Når du kører en LLM lokalt, betyder det, at modellen ligger på din pc, og at dine indtastninger (og eventuelle filer, du indlæser) ikke behøver at forlade din computer. Ingen cloud-konto. Ingen API-nøgler. Intet med "vi træner modellen på dine data… sandsynligvis ikke… måske." Bare dig, din pc og en model, der udfører enhver opgave, du giver den.
Hvad er en »lokal LLM« egentlig?
En lokal LLM er en stor sprogmodel, der kører på din computer i stedet for på en fjernserver. I praksis betyder det som regel, at du downloader modelfiler, indlæser dem i en lokal app og chatter med dem på samme måde, som du ville chatte med en cloud-assistent, bortset fra at »serveren« er din pc.
At »køre« en LLM lokalt betyder næsten altid inferens (generering af svar) og ikke træning af en helt ny model fra bunden.
Hvorfor køre en lokal LLM?
Der er flere grunde til, at folk skifter fra cloud-baserede store sprogmodeller til lokale:
- Privatliv: Dine indtastninger forbliver på enheden (så længe du ikke bruger cloud-forbindelser).
- Offline-brug: Når modellen er downloadet, kan du køre den uden internetforbindelse.
- Ingen forbrugsbegrænsninger: Ingen hastighedsbegrænsninger, ingen meddelelser om, at »du har opbrugt dagens kvote«, ingen uventede regninger.
- Valgfrihed: Vælg den model, du ønsker – du er ikke bundet af et abonnement.
Man bytter selvfølgelig bekvemmelighed mod kontrol. En cloud-løsning kan virke som ren magi; en lokal løsning kan virke som ren magi, afhængigt af din hardware.
Hvad skal der til for at køre en lokal LLM?
Kort sagt: CPU'en klarer opgaven, GPU'en hjælper til, og hukommelsen er afgørende.
Her er det, der rent faktisk afgør, om du får en god oplevelse:
- RAM/VRAM: Større modeller kræver mere hukommelse. Hvis hukommelsen slipper op, vil modellen gå ned.
- Lagring: Modellerne kan være store. Nogle biblioteker advarer om, at lagringsbehovet for modeller kan nå op på titusinder til hundreder af GB, afhængigt af hvilken model du downloader.
- GPU: Hvis din app understøtter din GPU, vil du som regel opleve en markant hastighedsforbedring.
En moderne Windows 10/11-computer med mindst 32 GB RAM er et godt udgangspunkt for mindre lokale modeller, og med mere hukommelse kan du køre større modeller uden problemer.
Vælg en app til at køre LLM lokalt
LM Studio (brugervenlig grafisk brugergrænseflade)
LM Studio er et desktop-program, der giver dig mulighed for at downloade modeller og chatte med dem lokalt. Det indeholder desuden et programmerbart lokalt API til udviklere.
Ollama (enkel kommandolinjegrænseflade + lokal API)
Ollama kører som en indbygget Windows-app og giver dig en kommandolinjebaseret arbejdsgang samt et lokalt HTTP-API-endpoint. Den understøtter specifikt NVIDIA- og AMD Radeon-GPU'er på Windows.
llama.cpp (til dem, der kan lide at eksperimentere)
Hvis du ønsker maksimal kontrol, er llama.cpp en populær open source-inferensmotor med vejledning til kompilering og flere backends.

Installer og kør din første model
Større modeller kræver mere RAM og/eller VRAM. Hvis du ikke har nok, vil du opleve langsom ydeevne, nedbrud eller konstant skift til harddisken (hvilket føles, som om din pc tænker gennem sirup).
En sikker tommelfingerregel for modeller med int4-kvantisering:
- 8 GB RAM → ~3B-modeller
- 16 GB RAM → ~7B-modeller
- 32 GB RAM → ~13B-modeller
Og hvis du benytter GPU-acceleration:
- 6 GB VRAM → ~3 mia. modeller
- 8 GB VRAM → ca. 7 mia. modeller
- 12 GB VRAM → ~13 milliarder modeller
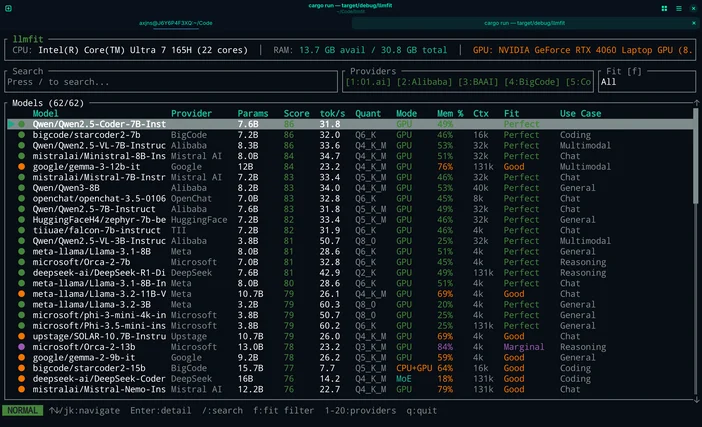
Eller hvis du ikke vil gætte, kan du bruge LLMfit til at tilpasse modellerne præcist til din hardware.
LLMfit er et terminalværktøj, der registrerer din CPU, RAM og GPU/VRAM og derefter rangordner modellerne efter egnethed, forventet hastighed, kontekst og kvalitet, sådu kan se, hvilke modeller der vil køre godt, inden du downloader noget.
Hvad det er godt til:
- Find modeller, der rent faktisk passer til dine RAM-/VRAM-begrænsninger
- Visning af anbefalet kvantisering (så du ikke bruger for meget hukommelse)
- At få en prioriteret liste i stedet for modelhubs, der kun viser negative nyheder
Sådan bruges det i denne arbejdsgang:
- Kør llmfit for at scanne dit systems hardware
- Se de bedste "match" / anbefalinger
- Vælg en modelstørrelse, der passer til din maskine, og download den derefter i LM Studio / Ollama / llama
Så er du klar!
Sådan gør du. Vælg en runner, download en model, der passer til din hardware, og kom i gang med at give kommandoer! Alt forbliver på din egen computer. Du behøver hverken en uddannelse i datalogi, et cloud-abonnement eller en hel weekend med fejlfinding. Hele processen tager omtrent lige så lang tid som at installere et spil. Og når det først kører, har du en privat, offline AI-assistent, der arbejder på dine betingelser.
Hvor passer CORSAIR AI300 ind?
Hvis du virkelig vil køre lokale LLM'er på Windows – især hvis du ønsker større modeller, større kontekstvinduer eller en mere jævn ydeevne – så er det her CORSAIR AI Workstation 300 (AI300) og CORSAIR AI Software Stack hjælper dig med at nå det næste niveau.
Lokal inferens støder normalt på flaskehalse i form af hukommelse og gennemstrømning. AI300 er designet med udgangspunkt i netop denne virkelighed:
- En kompakt arbejdsstation udviklet til lokale AI-arbejdsgange
- En konfiguration med stor hukommelse, der giver dig plads til større modeller
- Grafikhukommelsens adfærd, der er designet til at skalere i forbindelse med AI-anvendelser
- En ydelsesvælger på hardwareniveau (Stille / Afbalanceret / Maks.) så du selv kan vælge, om du vil have stilhed eller hastighed

Skal jeg have et NVIDIA-grafikkort for at køre en lokal LLM på Windows?
Nej. Nogle værktøjer understøtter udtrykkeligt AMD på Windows; for eksempel nævner Ollamas Windows-dokumentation både understøttelse af NVIDIA- og AMD Radeon-GPU'er.
Kan jeg køre en lokal LLM helt offline?
Ja, når du har downloadet appen og modelfilerne. Den første installation og download af modeller kræver normalt internetforbindelse, men inferens kan køre offline, når alt er gemt lokalt.
Er lokal AI automatisk privat?
Det kan godt være, men det afhænger af din opsætning. Lokal inferens betyder, at modellen kører på din enhed, men nogle apps tilbyder valgfri forbindelse til skyen. Hvis dit mål er, at der ikke skal bruges skyen, skal du holde skyintegrationerne deaktiveret og bruge modeller, der kun kører lokalt.
Hvorfor er min lokale model langsom?
Normalt en af disse:
- Modellen er for stor til din tilgængelige RAM/VRAM
- Du kører udelukkende på CPU, selvom GPU-acceleration er tilgængelig
- Du har valgt en høj kontekstlængde, og det sluger hukommelse
- Din lagerplads er fyldt (ja, det betyder noget)
PRODUKTER I ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.