Rularea unui model lingvistic de mari dimensiuni (LLM) pe propriul PC poate părea intimidantă, dar este surprinzător de accesibilă. Un „LLM local” înseamnă pur și simplu că AI rulează pe hardware-ul dvs., fără cloud, fără cont, iar datele dvs. rămân la dvs. Gândiți-vă la brainstorming privat, ajutor pentru coduri și întrebări și răspunsuri despre documente, toate fără a trimite nimic online. Dacă vi se pare interesant, haideți să vă ajutăm să treceți de la zero la prima solicitare.
Ce instrumente folosim?
Cea mai potrivită opțiune pentru începători în acest moment este Ollama, o aplicație gratuită care descarcă și rulează un catalog larg de modele deschise cu comenzi de o singură linie (acum vine cu o aplicație desktop pentru Windows și macOS, astfel încât nu mai trebuie să trăiești într-un terminal).
Dacă preferați o experiență mai vizuală, completă, LM Studio (de asemenea gratuit) este o altă opțiune excelentă pentru descoperirea, rularea și gestionarea modelelor locale. Open WebUI este o interfață de chat ușoară, auto-găzduită, care poate fi instalată peste Ollama. Alegeți una sau combinați-le.


Ce aveți nevoie (hardware și sistem de operare)
- Sistem de operare: Windows 10/11, macOS sau Linux (vom prezenta exemple pentru Windows mai jos).
- Memorie și stocare: 16–32 GB RAM este suficient pentru modelele cu 7–13 miliarde de parametri; o memorie RAM mai mare ajută în cazul contextelor mai mari. Păstrați zeci de GB liberi pe un SSD pentru modele și cache-uri.
- GPU (opțional, dar util): un GPU modern accelerează procesele și vă permite să rulați modele mai mari. Pe Windows, Ollama acceptă accelerarea GPU și publică versiuni optimizate pentru AMD.
- Notă privind grafica integrată AMD (APU): Noile sisteme Ryzen AI Max+ pot partaja memoria sistemului ca „memorie grafică variabilă”, expunând până la 96 GB de VRAM către iGPU cu configurația potrivită — utilă pentru modelele mai mari de acasă.
Pornire rapidă (Windows): cea mai rapidă cale către prima linie de comandă
- Instalați Ollama
- Descărcați programul de instalare Windows de pe Ollama sau instalați-l prin Winget:„winget install --id Ollama.Ollama”
După instalare, veți avea atât aplicația Ollama (GUI), cât și instrumentul de linie de comandă.
- Lansați și verificați
- Deschideți aplicația desktop Ollama și conectați-vă dacă vi se solicită (nu este necesar cloud pentru utilizarea locală).
- Sau verificați CLI: „ollama --version”.(Veți vedea un număr de versiune.)
- Trageți un model de pornire
- În aplicație, căutați și descărcați un model. Sau într-un terminal: „ollama run llama3:8b
- „Aceasta va descărca modelul și vă va afișa o fereastră de dialog — introduceți o întrebare și continuați. Puteți răsfoi numeroase modele (Gemma, Llama, Qwen, OLMo și multe altele) în biblioteca Ollama.
- (Opțional) Activați accelerarea GPU
- Mențineți driverele grafice actualizate. Ollama oferă versiuni Windows cu accelerare AMD, iar AMD documentează căile DirectML/ROCm pentru LLM-uri pe Radeon. În aplicația Ollama, confirmați că GPU-ul este detectat (sau urmăriți utilizarea GPU-ului în Task Manager în timpul generării).
Ce model ar trebui să încercați mai întâi?
- „Mic și rapid”: gemma3:1b sau llama3:8b, bun pentru răspunsuri rapide și hardware de bază.
- „Echilibrat”: modelele 7B–13B (de exemplu, olmo2:7b, llama3:8b instruct) sunt solide pentru utilizare generală.
- „Creier mai mare”: modelele de peste 20B (de exemplu, gpt-oss:20b, variante Llama mai mari) necesită mai multă memorie RAM/VRAM și răbdare, dar excelează în sarcini mai dificile. Puteți accesa oricare dintre acestea direct în aplicație sau prin ollama run <model>.
Sfaturi pentru optimizarea LLM-ului local
- Lungimea contextului: Mai mare nu înseamnă întotdeauna mai bun. Contextele foarte mari (de exemplu, 32k-64k tokenuri) pot încetini generarea în mod dramatic. Începeți cu 4k–8k și măriți doar când este necesar.
- Cuantificare: Majoritatea modelelor furnizate de aplicație sunt deja cuantificate pentru a vă ajuta să încadrați modele mai mari în VRAM limitat.
- Stocare: Păstrați modelele pe un SSD; HDD-urile vor fi lente.
- Drivere: Actualizați regulat driverele GPU și aplicația AI locală evoluează rapid.
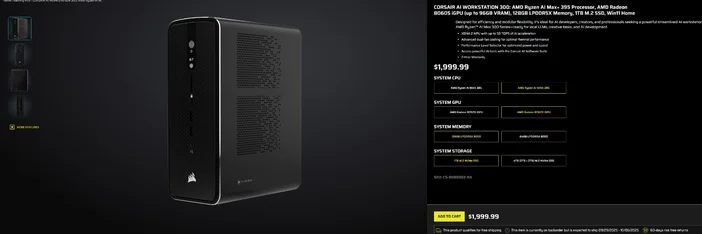
Utilizarea CORSAIR AI WORKSTATION 300
Dacă preferați să renunțați la asamblarea piesă cu piesă și doriți un desktop compact și silențios, gata de utilizare pentru LLM-uri locale, atunci CORSAIR AI WORKSTATION 300 îndeplinește multe dintre cerințele creatorilor și dezvoltatorilor:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (până la 96 GB VRAM), XDNA 2 NPU până la 50 TOPS
- Memorie și stocare: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB + 2 TB)
- Sistem de operare: Windows 11 Home
- Design: șasiu compact de 4,4 litri cu răcire cu două ventilatoare și selector de nivel de performanță
Această „memorie VRAM de până la 96 GB” de pe iGPU-ul Radeon se potrivește foarte bine cu instrumentele Windows care pot aloca memorie partajată mare pentru GPU, utilă pentru modele locale mai mari și contexte mai lungi, atunci când aveți nevoie de ele. Este o cale simplă și compactă către dezvoltarea locală a IA, fără a compromite capacitatea.
Întrebări frecvente
Am nevoie de un GPU dedicat pentru a rula un LLM local?
Nu. Puteți rula modele mai mici pe sisteme care utilizează doar CPU, însă răspunsurile vor fi mai lente. Un GPU modern sau un APU avansat cu memorie partajată mare îmbunătățește viteza și vă permite să măriți dimensiunea modelului.
Este confidențial?
Da. Cu instrumente locale precum Ollama sau LM Studio, prompturile și datele rămân în mod implicit pe computerul dvs. (Integrările pe care le adăugați pot funcționa diferit, verificați întotdeauna setările.)
Unde găsesc modele?
Biblioteca Ollama listează opțiuni populare și actualizate (Llama, Gemma, Qwen, OLMo și altele). Fiecare pagină a modelului afișează dimensiunile și exemple de comenzi.
Poate CORSAIR AI WORKSTATION 300 să gestioneze modele mari?
Este conceput pentru LLM-uri locale, cu memorie de 128 GB și un iGPU care poate accesa până la 96 GB VRAM, oferind un spațiu excelent pentru sarcini locale avansate și contexte lungi, mai ales că driverele Windows ale AMD extind suportul pentru alocări mari. Debitul real depinde de dimensiunea modelului, cuantificare și setări.
PRODUSE ÎN ARTICOL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.