavanceerde APU met groot gedeeld geheugen verhoogt de snelheid en stelt je in staat om grotere modellen te gebruiken.
Is dit privé?
Ja. Met lokale tools zoals Ollama of LM Studio blijven prompts en gegevens standaard op uw computer staan. (Integraties die u toevoegt, kunnen zich anders gedragen. Controleer altijd de instellingen.)
Waar vind ik modellen?
De Ollama Library bevat een lijst met populaire, actuele opties (Llama, Gemma, Qwen, OLMo en meer). Op elke modelpagina staan de formaten en voorbeeldcommando's vermeld.
Kan de CORSAIR AI WORKSTATION 300 grote modellen aan?
Het is ontworpen voor lokale LLM's, met 128 GB geheugen en een iGPU die toegang heeft tot maximaal 96 GB VRAM, wat uitstekende ruimte biedt voor geavanceerde lokale workloads en lange contexten, vooral nu de Windows-stuurprogramma's van AMD ondersteuning bieden voor grote toewijzingen. De werkelijke doorvoer is afhankelijk van de modelgrootte, kwantisering en instellingen.
PRODUCTEN IN ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.