BLOG
Gemma 4: Googles neues offenes Modell und warum es auf Consumer-PCs am besten läuft
Letzte Aktualisierung:
Google hat gerade Gemma 4 veröffentlicht, seine bislang leistungsstärkste Modellfamilie mit offenen Gewichten, und das ist eine große Sache für alle, die KI lokal auf handelsüblicher Hardware betreiben. Gemma 4 wurde am 31. März 2026 unter einer vollständig freigebenen Apache-2.0-Lizenz veröffentlicht und wurde entwickelt, um auf handelsüblichen GPUs und sogar Laptops Spitzenleistung zu liefern – ganz ohne Abonnement.
Die Produktpalette umfasst vier Größen: E2B (2,3 Milliarden effektive Parameter), E4B (4,5 Milliarden effektive Parameter), eine „Mixture-of-Experts“-Variante mit 26 Milliarden Parametern und nur 4 Milliarden aktiven Parametern sowie ein dichtes Modell mit 31 Milliarden Parametern. Damit steht Ihnen in einer einzigen Produktfamilie alles zur Verfügung – von Edge-tauglichen bis hin zu fast topaktuellen Modellen –, und all das läuft auf PCs, wie sie PC-Bauer bereits zusammenstellen.

Was Gemma 4 so besonders macht
Gemma 4 ist nicht nur größer, sondern auch leistungsfähiger in jeder Hinsicht. Hier einige Highlights:
- Fortgeschrittene Schlussfolgerungen und Agenten: Mehrstufige Planung, Mathematik, Programmierung und autonome Arbeitsabläufe – sofort einsatzbereit.
- Multimodal: Verarbeitet Text und Bilder nativ, wobei die kleineren Varianten E2B und E4B auch Audio unterstützen. Dokumentenanalyse, Diagrammerkennung und Handschrift-OCR funktionieren alle über eine einzige Eingabeaufforderung.
- Umfangreicher Kontext: 128.000 Token für E2B/E4B und ganze 256.000 Token für die 26B-MoE- und 31B-Dense-Modelle – genug, um eine komplette Codebasis oder einen Stapel Dokumente einzufügen.
- Mehrsprachig: Auf über 140 Sprachen trainiert, mit umfassender Standardunterstützung für Dutzende davon.
Es wird auf Hugging Face in vortrainierten und an bestimmte Anweisungen angepassten Varianten bereitgestellt und ist vom ersten Tag an mit den Tools kompatibel, die Sie bereits nutzen: Ollama, LM Studio, llama.cpp, vLLM und Transformers.
Warum Verbraucher-PCs die Kernkompetenz von Gemma 4 sind
Gemma 4 wurde mit dem Schwerpunkt auf lokaler Inferenz entwickelt, und die Zahlen belegen dies. NVIDIA und Google haben gemeinsam an Optimierungen für RTX-Karten gearbeitet, die sofort einsatzbereit sind, und dank der jüngsten Arbeiten an llama.cpp konnte der KV-Cache-Speicherverbrauch in Szenarien mit langen Kontexten um fast 40 % gesenkt werden.
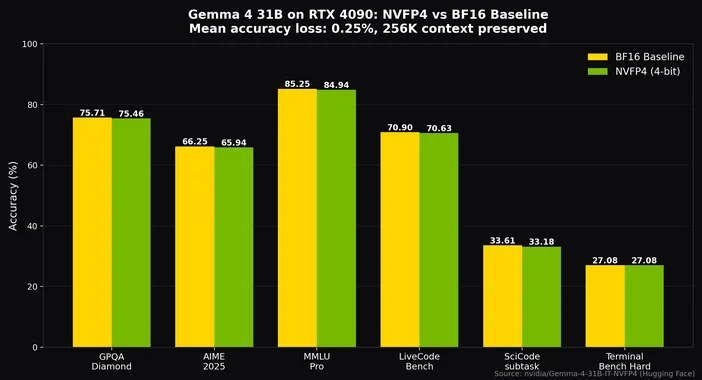
Mit der Q4_K_M-Quantisierung, dem optimalen Kompromiss für die meisten Builds, lässt sich das 26-Milliarden-MoE-Modell auf eine 24-GB-Karte wie eine RTX 4090 oder 3090 packen, wobei noch Platz für einen 8K-Token-Kontext bleibt, und dennoch eine Leistung von deutlich über 20 Token pro Sekunde erzielen. Mit der NVFP4-Quantisierung von NVIDIA passt sogar das 31B-Dense-Modell auf eine einzige RTX 4090 mit nur ~0,25 % Genauigkeitsverlust, während der volle 256K-Kontext erhalten bleibt.
Eine Kurzanleitung zum Bauen
E2B / E4B (Edge und niedrige Latenz): Eine RTX 3060 oder 4060 mit 8 oder 12 GB VRAM und einem modernen Ryzen 5 oder Core i5 reicht völlig aus. Kombinieren Sie das System mit 32 GB DDR5 und einem leisen All-in-One-Kühlsystem, wenn Sie längere Sitzungen planen.
26B MoE / 31B Dense (für Inferenz und multimodale Anwendungen): Entscheiden Sie sich für eine RTX 4090 (oder 3090, falls Sie bereits eine besitzen), einen Ryzen 7 / Core i7 oder besser, 64 GB DDR5, eine schnelle Gen4-NVMe-Festplatte zum Laden von Modellen und ein Netzteil mit mindestens 850 W in einem Gehäuse mit guter Luftzirkulation. Ein System wie das CORSAIR iCUE LINK TITAN RX RGB 360 mm AIO sorgt dafür, dass GPU und CPU auch unter anhaltender Inferenzlast gut gekühlt bleiben.

Die RTX 50-Serie bietet Gemma 4 noch mehr Leistungsreserven für umfangreichere Kontexte und schnellere Inferenz.
Schnellstart auf Ihrem PC
1. Installieren Sie Ollama oder LM Studio.
2. Lade ein Gemma-4-Modell von Hugging Face herunter (beginne mit „gemma4:e4b“, wenn du neu bist, oder mit „gemma4:31b“, wenn du über genügend VRAM verfügst).
3. Führen Sie die Inferenz aus und rechnen Sie bei den kleineren Modellen der RTX-40-Serie mit 50 bis über 100 Token pro Sekunde.
4. Probieren Sie die multimodale Funktion aus: Laden Sie ein Bild und eine Eingabeaufforderung hoch und lassen Sie das System einen Screenshot, ein Diagramm oder ein Foto analysieren.
Gemma 4 On-Device: Jetzt auch mobil
Der Edge-Fokus von Gemma 4 erstreckt sich auch auf Smartphones. Die kleineren Varianten E2B und E4B laufen auf Arm-CPUs und mobilen GPUs und bieten nahezu latenzfreie Sprach- und Bildanalyse sowie geräteinterne Assistenten – ganz ohne Cloud. Dank Googles AI Edge Stack und Android AICore ist dies systemweit auf Android verfügbar, und iOS-Entwickler können über Metal auf CPU und GPU zugreifen.
Gemma 4 ist das bislang deutlichste Zeichen dafür, dass High-End-PCs für Endverbraucher nicht nur Gaming-Rechner sind, sondern echte KI-Workstations. Offene Gewichtung, eine freizügige Lizenz, Schlussfolgerungen auf Spitzenniveau und ein 256-KB-Kontextfenster, das tatsächlich auf eine einzige GPU passt. Wenn Sie bereits einen modernen CORSAIR-PC besitzen, haben Sie den größten Teil des Weges zu einer vollwertigen lokalen KI-Workstation bereits zurückgelegt. Wenn Sie gerade einen zusammenstellen, planen Sie eine 24-GB-Karte, 64 GB DDR5 und einen Kühlkreislauf ein, der auch unter Dauerbelastung nicht ins Stocken gerät.

Möchten Sie Gemma lokal ausführen? Lernen Sie die CORSAIR AI Workstation 300 kennen
Wenn Sie Gemma 4 (und andere offene Modelle) ohne Kompromisse vollständig auf Ihrer eigenen Hardware ausführen möchten, ist die CORSAIR AI Workstation 300 genau dafür konzipiert. Sie kombiniert einen AMD Ryzen AI Max+ 395 mit der Radeon 8060S iGPU und bis zu 96 GB einheitlichem VRAM aus 128 GB LPDDR5X-8000-Speicher, was Ihnen genügend Spielraum bietet, um große Gemma-Varianten lokal zu laden und zu optimieren, ohne auf die Festplatte auslagern zu müssen. Eine dedizierte 50-TOPS-NPU beschleunigt die Inferenz, und das gesamte System passt in ein 4,4-Liter-Gehäuse, das Sie auf Ihren Schreibtisch stellen können. Für Entwickler und Forscher, die Wert auf Datenschutz, geringe Latenz und keine Kosten pro Token legen, ist dies eine der besten Möglichkeiten, Gemma einzusetzen.
PRODUKTE IM ARTIKEL
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.