Googleは、これまでで最も高性能なオープンウェイトモデルファミリー「Gemma 4」をリリースしました。これは、一般的なハードウェア上でAIをローカルに実行しているユーザーにとって、非常に大きなニュースです。2026年3月31日に完全に許容的なApache 2.0ライセンスの下でリリースされたGemma 4は、サブスクリプション契約を必要とせず、一般向けのGPUやノートパソコンでも最先端レベルの知能を提供できるように設計されています。
ラインナップは4つのサイズで構成されています。E2B(有効パラメータ数23億)、E4B(有効パラメータ数45億)、アクティブパラメータ数がわずか4億の26B Mixture-of-Experts(MOE)モデル、そして31Bの密モデルです。これにより、エッジコンピューティングに適したモデルから最先端に近いモデルまで、1つのファミリーで網羅されており、そのすべてが、PCビルダーがすでに組み立てているようなマシン上で動作します。

Gemma 4の特長
Gemma 4は単に大きくなっただけでなく、パラメータごとの性能も向上しています。主な特徴をいくつかご紹介します:
- 高度な推論とエージェント:多段階計画、数学、コーディング、そしてすぐに使える自律的なワークフロー。
- マルチモーダル:テキストと画像をネイティブで処理し、小型モデルのE2BおよびE4Bでは音声にも対応しています。ドキュメントの解析、図表の認識、手書き文字のOCRが、すべて1つのプロンプトで実行可能です。
- 大規模なコンテキスト:E2B/E4B向けには128Kトークン、26B MoEおよび31Bの密モデル向けには256Kトークンをフルに活用でき、コードベース全体や大量のドキュメントを丸ごと読み込める十分な容量を備えています。
- 多言語対応:140以上の言語でトレーニングされており、そのうち数十の言語については、導入直後から強力なサポートを提供します。
Hugging Faceでは、事前学習済みおよび指示チューニング済みのバリエーションが提供されており、Ollama、LM Studio、llama.cpp、vLLM、Transformersなど、すでに使用しているツールと導入初日から連携して動作します。
なぜコンシューマー向けPCがGemma 4の最適なターゲット市場なのか
Gemma 4は、ローカル推論を第一級のターゲットとして設計されており、その効果は数値データによって裏付けられています。NVIDIAとGoogleはRTXカード向けの「Day-Zero」最適化で協力しており、最近のllama.cppの改良により、長文コンテキストのシナリオにおいてKVキャッシュのメモリ使用量が40%近く削減されました。
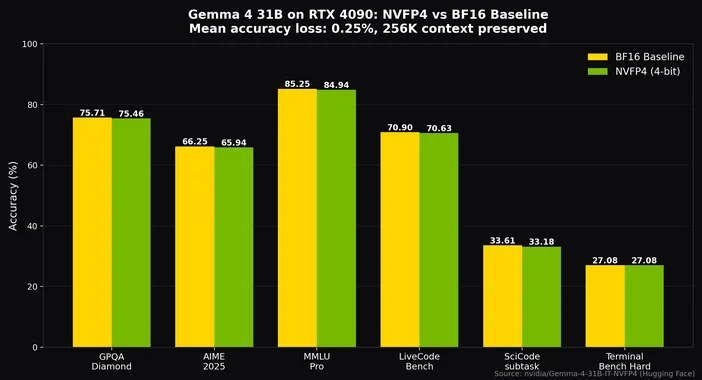
多くの構成において最適な設定であるQ4_K_M量子化を使用すれば、RTX 4090や3090のような24GBのグラフィックカードに260億のMoEを収容でき、8Kトークンのコンテキストを保持したまま、毎秒20トークンをはるかに超える処理性能を実現できます。 NVIDIAのNVFP4量子化を使用すれば、310億パラメータの密モデルであっても、256Kのコンテキストを完全に維持しつつ、精度の低下をわずか0.25%程度に抑えながら、単一のRTX 4090に収めることができます。
クイックビルドガイド
E2B / E4B(エッジおよび低遅延):VRAMが8GBまたは12GBのRTX 3060または4060と、最新のRyzen 5またはCore i5であれば十分です。長時間連続して使用する予定がある場合は、32GBのDDR5メモリと静音型のオールインワン水冷クーラーを組み合わせると良いでしょう。
26B MoE / 31B dense(推論およびマルチモーダル向け):RTX 4090(すでに所有している場合は3090)、Ryzen 7 / Core i7 以上、64GBのDDR5メモリ、モデル読み込み用の高速Gen4 NVMe、そして通気性の良いケースに850W以上の電源ユニットを搭載することを目指してください。 CORSAIR iCUE LINK TITAN RX RGB 360mm AIOのような製品を使用すれば、持続的な推論負荷下でもGPUとCPUを良好な状態に保てます。

RTX 50シリーズにより、Gemma 4はより大規模なコンテキストや高速な推論に対応するためのさらなる余力を得ることができます。
PCでのクイックスタート
1. Ollama または LM Studio をインストールします。
2. Hugging FaceからGemma 4モデルを取得します(初めての方はgemma4:e4bから、VRAMに余裕がある方はgemma4:31bから始めてください)。
3. 推論を実行すると、RTX 40シリーズの小型モデルでは、1秒あたり50~100トークン以上の処理が期待できます。
4. マルチモーダル機能を試してみましょう:画像とプロンプトを入力して、スクリーンショットやグラフ、写真を分析させてみてください。
Gemma 4 オンデバイス:モバイル対応も実現
Gemma 4のエッジコンピューティング機能はスマートフォンにも拡張されています。より小型のE2BおよびE4BモデルはArm製CPUとモバイルGPUを搭載しており、音声認識、画像解析、デバイス内アシスタントにおいて、クラウドを必要とせず、ほぼゼロのレイテンシーを実現します。GoogleのAIエッジスタックとAndroid AICoreにより、Androidではシステム全体で利用可能となり、iOS開発者はMetalを介してCPUとGPUを活用できます。
Gemma 4は、ハイエンドのコンシューマー向けPCが単なるゲーミングマシンではなく、本格的なAIワークステーションであることを示す、これまでで最も明確な証拠です。オープンな重み付け、寛容なライセンス、最先端レベルの推論能力、そして単一のGPUに実際に収まる256Kのコンテキストウィンドウを備えています。すでに最新のCORSAIR製PCをお持ちであれば、本格的なローカルAIワークステーションへの道のりはほぼ整っていると言えます。 これから構成を計画しているなら、24GBのグラフィックカード、64GBのDDR5メモリ、そして長時間の負荷下でも動じない水冷システムを軸に考えてください。

Gemmaをローカル環境で実行したいですか? CORSAIR AI Workstation 300をご紹介します
Gemma 4(およびその他のオープンソースモデル)を、一切の妥協なく自前のハードウェア上で実行したいのであれば、CORSAIR AI Workstation 300はまさにそのために設計された製品です。 AMD Ryzen AI Max+ 395とRadeon 8060S iGPUを組み合わせ、128GBのLPDDR5X-8000メモリのうち最大96GBを統合VRAMとして割り当てることで、ディスクへのページングを行うことなく、大規模なGemmaのバリエーションをローカルで読み込み、微調整するための十分な余裕を確保しています。 専用の50 TOPS NPUが推論を高速化し、システム全体はデスク上に置ける4.4Lの筐体に収まります。プライバシー、低遅延、トークンごとのコストゼロを求める開発者や研究者にとって、Gemmaを活用する最良の方法の一つと言えるでしょう。
記事内の製品
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.