HOW TO
Cum să rulezi un model LLM local pe Windows (fără a fi necesar un serviciu cloud)
Ultima actualizare:
Rularea unui model LLM la nivel local înseamnă că modelul se află pe computerul tău, iar solicitările tale (și orice fișiere pe care i le furnizezi) nu trebuie să părăsească dispozitivul tău. Fără cont de cloud. Fără chei API. Fără „vom antrena modelul pe datele tale… probabil că nu… poate”. Doar tu, computerul tău și un model care îndeplinește orice sarcină îi dai.
Ce este, mai exact, un „LLM local”?
Un model lingvistic local (LLM) este un model lingvistic de mari dimensiuni care rulează pe computerul tău, nu pe un server la distanță. În practică, asta înseamnă, de obicei, că descarci fișierele modelului, le încarci într-o aplicație locală și comunici cu ele la fel cum ai face cu un asistent din cloud, cu diferența că „serverul” este propriul tău computer.
„Rularea” unui model LLM la nivel local înseamnă aproape întotdeauna efectuarea de inferențe (generarea de răspunsuri), nu antrenarea unui model complet nou de la zero.
De ce să folosești un model LLM local?
Există câteva motive pentru care oamenii trec de la modelele LLM din cloud la cele locale:
- Confidențialitate: Solicitările tale rămân pe dispozitiv (atâta timp cât nu utilizezi conectori cloud).
- Utilizare offline: Odată ce modelul a fost descărcat, îl puteți rula fără conexiune la internet.
- Fără limite de utilizare: fără restricții de viteză, fără mesaje de genul „ați epuizat cota zilnică”, fără facturi neașteptate.
- Control: Alege modelul dorit, nu ești obligat să optezi pentru un abonament.
Desigur, schimbi comoditatea pe control. Un model cloud poate părea o minune; un model local poate părea o minune, în funcție de hardware-ul pe care îl ai.
De ce ai nevoie pentru a rula un model LLM local?
Pe scurt: procesorul face treaba, placa video ajută, memoria contează.
Iată ce contează cu adevărat pentru a te simți bine:
- RAM / VRAM: Modelele mai mari necesită mai multă memorie. Dacă memoria se epuizează, modelul nu va funcționa.
- Spațiu de stocare: Modelele pot ocupa mult spațiu. Unele biblioteci avertizează că spațiul necesar pentru stocarea modelelor poate ajunge la zeci sau chiar sute de GB, în funcție de modelul descărcat.
- GPU: Dacă aplicația ta este compatibilă cu placa grafică, vei observa, de obicei, o creștere semnificativă a vitezei.
Un computer modern cu Windows 10/11 și cel puțin 32 GB de memorie RAM constituie o bază solidă pentru modelele locale mai mici, iar o memorie mai mare îți permite să rulezi mai ușor modelele mai mari.
Alege o aplicație de tip „LLM runner local”
LM Studio (interfață grafică intuitivă)
LM Studio este o aplicație pentru desktop care îți permite să descarci modele și să comunici cu ele la nivel local. De asemenea, include o API locală programabilă destinată dezvoltatorilor.
Ollama (interfață CLI simplă + API local)
Ollama rulează ca aplicație nativă pentru Windows și îți oferă un flux de lucru bazat pe linia de comandă, precum și un punct final API HTTP local. Aplicația suportă în mod explicit plăcile grafice NVIDIA și AMD Radeon pe Windows.
llama.cpp (pentru pasionații de programare)
Dacă doriți un control maxim, llama.cpp este un motor de inferență open-source foarte utilizat, care include instrucțiuni de compilare și mai multe backend-uri.

Instalează și rulează primul tău model
Modelele mai mari necesită mai multă memorie RAM și/sau VRAM. Dacă nu dispui de suficientă memorie, vei avea de-a face cu o performanță redusă, blocări ale sistemului sau transferuri constante pe disc (ceea ce dă senzația că PC-ul tău funcționează cu o viteză extrem de lentă).
O regulă generală sigură pentru modelele cuantificate la int4:
- 8 GB RAM → ~3 miliarde de modele
- 16 GB RAM → ~7 miliarde de modele
- 32 GB RAM → ~13 miliarde de modele
Și dacă te bazezi pe accelerarea prin GPU:
- 6 GB VRAM → ~3 miliarde de modele
- 8 GB VRAM → ~7 miliarde de modele
- 12 GB VRAM → ~13 miliarde de modele
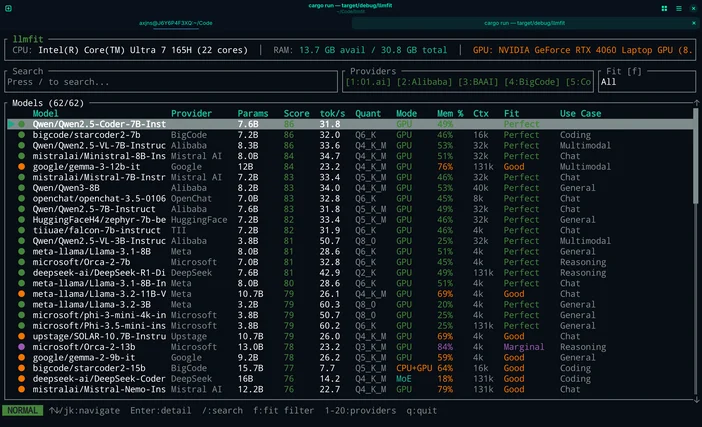
Sau, dacă nu vrei să ghicești, poți folosi LLMfit pentru a adapta modelele exact la configurația hardware pe care o ai.
LLMfit este un instrument de terminal care detectează procesorul, memoria RAM și placa grafică/memoria VRAM, apoi clasifică modelele în funcție de compatibilitate, viteza estimată, context și calitate, astfel încâtsă poți vedea ce va funcționa bine înainte de a descărca ceva.
La ce este bun:
- Găsirea unor modele care se încadrează efectiv în limitele de RAM/VRAM
- Verificarea nivelului de cuantificare recomandat (pentru a evita supraîncărcarea memoriei)
- Obținerea unei liste restrânse clasificate, în locul centrelor de modele care încurajează „doomscrolling-ul”
Cum se utilizează în acest flux de lucru:
- Rulați llmfit pentru a scana componentele hardware ale sistemului
- Uită-te la recomandările de sus
- Alege o dimensiune a modelului potrivită pentru mașina ta, apoi descarcă-l din LM Studio / Ollama / llama
Gata!
Asta e tot. Alegeți un motor de execuție, descărcați un model compatibil cu hardware-ul dvs. și începeți să dați comenzi! Totul rămâne pe computerul dvs. Nu aveți nevoie de o diplomă în informatică, de un abonament la servicii cloud sau de un weekend petrecut rezolvând probleme. Întregul proces durează cam cât instalarea unui joc. Iar odată ce este pornit, veți avea un asistent AI privat, care funcționează offline și după propriile dvs. reguli.
Unde se potrivește CORSAIR AI300
Dacă intenționezi cu adevărat să rulezi modele LLM locale pe Windows, mai ales dacă îți dorești modele mai mari, ferestre de context mai extinse sau o performanță mai fluidă, atunci CORSAIR AI Workstation 300 (AI300) și suita de software CORSAIR AI vă ajută să treceți la nivelul următor.
Inferența locală se confruntă de obicei cu blocaje legate de memorie și de lățimea de bandă. AI300 a fost conceput ținând cont de această realitate:
- O stație de lucru compactă concepută pentru fluxuri de lucru locale bazate pe inteligență artificială
- O configurație cu memorie mare, care îți oferă spațiu suficient pentru modele mai complexe
- Comportamentul memoriei grafice conceput pentru a se adapta la cazurile de utilizare ale IA
- Un selector de performanță la nivel hardware (Silențios / Echilibrat / Max) care îți permite să alegi între liniște și viteză

Am nevoie de un procesor grafic NVIDIA pentru a rula un model de limbaj mare (LLM) local pe Windows?
Nu. Unele instrumente acceptă în mod explicit plăcile AMD pe Windows; de exemplu, documentația Ollama pentru Windows menționează compatibilitatea atât cu plăcile NVIDIA, cât și cu cele AMD Radeon.
Pot rula un model LLM local complet offline?
Da, după ce ați descărcat aplicația și fișierele modelului. Instalarea inițială și descărcarea modelelor necesită, de obicei, conexiune la internet, dar procesul de inferență poate rula offline odată ce totul este stocat local.
Inteligența artificială locală este automat confidențială?
Este posibil, dar depinde de configurația ta. Inferența locală înseamnă că modelul rulează pe dispozitivul tău, însă unele aplicații oferă conexiuni opționale la cloud. Dacă obiectivul tău este „fără cloud”, menține integrările cu cloud dezactivate și folosește doar modele locale.
De ce modelul meu local funcționează lent?
De obicei, una dintre următoarele:
- Modelul este prea mare pentru memoria RAM/VRAM disponibilă
- Folosești doar procesorul, deși este disponibilă accelerarea prin GPU
- Ai ales o lungime mare a contextului și consumă multă memorie
- Spațiul de stocare este plin (da, contează)
PRODUSE ÎN ARTICOL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.