BLOG
Gemma 4: Het nieuwe open model van Google en waarom dit het beste presteert op pc’s voor consumenten
Laatst bijgewerkt:
Google heeft zojuist Gemma 4 gelanceerd, zijn meest krachtige reeks modellen met open gewichten tot nu toe, en dat is groot nieuws voor iedereen die AI lokaal draait op alledaagse hardware. Gemma 4 is op 31 maart 2026 uitgebracht onder een volledig vrijgevige Apache 2.0-licentie en is ontworpen om toonaangevende intelligentie te bieden op GPU’s voor consumenten en zelfs op laptops, zonder dat er een abonnement nodig is.
De reeks omvat vier formaten: E2B (2,3 miljard effectieve parameters), E4B (4,5 miljard effectieve parameters), een 26B Mixture-of-Experts-variant met slechts 4 miljard actieve parameters, en een 31B-model met volledige dichtheid. Daarmee beschik je binnen één reeks over alles van edge-vriendelijke tot bijna grensverleggende modellen, en draait het allemaal op het soort pc’s dat pc-bouwers nu al in elkaar zetten.

Wat Gemma 4 zo bijzonder maakt
Gemma 4 is niet alleen groter, maar ook slimmer per parameter. Een paar hoogtepunten:
- Geavanceerde redeneringen en agents: meerstapsplanning, wiskunde, programmeren en autonome workflows, direct klaar voor gebruik.
- Multimodaal: verwerkt tekst en afbeeldingen standaard, met audio-ondersteuning op de kleinere E2B- en E4B-varianten. Het ontleden van documenten, grafiekherkenning en OCR voor handgeschreven tekst werken allemaal via één enkele opdracht.
- Enorme context: 128.000 tokens voor E2B/E4B, en maar liefst 256.000 tokens voor de 26B MoE- en 31B-modellen met hoge dichtheid – ruim voldoende om een volledige codebase of een stapel documenten te verwerken.
- Meertalig: getraind op meer dan 140 talen, met uitstekende standaardondersteuning voor tientallen daarvan.
Het wordt op Hugging Face geleverd in vooraf getrainde en op instructies afgestemde varianten, en werkt vanaf dag één met de tools die je al gebruikt: Ollama, LM Studio, llama.cpp, vLLM en Transformers.
Waarom consumenten-pc’s de ideale markt voor Gemma 4 zijn
Gemma 4 is ontworpen met lokale inferentie als voornaamste doel, en de cijfers bevestigen dit. NVIDIA en Google hebben samengewerkt aan optimalisaties voor RTX-kaarten vanaf de eerste dag, en dankzij recent werk aan llama.cpp is het geheugengebruik van de KV-cache in scenario’s met lange contexten met bijna 40% teruggebracht.
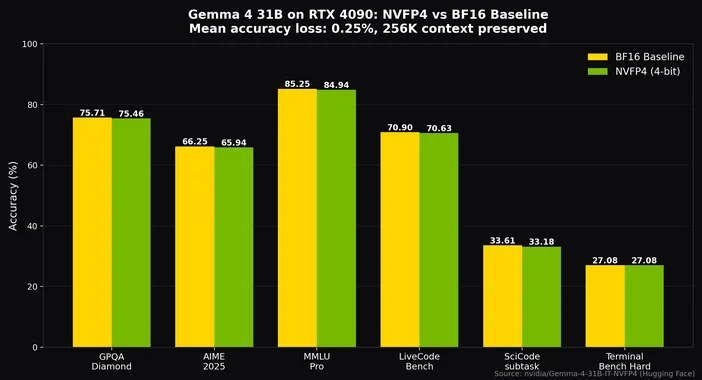
Met Q4_K_M-kwantisering, de ideale instelling voor de meeste builds, kun je het 26B MoE-model op een kaart van 24 GB plaatsen, zoals een RTX 4090 of 3090, met ruimte voor een context van 8K tokens, en toch ruim boven de 20 tokens per seconde halen. Met NVIDIA's NVFP4-kwantisering past zelfs het 31B-dichte model op een enkele RTX 4090 met slechts ~0,25% nauwkeurigheidsverlies, terwijl de volledige 256K-context behouden blijft.
Een korte handleiding voor het bouwen
E2B / E4B (edge en lage latentie): Een RTX 3060 of 4060 met 8 of 12 GB VRAM en een moderne Ryzen 5 of Core i5 is ruim voldoende. Combineer dit met 32 GB DDR5 en een stille AIO als je van plan bent om langdurig te gamen.
26B MoE / 31B dense (voor redenering en multimodale taken): Ga voor een RTX 4090 (of 3090 als je die al hebt), een Ryzen 7 / Core i7 of beter, 64 GB DDR5, een snelle Gen4 NVMe voor het laden van modellen en een voeding van 850 W of meer in een behuizing met een goede luchtstroom. Iets als een CORSAIR iCUE LINK TITAN RX RGB 360 mm AIO houdt de GPU en CPU tevreden bij langdurige inferentielasten.

De RTX 50-serie biedt Gemma 4 nog meer ruimte voor grotere contextgebieden en snellere inferentie.
Snel aan de slag op je pc
1. Installeer Ollama of LM Studio.
2. Haal een Gemma 4-model op van Hugging Face (begin met gemma4:e4b als je een beginner bent, of met gemma4:31b als je over voldoende VRAM beschikt).
3. Voer de inferentie uit en verwacht 50 tot meer dan 100 tokens per seconde op de RTX 40-serie voor de kleinere modellen.
4. Probeer de multimodale functie eens uit: voer een afbeelding en een opdracht in en laat het programma een screenshot, een grafiek of een foto analyseren.
Gemma 4 On-Device: nu ook mobiel
De edge-focus van Gemma 4 strekt zich ook uit naar smartphones. De kleinere E2B- en E4B-varianten draaien op Arm-CPU’s en mobiele GPU’s met een latentie die vrijwel nul is voor spraakherkenning, beeldanalyse en assistenten op het apparaat zelf, zonder dat er een cloud nodig is. Dankzij de AI Edge-stack van Google en Android AICore is dit systeemwijd toegankelijk op Android, en iOS-ontwikkelaars kunnen via Metal gebruikmaken van de CPU en GPU.
Gemma 4 is het duidelijkste teken tot nu toe dat high-end consumenten-pc’s niet alleen gaming-machines zijn, maar echte AI-werkstations. Open gewichten, een soepele licentie, geavanceerde redeneringen en een contextvenster van 256K dat daadwerkelijk op één GPU past. Als je al een moderne CORSAIR-pc hebt, ben je al een heel eind op weg naar een volwaardig lokaal AI-werkstation. Als je er een aan het samenstellen bent, ga dan uit van een kaart van 24 GB, 64 GB DDR5 en een koelsysteem dat niet bezwijkt onder langdurige belasting.

Wil je Gemma lokaal draaien? Maak kennis met de CORSAIR AI Workstation 300
Als je op zoek bent naar een compromisloze manier om Gemma 4 (en andere open modellen) volledig op je eigen hardware te draaien, dan is de CORSAIR AI Workstation 300 daar speciaal voor ontworpen. Het combineert een AMD Ryzen AI Max+ 395 met de Radeon 8060S iGPU en tot 96 GB aan unified VRAM uit 128 GB aan LPDDR5X-8000-geheugen, waardoor je voldoende ruimte hebt om grote Gemma-varianten lokaal te laden en te finetunen zonder naar de schijf te hoeven pagineren. Een speciale 50 TOPS NPU versnelt de inferentie, en het hele systeem past in een 4,4-literbehuizing die je op je bureau kunt zetten. Voor ontwikkelaars en onderzoekers die privacy, lage latentie en geen kosten per token willen, is dit een van de beste manieren om Gemma aan het werk te zetten.
PRODUCTEN IN ARTIKEL
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.