Een CUDA-kern is een van de kleine rekenunits in een NVIDIA GPU die het zware werk voor grafische weergave en parallelle berekeningen uitvoert. Elke kern bevindt zich in een groter blok dat een Streaming Multiprocessor (SM) wordt genoemd, en op moderne GeForce "Blackwell" GPU's bevat elke SM 128 CUDA-kernen. Daarom zie je een totaal aantal van bijvoorbeeld 21.760 CUDA-kernen op een RTX 5090. De chip heeft gewoon veel SM's, die elk vol zitten met die kernen.
CUDA (het parallelle computerplatform van NVIDIA) is de softwarekant van het verhaal: het stelt apps en frameworks in staat om massaal parallelle taken zoals rendering, AI en simulatie efficiënt naar die cores te sturen.

Hoe werken CUDA-kernen?
Zie een GPU als een fabriek die is ontworpen voor bulkwerkzaamheden. CUDA-kernen verwerken werk in warps-groepen van 32 threads die dezelfde instructie uitvoeren op verschillende gegevens (een model dat NVIDIA SIMT noemt). Zo verwerken GPU's duizenden bewerkingen tegelijk. Elke SM heeft schedulers die veel warps in de lucht houden om geheugenlatentie te verbergen en die kernen bezig te houden.
Een nuttig mentaal beeld:
- CUDA-kern = een individuele worker (voert rekenkundige bewerkingen uit, zoals optellen en vermenigvuldigen).
- SM = een werkruimte met eigen planners, caches, speciale functie-eenheden, Tensor Core(s), enz.
- GPU = de hele fabriek, met veel SM's die parallel werken.
CUDA-kernen versus CPU-kernen (en andere GPU-kernen)
- Geen CPU-kernen: een CUDA-kern is een eenvoudigere rekenbaan die is geoptimaliseerd voor doorvoer, geen grote, op latentie afgestemde CPU-kern voor algemeen gebruik. GPU's schalen door veel van deze kleine banen samen te laten werken. (De programmeergids van CUDA legt dit op doorvoer gerichte ontwerp uit.)
- Verschillend van gespecialiseerde GPU-kernen:
- Tensor Cores zijn matrix-wiskundige engines die AI/ML en functies zoals DLSS een boost geven.
- RT Cores versnellen ray tracing (BVH-traversal, ray/triangle-tests).
Deze nemen specifieke taken over, zodat CUDA-kernen zich kunnen concentreren op shading/berekeningen.

Afbeelding: NVIDIA
Betekenen meer CUDA-kernen altijd betere prestaties?
Meestal wel, maar niet op zichzelf. Architectuur is erg belangrijk. Zo verdubbelde de Ampere-generatie van NVIDIA de FP32-doorvoer per SM ten opzichte van Turing, waardoor het vermogen 'per core' tussen generaties veranderde. Ada heeft ook de caches (met name L2) aanzienlijk uitgebreid, wat veel workloads een boost geeft zonder het aantal cores te veranderen. Kortom: het vergelijken van het aantal CUDA-cores tussen verschillende generaties is niet hetzelfde als appels met appels vergelijken.
Andere belangrijke factoren:
- Kloksnelheden en vermogensreserve (hoe snel cores werken).
- Geheugenbandbreedte en cachegroottes (voeding van de cores).
- Gebruik van Tensor/RT-kernen (AI en ray tracing verschuiven het werk van CUDA-kernen).
- Stuurprogramma's en software (hoe goed een app de GPU via CUDA gebruikt).
Wat doen CUDA-kernen eigenlijk in de praktijk?
- Gaming/graphics: Ze draaien shaderprogramma's (vertex, pixel, compute) onder de motorkap. RT-kernen verwerken de zware ray-tracing-stappen; CUDA-kernen doen nog steeds veel shading en berekeningen rondom deze stappen.
- Contentcreatie en simulatie: Fysicasolvers, denoisers, renderkernels, video-effecten – veel daarvan zijn geschreven om te profiteren van het parallelle model van CUDA.
- AI/ML: Tensorbewerkingen worden uitgevoerd door Tensor Cores, maar veel voorbewerkingen, nabewerkingen en niet-matrixwerkzaamheden worden nog steeds uitgevoerd door CUDA-kernen.
Hoeveel CUDA-kernen heb ik nodig?
Een handige vuistregel:
- Gamen met hoge FPS 1080p–1440p: kijk naar de hele GPU (architectuur, kloksnelheden, geheugen, RT/Tensor-functies), niet alleen naar het aantal cores. Benchmarks zijn belangrijker dan het ruwe aantal.
- 4K of zware ray tracing: u profiteert van meer SM's/CUDA-kernen en krachtige RT/Tensor-blokken, plus bandbreedte en cache.
- AI/rekenkracht: Het aantal cores helpt, maar de Tensor Core-capaciteit, VRAM-grootte en geheugenbandbreedte bepalen vaak de doorvoersnelheid.
Als je snel wilt controleren of de schaal klopt, vermeldt RTX 5090 21.760 CUDA-kernen, waarmee wordt aangetoond hoe NVIDIA de kernen per SM over vele SM's telt. Maar nogmaals, prestatieverbeteringen komen voort uit het totale ontwerp, niet alleen uit het aantal.
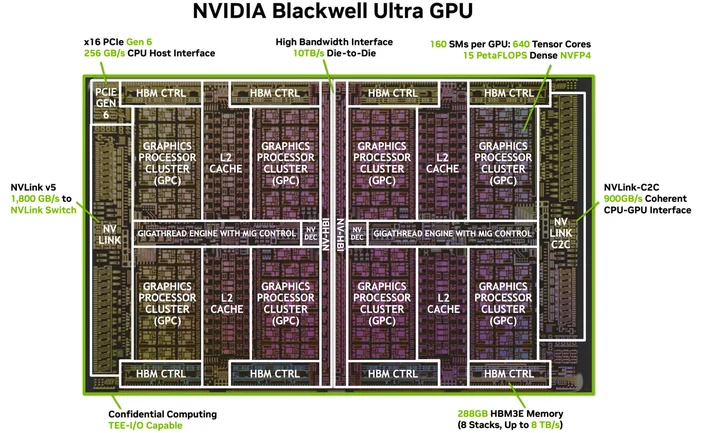
Afbeelding: NVIDIA
Heb ik speciale software of kabels nodig? (De 'HDMI voor 4K' van CUDA)
Je hebt geen speciale kabel nodig, maar wel de juiste software. CUDA is het platform van NVIDIA; apps gebruiken het via stuurprogramma's, toolkits en bibliotheken. Veel populaire applicaties en frameworks zijn al gebouwd om gebruik te maken van CUDA-versnelling zodra je NVIDIA-stuurprogramma's en (indien nodig) de CUDA Toolkit zijn geïnstalleerd. Ondersteunde apps gebruiken het gewoon...
Welke GPU's ondersteunen CUDA?
CUDA draait op CUDA-compatibele NVIDIA GPU's in alle productlijnen (GeForce/RTX voor gaming en creatie, professionele RTX en GPU's voor datacenters). De programmeergids vermeldt dat het model geschikt is voor vele GPU-generaties en SKU's. NVIDIA houdt een lijst bij van CUDA-compatibele GPU's en hun rekencapaciteiten.
Is een CUDA-kern hetzelfde als een 'shader-kern'?
In het dagelijkse GPU-jargon verwijst 'CUDA-kernen' op NVIDIA GPU's naar de programmeerbare FP32/INT32 ALU's die worden gebruikt voor shading en algemene berekeningen binnen elke SM.
Waarom verschillen de CUDA-kerncijfers zo sterk tussen de verschillende generaties?
Omdat architecturen evolueren. Ampere heeft FP32-datapaden gewijzigd (meer werk per klok) en Ada heeft caches herzien, zodat de prestaties niet lineair schalen met het aantal cores.
Wat is een warp ook alweer?
Een groep van 32 threads die synchroon worden uitgevoerd op de SM. Apps starten duizenden threads; de GPU plant ze in als warps om de hardware bezig te houden.
Helpen CUDA-kernen bij AI?
Ja, maar de grote versnellers voor moderne AI zijn Tensor Cores. CUDA-kernen verwerken nog steeds veel van het omliggende werk in die pijplijnen.
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.