HOW TO
Come eseguire un modello LLM locale su Windows (senza bisogno del cloud)
Ultimo aggiornamento:
Eseguire un modello LLM in locale significa che il modello risiede sul tuo PC e che i tuoi prompt (e qualsiasi file tu gli fornisca) non devono uscire dal tuo computer. Nessun account cloud. Nessuna chiave API. Nessun «addestreremo il modello sui tuoi dati… probabilmente no… forse». Solo tu, il tuo PC e un modello che esegue qualsiasi compito tu gli assegni.
Che cos’è esattamente un “LLM locale”?
Un LLM locale è un modello linguistico di grandi dimensioni che funziona sul tuo computer anziché su un server remoto. In pratica, ciò significa solitamente che devi scaricare i file del modello, caricarli in un'app locale e interagire con essi proprio come faresti con un assistente cloud, con la differenza che il "server" è il tuo PC.
"Eseguire" un modello LLM in locale significa quasi sempre effettuare operazioni di inferenza (generare risposte), non addestrare un modello completamente nuovo partendo da zero.
Perché utilizzare un modello LLM locale?
Ci sono diversi motivi per cui le persone passano dai modelli di linguaggio su cloud a quelli locali:
- Privacy: i tuoi prompt rimangono sul dispositivo (a meno che non utilizzi i connettori cloud).
- Utilizzo offline: una volta scaricato il modello, è possibile utilizzarlo senza connessione a Internet.
- Nessun limite di utilizzo: nessun limite di velocità, nessun messaggio del tipo «Hai esaurito la quota giornaliera», nessuna fattura a sorpresa.
- Controllo: scegli il modello che preferisci, non sei vincolato a un abbonamento.
Ovviamente, si rinuncia alla praticità in cambio del controllo. Un modello cloud può sembrare una magia; un modello locale può sembrare una magia, a seconda dell’hardware che si utilizza.
Cosa serve per gestire un LLM locale?
In breve: la CPU fa il suo lavoro, la GPU dà una mano, la memoria è fondamentale.
Ecco cosa incide davvero sul fatto che ti divertirai o meno:
- RAM / VRAM: i modelli più grandi richiedono più memoria. Se la memoria si esaurisce, il modello non funzionerà.
- Spazio di archiviazione: i modelli possono essere di grandi dimensioni. Alcune librerie avvertono che lo spazio di archiviazione richiesto può variare da decine a centinaia di GB, a seconda del modello scaricato.
- GPU: se la tua app supporta la tua GPU, di solito noterai un notevole aumento della velocità.
Un computer moderno con Windows 10/11 dotato di almeno 32 GB di RAM rappresenta una solida base per i modelli locali di dimensioni ridotte, mentre una maggiore quantità di memoria consente di eseguire quelli più grandi in modo più fluido.
Scegli un'app "LLM runner locale"
LM Studio (interfaccia grafica intuitiva)
LM Studio è un'applicazione desktop che consente di scaricare modelli e chattare con loro in locale. Include inoltre un'API locale programmabile per gli sviluppatori.
Ollama (interfaccia a riga di comando semplice + API locale)
Ollama funziona come applicazione nativa per Windows e offre un flusso di lavoro da riga di comando oltre a un endpoint API HTTP locale. Supporta espressamente le GPU NVIDIA e AMD Radeon su Windows.
llama.cpp (per gli appassionati di programmazione)
Se desideri il massimo controllo, llama.cpp è un noto motore di inferenza open source che include istruzioni per la compilazione e diversi backend.

Installa ed esegui il tuo primo modello
I modelli più grandi richiedono più RAM e/o VRAM. Se non ne hai a sufficienza, potresti riscontrare un rallentamento delle prestazioni, arresti anomali o un continuo ricorso allo swap su disco (il che dà l'impressione che il PC funzioni a rilento).
Una regola empirica affidabile per i modelli quantizzati a int4:
- 8 GB di RAM → circa 3 miliardi di modelli
- 16 GB di RAM → circa 7 miliardi di modelli
- 32 GB di RAM → circa 13 miliardi di modelli
E se si fa affidamento sull'accelerazione GPU:
- 6 GB di VRAM → circa 3 miliardi di modelli
- 8 GB di VRAM → circa 7 miliardi di modelli
- 12 GB di VRAM → circa 13 miliardi di modelli
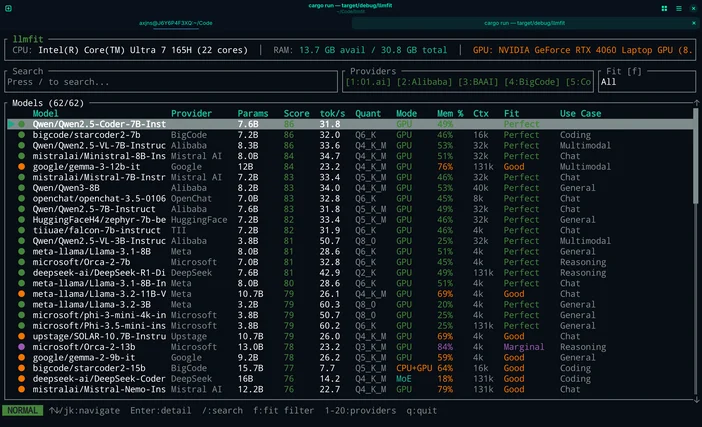
Oppure, se non vuoi andare a tentoni, puoi usare LLMfit per adattare i modelli al tuo hardware specifico.
LLMfit è uno strumento da terminale che rileva la CPU, la RAM e la GPU/VRAM del tuo computer, quindi classifica i modelli in base alla compatibilità, alla velocità prevista, al contesto e alla qualità, permettendoti dicapire quali funzioneranno bene prima ancora di scaricarli.
A cosa serve:
- Trovare modelli che rispettino effettivamente i limiti di RAM/VRAM
- Verifica della quantizzazione consigliata (per evitare un utilizzo eccessivo della memoria)
- Ottenere una selezione ordinata in base al punteggio anziché sfogliare all’infinito pagine piene di notizie negative
Come utilizzarlo in questo flusso di lavoro:
- Esegui llmfit per eseguire una scansione dell'hardware del sistema
- Guarda i "modelli adatti" / i suggerimenti in primo piano
- Scegli una dimensione del modello compatibile con la tua macchina, quindi scaricala su LM Studio / Ollama / llama
Il gioco è fatto!
Ecco fatto. Scegli un runner, scarica un modello compatibile con il tuo hardware e inizia a dare comandi! Tutto rimane sul tuo dispositivo. Non ti servono una laurea in informatica, un abbonamento al cloud o un fine settimana dedicato alla risoluzione dei problemi. L'intero processo richiede più o meno il tempo necessario per installare un gioco. E una volta avviato, avrai a disposizione un assistente IA privato e offline che funziona secondo le tue esigenze.
Dove si inserisce il CORSAIR AI300
Se hai davvero intenzione di utilizzare modelli di linguaggio di grandi dimensioni (LLM) in locale su Windows, soprattutto se desideri modelli più grandi, finestre di contesto più ampie o prestazioni più fluide, ecco dove CORSAIR AI Workstation 300 (AI300) e lo CORSAIR AI Software Stack ti aiutano a raggiungere il livello successivo.
L'inferenza locale presenta solitamente dei colli di bottiglia a livello di memoria e velocità di trasmissione. L'AI300 è stato progettato tenendo conto di questa realtà:
- Una workstation compatta progettata per flussi di lavoro di intelligenza artificiale in locale
- Configurazione con memoria elevata che offre spazio sufficiente per modelli più grandi
- Comportamento della memoria grafica progettato per adattarsi ai casi d'uso dell'intelligenza artificiale
- Un selettore delle prestazioni a livello hardware (Silenzioso / Bilanciato / Massimo) che ti permette di scegliere se preferisci la silenziosità o la velocità

È necessaria una GPU NVIDIA per eseguire un LLM locale su Windows?
No. Alcuni strumenti supportano esplicitamente AMD su Windows; ad esempio, la documentazione di Ollama per Windows menziona il supporto sia per le GPU NVIDIA che per quelle AMD Radeon.
È possibile eseguire un modello LLM locale completamente offline?
Sì, dopo aver scaricato l'app e i file dei modelli. L'installazione iniziale e il download dei modelli richiedono solitamente una connessione a Internet, ma l'inferenza può essere eseguita offline una volta che tutto è disponibile in locale.
L'IA locale garantisce automaticamente la privacy?
È possibile, ma dipende dalla tua configurazione. Per "inferenza locale" si intende che il modello viene eseguito sul tuo dispositivo, ma alcune app offrono connessioni cloud opzionali. Se il tuo obiettivo è "nessun cloud richiesto", mantieni disattivate le integrazioni cloud e utilizza modelli esclusivamente locali.
Perché il mio modello locale è lento?
Di solito uno di questi:
- Il modello è troppo grande per la RAM/VRAM disponibile
- Stai utilizzando solo la CPU nonostante sia disponibile l'accelerazione GPU
- Hai impostato una lunghezza del contesto elevata e sta consumando molta memoria
- Lo spazio di archiviazione è pieno (sì, è importante)
PRODOTTI DELL'ARTICOLO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.