HOW TO
CPU ou GPU pour l'IA locale : qu'est-ce qui la rend réellement plus rapide ?
Dernière mise à jour :
Si vous utilisez l'IA en local, vous avez sans doute déjà entendu ce conseil : « procurez-vous un bon GPU ». Mais qu'est-ce que cela signifie concrètement ? Et votre CPU est-il vraiment si inefficace ? La réponse ne se résume pas simplement à « GPU = bien, CPU = mal ». Ce qui importe, c'est la manière dont chaque processeur gère les calculs mathématiques qui sous-tendent l'inférence IA, et lequel est capable de transférer les données assez rapidement pour suivre le rythme.
Que se passe-t-il réellement lors d'une inférence IA ?
Lorsque vous exécutez un modèle LLM ou un modèle d'image local, votre matériel effectue sans cesse la même opération : la multiplication matricielle. Le modèle prend vos données d'entrée, les convertit en chiffres, puis soumet ces chiffres à des milliards d'opérations mathématiques à travers ses différentes couches. Plus votre matériel est capable d'effectuer ces opérations rapidement, plus vous obtenez une réponse rapidement.
Il s'agit d'une inférence, c'est-à-dire de la génération d'un résultat à partir d'un modèle entraîné. Vous n'entraînez rien. Vous ne faites qu'appliquer les calculs, un token à la fois.
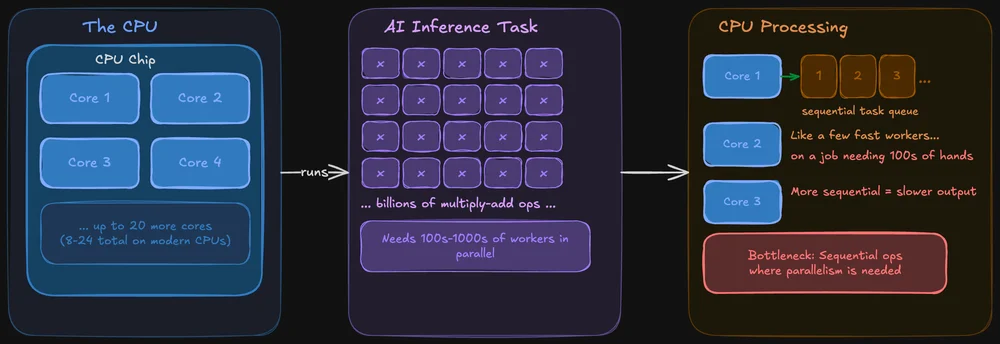
Comment un processeur gère les tâches d'IA
Un processeur est conçu pour exceller dans tous les domaines. Il gère votre système d'exploitation, les onglets de votre navigateur, votre système de fichiers et, bien sûr, il peut également exécuter des modèles d'IA. Les processeurs modernes sont dotés de plusieurs cœurs (généralement entre 8 et 24 sur les puces grand public), et chaque cœur est puissant et polyvalent.
Le problème : l'inférence IA consiste à effectuer simultanément la même opération sur d'énormes quantités de données. Un processeur (CPU) en est capable, mais il traite ces opérations de manière plus séquentielle. C'est un peu comme si l'on comptait sur quelques ouvriers très rapides pour accomplir une tâche qui nécessiterait en réalité des centaines de personnes travaillant de front.
Cela dit, les processeurs ne sont pas pour autant hors jeu pour l'IA locale. Des outils comme llama.cpp sont spécialement optimisés pour l'inférence sur processeur, et si votre modèle tient dans la mémoire vive de votre système, vous pouvez tout à fait l'exécuter uniquement sur le processeur. Le traitement sera simplement plus lent, parfois de manière perceptible, parfois non, selon la taille du modèle.
Comment un GPU traite les tâches d'IA
Un GPU est conçu pour le parallélisme. Alors qu'un CPU peut compter entre 8 et 24 cœurs, un GPU moderne en possède des milliers, tous plus petits, qui peuvent traiter simultanément différentes parties d'un même problème. Cela rend les GPU particulièrement performants pour le type de calculs intensifs dont dépendent les modèles d'IA.
De plus, les GPU disposent de leur propre mémoire dédiée (VRAM) dont la bande passante est bien supérieure à celle de la mémoire vive du système. Cette bande passante est d'une importance capitale, car elle détermine la vitesse à laquelle les données peuvent être transmises à ces milliers de cœurs. Une bande passante plus élevée signifie moins de temps d'attente et plus de temps de calcul.
En ce qui concerne plus particulièrement l'inférence locale des modèles de langage (LLM), l'avantage du GPU repose sur deux éléments : la puissance de traitement parallèle et la bande passante mémoire. Ces deux facteurs influent directement sur le nombre de tokens par seconde que vous obtiendrez en sortie.
Bande passante mémoire
Voici un fait qui surprend la plupart des gens : pour l'inférence locale des modèles de langage (LLM), ce n'est souvent pas la puissance de calcul brute qui constitue le facteur limitant, mais bien la bande passante mémoire.
Lors de l'inférence, les poids du modèle doivent être lus en mémoire pour chaque token généré. Si votre mémoire ne parvient pas à fournir les données au processeur assez rapidement, peu importe le nombre de cœurs dont vous disposez : ils resteront simplement inactifs à attendre.
C'est pourquoi la bande passante de la VRAM revêt une telle importance. Une configuration classique de mémoire système DDR5 peut offrir une bande passante comprise entre 50 et 90 Go/s. Un GPU moderne comme le RTX 5090 offre quant à lui plus de 1 000 Go/s. Il s'agit là d'un écart d'un ordre de grandeur.
Si votre modèle tient entièrement dans la mémoire vidéo (VRAM), l'inférence sera presque toujours plus rapide sur le GPU que sur le CPU, ne serait-ce que pour cette raison.
Quand le mode « CPU-Only » est vraiment judicieux
Le GPU n'est pas toujours la solution. Il existe des cas concrets où il est préférable d'utiliser le CPU :
- Vous utilisez un petit modèle (3B paramètres ou moins) pour lequel la différence de vitesse est à peine perceptible.
- Vous ne disposez pas d'une carte graphique compatible, ou votre carte graphique ne dispose pas d'une mémoire vidéo suffisante pour prendre en charge le modèle.
- Vous souhaitez utiliser toute la mémoire vive de votre système (qui est généralement bien plus importante que la mémoire vidéo) pour faire tourner un modèle plus volumineux à une vitesse réduite.
- Vous utilisez un ordinateur portable ou un système pour lequel la consommation électrique ou la chaleur générée par le processeur graphique constituent un problème.
Les performances de l'inférence sur CPU se sont considérablement améliorées grâce à la quantification (qui réduit la précision du modèle pour utiliser moins de mémoire) et aux frameworks optimisés pour cette technique. Un modèle quantifié de 7 milliards de paramètres, exécuté sur un CPU moderne doté de 32 Go de RAM, fonctionne suffisamment bien pour de nombreuses tâches.


Qu'en est-il de l'externalisation ?
Si votre modèle est trop volumineux pour la mémoire VRAM mais que vous souhaitez tout de même bénéficier de l'accélération GPU, la plupart des outils LLM locaux prennent en charge le déchargement partiel. Cela signifie que certaines couches du modèle s'exécutent sur le GPU tandis que les autres s'exécutent sur le CPU.
C'est un compromis : on bénéficie en partie de la vitesse du GPU, mais les couches dépendantes du CPU deviennent un goulot d'étranglement. Plus on peut faire tenir de couches dans la VRAM, plus le processus sera rapide. Et si seules quelques couches se retrouvent sur le GPU, la charge liée au transfert des données dans les deux sens pourrait en réalité rendre le processus plus lent qu'une inférence purement CPU.
En gros, si vous ne pouvez pas faire tenir au moins la moitié du modèle dans la mémoire vidéo (VRAM), vous feriez sans doute mieux de le faire tourner entièrement sur le processeur (CPU) et de vous épargner ainsi des complications.
NVIDIA contre AMD dans le domaine de l'IA locale
NVIDIA domine actuellement le marché local de l'IA, principalement grâce à CUDA, son framework de calcul propriétaire sur lequel reposent pratiquement tous les outils d'IA. Si vous utilisez LM Studio, Ollama ou llama.cpp sous Windows, les GPU NVIDIA vous offriront une expérience fluide et vous éviteront bien des soucis.
AMD rattrape son retard. ROCm (la réponse d'AMD à CUDA) a fait de réels progrès, et des outils comme Ollama prennent explicitement en charge les GPU AMD Radeon sous Windows. Mais l'écosystème reste encore plus limité, et vous risquez de rencontrer des problèmes de compatibilité selon votre GPU et l'outil que vous utilisez.
Si vous achetez spécifiquement pour l'IA locale, NVIDIA est aujourd'hui le choix le plus sûr. Si vous possédez déjà un GPU AMD, cela vaut vraiment la peine d'essayer ; vérifiez simplement au préalable la documentation de votre outil pour connaître les modèles pris en charge.

À quoi sert le CORSAIR AI300 ?
Si votre configuration actuelle vous pose des problèmes de goulot d'étranglement, qu'il s'agisse d'un manque de mémoire vidéo, d'une bande passante mémoire insuffisante ou d'un système qui surchauffe dès que vous chargez un modèle de 13 milliards de polygones, c'est précisément le genre de problème que la CORSAIR AI Workstation 300 (AI300) a été conçue pour résoudre.
L'AI300 est une station de travail compacte conçue pour répondre aux réalités de l'inférence IA locale :
- Configuration à grande capacité de mémoire permettant d'afficher des modèles plus volumineux et des fenêtres de contexte plus grandes.
- Une mémoire graphique conçue pour s'adapter aux charges de travail liées à l'IA (et, dans une moindre mesure, aux jeux).
- Un sélecteur de performances au niveau matériel (Silencieux / Équilibré / Max) qui vous permet de privilégier la vitesse lorsque vous en avez besoin et le silence lorsque ce n'est pas le cas.
- La suite logicielle CORSAIR AI, qui simplifie la mise en place afin que vous passiez moins de temps à configurer et plus de temps à exécuter vos modèles.
Si vous avez essayé jusqu'à présent d'intégrer l'IA locale dans un système qui n'était pas conçu pour cela, l'AI300 vous offre une machine dont le matériel et les logiciels sont véritablement conçus pour répondre à cette charge de travail.

PRODUITS DANS L'ARTICLE
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.