Eseguire un modello linguistico di grandi dimensioni (LLM) sul proprio PC può sembrare intimidatorio, ma in realtà è sorprendentemente accessibile. Un "LLM locale" significa semplicemente che l'IA viene eseguita sul proprio hardware, senza cloud né account, e i dati rimangono al sicuro. Pensate a brainstorming privati, assistenza per il codice e domande e risposte sui documenti, il tutto senza inviare nulla online. Se l'idea vi piace, passiamo dalla teoria alla pratica.
Quali strumenti utilizziamo?
L'opzione più adatta ai principianti al momento è Ollama, un'app gratuita che scarica ed esegue un ampio catalogo di modelli aperti con comandi di una sola riga (ora include un'app desktop per Windows e macOS, quindi non è necessario vivere in un terminale).
Se preferisci un'esperienza più visiva e completa, LM Studio (anch'esso gratuito) è un'altra ottima scelta per scoprire, eseguire e gestire modelli locali. Open WebUI è un'interfaccia di chat leggera e self-hosted che può essere integrata in Ollama. Scegli uno o combinali a tuo piacimento.


Cosa ti serve (hardware e sistema operativo)
- Sistema operativo: Windows 10/11, macOS o Linux (di seguito mostreremo alcuni esempi relativi a Windows).
- Memoria e archiviazione: 16-32 GB di RAM sono sufficienti per modelli con 7-13 miliardi di parametri; una maggiore quantità di RAM è utile per contesti più grandi. Lascia decine di GB liberi su un SSD per modelli e cache.
- GPU (opzionale ma utile): una GPU moderna velocizza le operazioni e consente di eseguire modelli più grandi. Su Windows, Ollama supporta l'accelerazione GPU e pubblica build ottimizzate per AMD.
- Nota sulla grafica integrata AMD (APU): i nuovi sistemi Ryzen AI Max+ possono condividere la memoria di sistema come "memoria grafica variabile", esponendo fino a 96 GB di VRAM all'iGPU con la giusta configurazione, utile per modelli più grandi a casa.
Avvio rapido (Windows): il percorso più veloce per il tuo primo prompt
- Installa Ollama
- Scarica il programma di installazione per Windows da Ollama oppure installa tramite Winget: "winget install --id Ollama.Ollama"
Dopo l'installazione, avrai sia l'app Ollama (GUI) che lo strumento da riga di comando.
- Avvia e verifica
- Apri l'applicazione desktop Ollama ed effettua l'accesso se richiesto (non è necessario il cloud per l'utilizzo locale).
- Oppure verifica la CLI: "ollama --version". (Verrà visualizzato il numero di versione.)
- Tirare un modello iniziale
- Nell'app, cerca e scarica un modello. Oppure in un terminale: "ollama run llama3:8b
- "Questo scaricherà il modello e ti porterà a una finestra di dialogo: digita una domanda e procedi. Puoi sfogliare molti modelli (Gemma, Llama, Qwen, OLMo e altri) nella libreria Ollama.
- (Facoltativo) Abilita l'accelerazione GPU
- Mantieni aggiornati i driver grafici. Ollama fornisce build Windows con accelerazione AMD e AMD documenta i percorsi DirectML/ROCm per LLM su Radeon. Nell'app Ollama, verifica che la GPU sia stata rilevata (oppure controlla l'utilizzo della GPU in Task Manager durante la generazione).
Quale modello dovresti provare per primo?
- "Piccolo e scattante": gemma3:1b o llama3:8b ottimo per risposte rapide e hardware di fascia bassa.
- "Bilanciato": modelli 7B-13B (ad esempio, olmo2:7b, llama3:8b instruct) solidi per uso generico.
- "Cervelli più grandi": i modelli da oltre 20 miliardi (ad esempio, gpt-oss:20b, varianti Llama più grandi) richiedono più RAM/VRAM e pazienza, ma eccellono nei compiti più difficili. È possibile richiamarli direttamente nell'app o tramite ollama run <model>.
Suggerimenti per ottimizzare il tuo LLM locale
- Lunghezza del contesto: più grande non significa sempre migliore. Contesti molto grandi (ad esempio, 32k-64k token) possono rallentare notevolmente la generazione. Inizia con 4k-8k e aumenta solo quando necessario.
- Quantizzazione: la maggior parte dei modelli forniti dall'app sono già quantizzati, il che è utile per adattare modelli più grandi a una VRAM limitata.
- Archiviazione: conservare i modelli su un SSD; gli HDD risulteranno lenti.
- Driver: aggiornare regolarmente i driver della GPU e l'app L'intelligenza artificiale locale si sta evolvendo rapidamente.
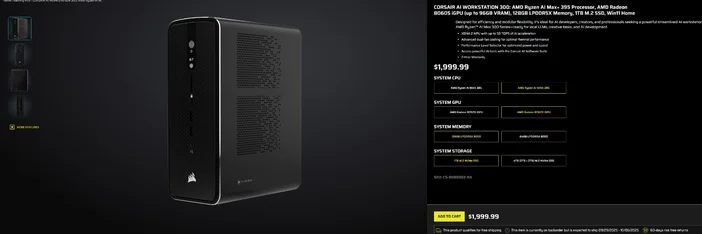
Utilizzo della CORSAIR AI WORKSTATION 300
Se preferisci evitare l'assemblaggio pezzo per pezzo e desideri un desktop compatto e silenzioso, pronto all'uso per gli LLM locali, il CORSAIR AI WORKSTATION 300 soddisfa molte delle esigenze di creatori e sviluppatori:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (fino a 96 GB di VRAM), XDNA 2 NPU fino a 50 TOPS
- Memoria e archiviazione: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB+2 TB)
- Sistema operativo: Windows 11 Home
- Design: telaio compatto da 4,4 litri con raffreddamento a doppia ventola e selettore del livello di prestazioni
La "VRAM fino a 96 GB" dell'iGPU Radeon si abbina particolarmente bene agli strumenti Windows in grado di allocare una grande quantità di memoria condivisa alla GPU, utile per modelli locali più grandi e contesti più lunghi quando necessario. Si tratta di un percorso pulito e compatto verso lo sviluppo dell'IA locale senza compromettere la capacità.
Domande frequenti
Ho bisogno di una GPU dedicata per eseguire un LLM locale?
No. È possibile eseguire modelli più piccoli su sistemi basati esclusivamente su CPU, ma le risposte saranno più lente. Una GPU moderna o un APU avanzato con una grande memoria condivisa migliorano la velocità e consentono di aumentare le dimensioni del modello.
È una conversazione privata?
Sì. Con strumenti locali come Ollama o LM Studio, i prompt e i dati rimangono sul tuo computer per impostazione predefinita. (Le integrazioni che aggiungi potrebbero comportarsi in modo diverso, controlla sempre le impostazioni.)
Dove posso trovare i modelli?
La libreria Ollama elenca le opzioni più popolari e aggiornate (Llama, Gemma, Qwen, OLMo e altre). Ogni pagina del modello mostra le dimensioni e alcuni comandi di esempio.
La CORSAIR AI WORKSTATION 300 è in grado di gestire modelli di grandi dimensioni?
È progettato per LLM locali, con 128 GB di memoria e una iGPU in grado di accedere fino a 96 GB di VRAM, un eccellente margine di manovra per carichi di lavoro locali avanzati e contesti lunghi, soprattutto ora che i driver Windows di AMD ampliano il supporto per allocazioni di grandi dimensioni. Il throughput effettivo dipende dalle dimensioni del modello, dalla quantizzazione e dalle impostazioni.
PRODOTTI DELL'ARTICOLO