HOW TO
CPU contro GPU per l'IA locale: cosa la rende effettivamente più veloce?
Ultimo aggiornamento:
Se stai utilizzando l'intelligenza artificiale in locale, probabilmente ti sarà capitato di leggere il consiglio: «Procurati una buona GPU». Ma cosa significa in realtà? E la tua CPU è davvero così inutile? La risposta non è così semplice come «GPU buona, CPU cattiva». Ciò che conta è come ciascun processore gestisce i calcoli alla base dell'inferenza dell'IA e quale dei due è in grado di trasferire i dati con la rapidità necessaria per stare al passo.
Cosa succede realmente durante l'inferenza dell'IA?
Quando si esegue un modello LLM o un modello di elaborazione delle immagini locale, l'hardware esegue ripetutamente un'unica operazione: la moltiplicazione di matrici. Il modello prende i dati in ingresso, li converte in numeri e li sottopone a miliardi di operazioni matematiche attraverso i suoi livelli. Più velocemente l'hardware è in grado di elaborare queste operazioni, più velocemente si ottiene una risposta.
Si tratta di inferenza, ovvero della generazione di risultati da un modello addestrato. Non stai addestrando nulla. Stai semplicemente eseguendo il calcolo in avanti, un token alla volta.
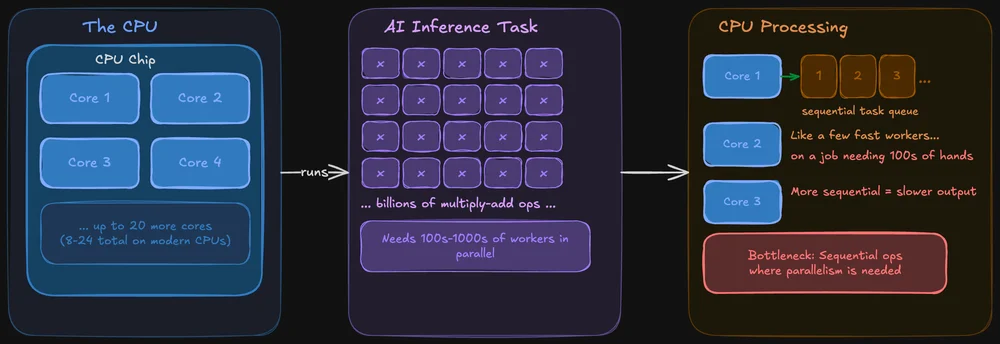
Come una CPU gestisce i compiti di intelligenza artificiale
Una CPU è progettata per eccellere in ogni ambito. Gestisce il sistema operativo, le schede del browser, il file system e, sì, è in grado anche di eseguire modelli di intelligenza artificiale. Le CPU moderne dispongono di più core (in genere da 8 a 24 nei chip destinati al mercato consumer) e ogni core è potente e flessibile.
Il problema: l'inferenza dell'IA comporta l'esecuzione simultanea della stessa operazione su enormi quantità di dati. Una CPU è in grado di farlo, ma elabora tali operazioni in modo più sequenziale. È come avere pochi lavoratori molto veloci che si occupano di un lavoro che richiederebbe in realtà centinaia di persone all'opera contemporaneamente.
Detto questo, le CPU non sono del tutto inadatte all'IA locale. Strumenti come llama.cpp sono ottimizzati specificatamente per l'inferenza su CPU e, se il modello rientra nella RAM di sistema, è assolutamente possibile eseguirlo solo sulla CPU. Sarà semplicemente più lento: a volte in modo evidente, altre volte meno, a seconda delle dimensioni del modello.
Come una GPU gestisce i compiti di intelligenza artificiale
Una GPU è progettata per il parallelismo. Mentre una CPU può avere da 8 a 24 core, una GPU moderna dispone di migliaia di core più piccoli, in grado di lavorare contemporaneamente su parti dello stesso problema. Ciò rende le GPU particolarmente adatte al tipo di elaborazioni matematiche su larga scala da cui dipendono i modelli di IA.
Inoltre, le GPU dispongono di una memoria dedicata (VRAM) con una larghezza di banda molto superiore rispetto alla RAM di sistema. Questa larghezza di banda è fondamentale, poiché determina la velocità con cui i dati possono essere inviati a quelle migliaia di core. Una maggiore larghezza di banda comporta tempi di attesa ridotti e più tempo dedicato all'elaborazione.
Per quanto riguarda nello specifico l'inferenza dei modelli di linguaggio locale (LLM), il vantaggio offerto dalla GPU si riduce a due aspetti: la potenza di elaborazione parallela e la larghezza di banda della memoria. Entrambi influenzano direttamente il numero di token al secondo che si otterrà nell'output.
Larghezza di banda della memoria
Ecco un fatto che sorprende molti: quando si tratta di inferenza LLM locale, spesso la potenza di calcolo pura non è il fattore limitante. Lo è invece la larghezza di banda della memoria.
Durante l'inferenza, i pesi del modello devono essere letti dalla memoria per ogni singolo token generato. Se la memoria non è in grado di fornire dati al processore con sufficiente rapidità, non importa quanti core si abbiano: rimarranno semplicemente inattivi in attesa.
Ecco perché la larghezza di banda della VRAM è così importante. Una configurazione tipica della memoria di sistema DDR5 può offrire una larghezza di banda compresa tra 50 e 90 GB/s. Una GPU moderna come l'RTX 5090 offre invece oltre 1.000 GB/s. Si tratta di una differenza di un ordine di grandezza.
Se il tuo modello rientra interamente nella VRAM, l'inferenza sarà quasi sempre più veloce sulla GPU che sulla CPU, già solo per questo motivo.
Quando l'uso esclusivo della CPU ha davvero senso
La GPU non è sempre la soluzione giusta. Esistono casi concreti in cui è preferibile utilizzare la CPU:
- Stai utilizzando un modello di piccole dimensioni (con 3B parametri o meno) in cui la differenza di velocità è quasi impercettibile.
- Non disponi di una GPU compatibile oppure la tua GPU non dispone di VRAM sufficiente per caricare il modello.
- Vuoi utilizzare tutta la RAM del sistema (che di solito è molto più capiente della VRAM) per eseguire un modello più grande a una velocità inferiore.
- Stai utilizzando un portatile o un sistema in cui il consumo energetico o il surriscaldamento della GPU rappresentano un problema.
Le prestazioni di inferenza su CPU sono notevolmente migliorate grazie alla quantizzazione (riduzione della precisione del modello per ridurre l'utilizzo di memoria) e ai framework ottimizzati per questo scopo. Un modello quantizzato da 7 miliardi di parametri su una CPU moderna con 32 GB di RAM funziona in modo soddisfacente per molte attività.


E l'offloading?
Se il tuo modello è troppo grande per la VRAM ma desideri comunque l'accelerazione GPU, la maggior parte degli strumenti LLM locali supporta l'offloading parziale. Ciò significa che alcuni livelli del modello vengono eseguiti sulla GPU, mentre gli altri sulla CPU.
È un compromesso: si ottiene parte del vantaggio in termini di velocità offerto dalla GPU, ma i livelli che dipendono dalla CPU diventano un collo di bottiglia. Più livelli si riescono a far stare nella VRAM, maggiore sarà la velocità. E se solo pochi livelli finiscono sulla GPU, il sovraccarico dovuto allo spostamento dei dati avanti e indietro potrebbe addirittura renderla più lenta rispetto all'inferenza eseguita esclusivamente sulla CPU.
La regola generale è questa: se non riesci a caricare almeno metà del modello nella VRAM, probabilmente è meglio eseguirlo interamente sulla CPU e risparmiarti così ogni complicazione.
NVIDIA contro AMD nell'IA locale
Al momento NVIDIA domina il panorama locale dell'intelligenza artificiale, soprattutto grazie a CUDA, il proprio framework di calcolo su cui si basano quasi tutti gli strumenti di IA. Se utilizzi LM Studio, Ollama o llama.cpp su Windows, le GPU NVIDIA ti garantiranno un'esperienza fluida e con il minor numero di problemi.
AMD sta recuperando terreno. ROCm (la risposta di AMD a CUDA) ha compiuto progressi concreti e strumenti come Ollama supportano esplicitamente le GPU AMD Radeon su Windows. Tuttavia, l'ecosistema è ancora più limitato e potresti riscontrare problemi di compatibilità a seconda della tua GPU specifica e dello strumento che stai utilizzando.
Se stai acquistando specificatamente per l'IA locale, NVIDIA è oggi la scelta più sicura. Se possiedi già una GPU AMD, vale assolutamente la pena provarla, ma controlla prima la documentazione del tuo strumento per verificare quali modelli sono supportati.

Dove si inserisce il CORSAIR AI300
Se la tua configurazione attuale ti sta creando dei colli di bottiglia, che si tratti di VRAM insufficiente, larghezza di banda della memoria ridotta o di un sistema che si surriscalda non appena carichi un modello da 13 miliardi di poligoni, questo è proprio il tipo di problema che la CORSAIR AI Workstation 300 (AI300) è stata progettata per risolvere.
AI300 è una workstation compatta progettata per rispondere alle esigenze concrete dell'inferenza AI locale:
- Configurazione con memoria elevata, che consente di gestire modelli più complessi e finestre di contesto più ampie.
- Memoria grafica progettata per gestire carichi di lavoro di intelligenza artificiale (e qualche gioco).
- Un selettore delle prestazioni a livello hardware (Silenzioso / Bilanciato / Massimo) che ti permette di dare la priorità alla velocità quando ne hai bisogno e alla silenziosità quando non ne hai bisogno.
- La suite di software CORSAIR AI, che semplifica l'installazione consentendoti di dedicare meno tempo alla configurazione e più tempo all'esecuzione dei modelli.
Se hai cercato di ricavare funzionalità di IA locale da un sistema che non era stato progettato per questo scopo, AI300 ti offre una macchina in cui hardware e software sono stati effettivamente progettati appositamente per questo carico di lavoro.

PRODOTTI DELL'ARTICOLO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.