Dacă folosești inteligența artificială la nivel local, probabil ai auzit sfatul: „ia-ți un GPU bun”. Dar ce înseamnă asta, de fapt? Și chiar este procesorul tău atât de nefolositor? Răspunsul nu este atât de simplu precum „GPU-ul e bun, procesorul e rău”. Ceea ce contează este modul în care fiecare procesor gestionează operațiile matematice din spatele inferenței AI și care dintre ele poate transfera datele suficient de repede pentru a ține pasul.
Ce se întâmplă de fapt în timpul inferenței AI?
Când rulezi un model LLM sau un model de procesare a imaginilor la nivel local, hardware-ul tău efectuează în mod repetat o singură operație: înmulțirea matricilor. Modelul preia datele introduse, le transformă în numere și le supune unor miliarde de operații matematice pe parcursul tuturor straturilor sale. Cu cât hardware-ul tău poate procesa mai rapid aceste operații, cu atât mai repede primești un răspuns.
Aceasta este inferența, adică generarea de rezultate pe baza unui model antrenat. Nu antrenezi nimic. Pur și simplu aplici algoritmul, câte un token pe rând.
Cum gestionează un procesor sarcinile de inteligență artificială
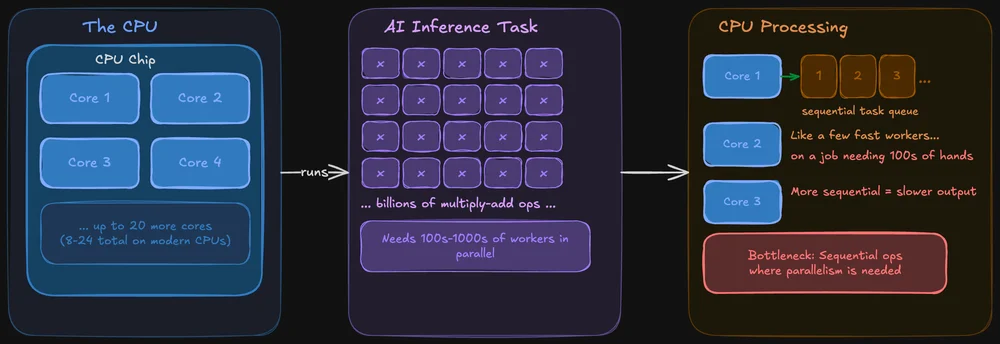
Un procesor este conceput pentru a excela în toate domeniile. Acesta gestionează sistemul de operare, filele browserului, sistemul de fișiere și, da, poate rula și modele de inteligență artificială. Procesoarele moderne au mai multe nuclee (de obicei între 8 și 24 în cazul cipurilor destinate consumatorilor), iar fiecare nucleu este puternic și flexibil.
Problema: inferența AI presupune efectuarea simultană a aceleiași operații asupra unor volume uriașe de date. Un procesor (CPU) poate face acest lucru, dar procesează aceste operații mai degrabă secvențial. E ca și cum ai avea câțiva muncitori foarte rapizi care se ocupă de o sarcină care ar avea nevoie, de fapt, de sute de mâini care să lucreze simultan.
Cu toate acestea, procesoarele nu sunt o opțiune fără speranță pentru IA locală. Instrumente precum llama.cpp sunt optimizate special pentru inferența pe procesor, iar dacă modelul tău încape în memoria RAM a sistemului, îl poți rula fără probleme doar pe procesor. Pur și simplu va fi mai lent, uneori în mod vizibil, alteori nu, în funcție de dimensiunea modelului.
Cum gestionează un GPU sarcinile de inteligență artificială
Un GPU este conceput în jurul principiului paralelismului. În timp ce un CPU poate avea între 8 și 24 de nuclee, un GPU modern dispune de mii de nuclee mai mici, care pot lucra simultan la segmente ale aceleiași probleme. Acest lucru face ca GPU-urile să fie extrem de eficiente în efectuarea operațiilor matematice de mare volum de care depind modelele de IA.
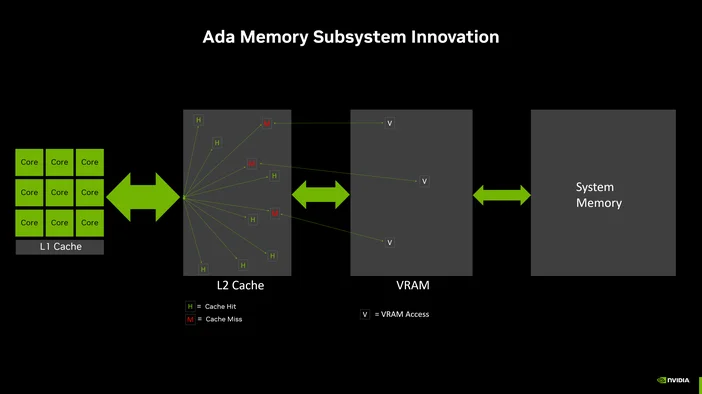
În plus, procesoarele grafice dispun de propria memorie dedicată (VRAM), cu o lățime de bandă mult mai mare decât memoria RAM a sistemului. Această lățime de bandă este extrem de importantă, deoarece determină viteza cu care datele pot fi transmise către acele mii de nuclee. O lățime de bandă mai mare înseamnă mai puțin timp de așteptare și mai mult timp dedicat calculelor.
În ceea ce privește în mod specific inferența locală a modelelor LLM, avantajul GPU se rezumă la două aspecte: puterea de procesare paralelă și lățimea de bandă a memoriei. Ambele influențează în mod direct numărul de tokenuri pe secundă pe care îl veți obține în rezultatul final.
Lățimea de bandă a memoriei
Iată un lucru care surprinde pe majoritatea oamenilor: în cazul inferenței locale a modelelor LLM, puterea brută de calcul nu este adesea factorul limitativ. Lățimea de bandă a memoriei este.
În timpul inferenței, ponderile modelului trebuie citite din memorie pentru fiecare token generat. Dacă memoria nu poate furniza date procesorului suficient de repede, nu contează câte nuclee ai – acestea vor rămâne pur și simplu în așteptare.
De aceea lățimea de bandă a memoriei VRAM este atât de importantă. O configurație tipică de memorie de sistem DDR5 poate oferi o lățime de bandă de 50–90 GB/s. Un procesor grafic modern, precum RTX 5090, oferă peste 1.000 GB/s. Este o diferență de ordinul de mărime.
Dacă modelul tău încape în întregime în memoria VRAM, doar din acest motiv, procesul de inferență va fi aproape întotdeauna mai rapid pe GPU decât pe CPU.
Când utilizarea exclusivă a procesorului are într-adevăr sens
GPU-ul nu este întotdeauna soluția. Există situații concrete în care rularea pe CPU este alegerea potrivită:
- Folosești un model de dimensiuni reduse (cu 3B parametri sau mai puțin), în care diferența de viteză este aproape imperceptibilă.
- Nu ai o placă grafică compatibilă sau placa ta grafică nu dispune de suficientă memorie VRAM pentru a rula modelul.
- Doriți să utilizați întreaga memorie RAM a sistemului (care este de obicei mult mai mare decât VRAM) pentru a rula un model mai mare la o viteză mai mică.
- Utilizați un laptop sau un sistem în cazul căruia consumul de energie al plăcii grafice sau încălzirea reprezintă o problemă.
Performanța de inferență pe CPU s-a îmbunătățit semnificativ datorită cuantificării (reducerea preciziei modelului pentru a utiliza mai puțină memorie) și a cadrelor de lucru optimizate în acest sens. Un model cuantificat de 7 miliarde de parametri, rulat pe un procesor modern cu 32 GB de memorie RAM, funcționează suficient de bine pentru multe sarcini.


Dar cum rămâne cu descărcarea?
Dacă modelul tău este prea mare pentru memoria VRAM, dar dorești totuși accelerare prin GPU, majoritatea instrumentelor locale pentru LLM acceptă descărcarea parțială. Aceasta înseamnă că anumite straturi ale modelului rulează pe GPU, în timp ce restul rulează pe CPU.
Este un compromis: beneficiezi de o parte din viteza oferită de GPU, dar straturile care depind de CPU devin un gât de sticlă. Cu cât încap mai multe straturi în memoria VRAM, cu atât procesul va fi mai rapid. Iar dacă doar câteva straturi ajung pe GPU, efortul suplimentar generat de transferul datelor în ambele sensuri ar putea, de fapt, să încetinească procesul față de o inferență realizată exclusiv pe CPU.
Regula generală: dacă nu poți încărca cel puțin jumătate din model în memoria VRAM, probabil că e mai bine să-l rulezi în întregime pe procesor și să te scutești de complicații.
NVIDIA vs AMD în domeniul IA locale
În prezent, NVIDIA domină piața locală a inteligenței artificiale, în principal datorită CUDA, cadrul de calcul propriu pe care se bazează aproape toate instrumentele de IA. Dacă folosești LM Studio, Ollama sau llama.cpp pe Windows, plăcile grafice NVIDIA îți vor oferi cea mai fluidă experiență, cu cele mai puține probleme tehnice.
AMD începe să recupereze terenul pierdut. ROCm (răspunsul AMD la CUDA) a înregistrat progrese reale, iar instrumente precum Ollama oferă suport explicit pentru plăcile grafice AMD Radeon pe Windows. Totuși, ecosistemul este încă mai limitat și s-ar putea să te confrunți cu probleme de compatibilitate, în funcție de placa grafică pe care o ai și de instrumentul pe care îl folosești.
Dacă vrei să achiziționezi un produs special pentru aplicații locale de IA, NVIDIA este cea mai sigură alegere în acest moment. Dacă ai deja un procesor grafic AMD, merită cu siguranță să încerci; verifică însă mai întâi documentația instrumentului tău pentru a vedea ce modele sunt compatibile.

Unde se potrivește CORSAIR AI300
Dacă configurația ta actuală te pune în dificultate – fie că este vorba de memorie video insuficientă, lățime de bandă redusă a memoriei sau un sistem care se supraîncălzește imediat ce încarci un model 13B –, acesta este exact genul de problemă pe care stația de lucru CORSAIR AI Workstation 300 (AI300) a fost concepută să o rezolve.
AI300 este o stație de lucru compactă concepută pentru a răspunde cerințelor inferenței locale de IA:
- Configurație cu memorie mare, care permite utilizarea unor modele mai complexe și a unor ferestre de context mai mari.
- Memorie grafică concepută pentru a face față sarcinilor de lucru legate de IA (și pentru câteva jocuri).
- Un selector de performanță la nivel hardware (Silențios / Echilibrat / Maxim), care îți permite să acorzi prioritate vitezei atunci când ai nevoie de ea și liniștii atunci când nu ai nevoie.
- Suita de programe CORSAIR AI, care simplifică procesul de configurare, astfel încât să petreceți mai puțin timp cu configurarea și mai mult timp cu rularea modelelor.
Dacă ați încercat să integrați funcții de inteligență artificială locală într-un sistem care nu a fost conceput pentru acest scop, AI300 vă oferă un sistem în care atât hardware-ul, cât și software-ul sunt concepute special pentru a face față sarcinilor respective.

PRODUSE ÎN ARTICOL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.