ローカル環境でAIを実行しているなら、「高性能なGPUを用意しましょう」というアドバイスを目にしたことがあるでしょう。しかし、それは実際にはどういう意味なのでしょうか?そして、CPUは本当にそれほど役に立たないのでしょうか?答えは「GPUは良い、CPUは悪い」という単純なものではありません。重要なのは、それぞれのプロセッサがAI推論の背後にある計算処理をどのように処理するか、そしてどちらが処理に追いつくほど高速にデータを転送できるかということです。
AIの推論処理では、実際には何が起きているのか?
ローカルのLLMや画像モデルを実行する際、ハードウェアが繰り返し行っているのは「行列乗算」です。モデルは入力を受け取り、それを数値に変換し、その数値を各レイヤーにわたる数十億回もの演算処理に投入します。ハードウェアがこれらの演算を高速に処理できればできるほど、応答も速くなります。
これは推論であり、学習済みのモデルから出力を生成するものです。ここで何かを学習させているわけではありません。単に、トークンを一つずつ順に処理しているだけです。
CPUはAI処理をどのように行うのか
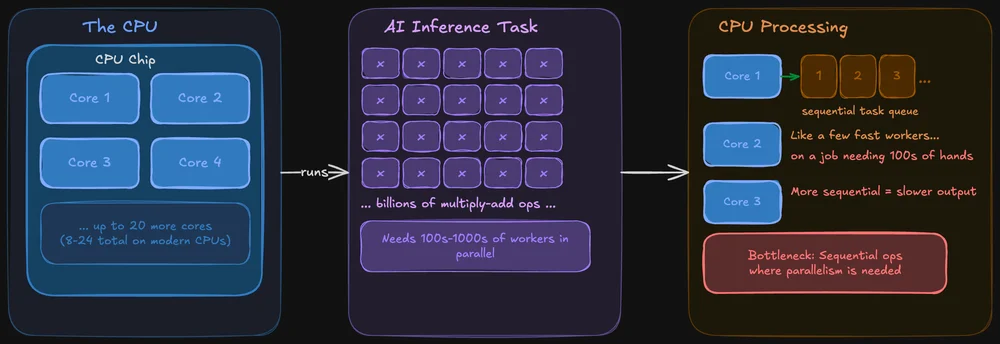
CPUは、あらゆる処理をこなせるように設計されています。オペレーティングシステムやブラウザのタブ、ファイルシステムの処理を担当し、もちろんAIモデルの実行も可能です。現代のCPUは複数のコア(一般向けチップでは通常8~24コア)を搭載しており、各コアは高性能かつ柔軟性に富んでいます。
問題点は、AIの推論処理では、膨大な量のデータに対して同じ演算を同時に実行する必要があることです。CPUでもこれは可能ですが、処理はより順次的なものになります。これは、本来なら数百人の手が同時に必要な仕事を、ごく少数の非常に速い作業員だけでこなそうとしているようなものです。
とはいえ、ローカルAIにおいてCPUが全く役に立たないというわけではありません。llama.cppのようなツールはCPUでの推論に特化して最適化されており、モデルがシステムのRAMに収まるのであれば、CPUだけで実行することは十分に可能です。モデルのサイズによっては、処理速度が明らかに遅くなることもあれば、そうでないこともあります。
GPUがAI処理をどのように行うか
GPUは並列処理を前提に設計されています。CPUのコア数が8~24個程度であるのに対し、最新のGPUには数千もの小さなコアが搭載されており、それらがすべて同時に同じ問題の一部を処理することができます。このため、GPUはAIモデルが依存する大規模な計算処理において、極めて高い性能を発揮します。
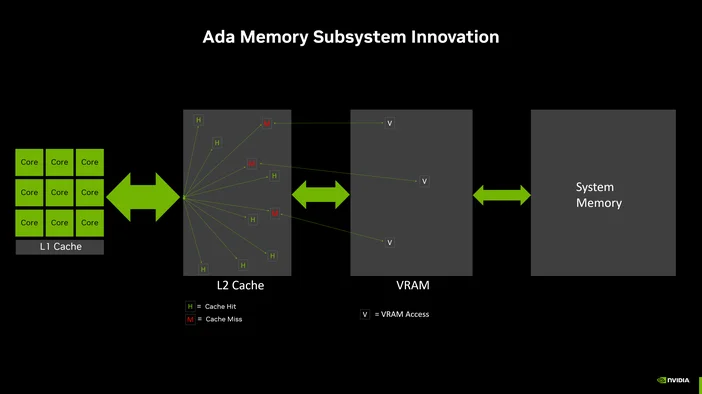
さらに、GPUにはシステムRAMよりもはるかに高い帯域幅を持つ専用のメモリ(VRAM)が搭載されています。この帯域幅は非常に重要であり、何千ものコアにデータをどれだけの速さで供給できるかを左右します。帯域幅が広ければ広いほど、待ち時間が短縮され、計算に充てられる時間が増えます。
特にローカルでのLLM推論において、GPUの優位性は「並列処理能力」と「メモリ帯域幅」の2点に集約されます。これらはいずれも、出力されるトークン数(秒あたり)に直接影響します。
メモリ帯域幅
多くの人が驚くかもしれませんが、ローカルでのLLM推論において、制約要因となるのは多くの場合、純粋な演算能力ではなく、メモリ帯域幅なのです。
推論処理中、生成されるトークンひとつひとつについて、モデルの重みをメモリから読み込む必要があります。もしメモリがプロセッサにデータを十分に速く供給できない場合、コアがいくつあっても、それらはただ待機しているだけになってしまいます。
だからこそ、VRAMの帯域幅は極めて重要なのです。一般的なDDR5システムメモリの構成では、50~90 GB/s程度の帯域幅しか得られません。一方、RTX 5090のような最新のGPUは、1,000 GB/sを超える帯域幅を実現します。これは桁違いの差です。
モデルがVRAMに完全に収まる場合、この理由だけで、推論処理はほぼ常にCPUよりもGPUの方が高速になります。
「CPUのみ」が実際に有効な場合
GPUが常に最適な解決策とは限りません。CPUで実行するのが正しい選択となる現実的なシナリオも存在します:
- 実行しているモデルは小規模(パラメータ数3億以下)であり、速度の差はほとんど感じられない。
- お使いのGPUが対応していないか、またはGPUのVRAMが不足しており、モデルを読み込めない状態です。
- システムRAM(通常はVRAMよりもはるかに容量が大きい)をフル活用して、より大きなモデルを低速で実行したい。
- お使いのノートパソコンやシステムでは、GPUの消費電力や発熱が懸念される状況です。
量子化(モデルの精度を下げてメモリ使用量を削減すること)と、それに最適化されたフレームワークのおかげで、CPUでの推論性能は大幅に向上しました。32GBのRAMを搭載した最新のCPU上で動作する量子化済みの70億パラメータモデルは、多くのタスクにおいて十分に良好な性能を発揮します。


オフロードについてはどうでしょうか?
モデルのサイズがVRAMの容量を超えている場合でも、GPUによる高速化を利用したい場合は、ほとんどのローカルLLMツールが部分的なオフロードに対応しています。これは、モデルの一部のレイヤーをGPUで実行し、残りをCPUで実行することを意味します。
これはトレードオフです。GPUの処理速度のメリットをある程度享受できる反面、CPUに依存するレイヤーがボトルネックとなります。VRAMに収まるレイヤーが多ければ多いほど、処理は高速になります。しかし、GPUに処理されるレイヤーがごくわずかしかないと、データを往復させるオーバーヘッドによって、純粋なCPU推論よりも処理が遅くなってしまう可能性があります。
経験則として、モデルの少なくとも半分をVRAMに収められない場合は、すべてCPUで実行した方が、手間を省けるでしょう。
ローカルAIにおけるNVIDIA対AMD
現在、NVIDIAは地元のAI分野を席巻していますが、その主な理由はCUDAにあります。これは、ほぼすべてのAIツールが構築されているNVIDIA独自のコンピューティングフレームワークです。WindowsでLM Studio、Ollama、またはllama.cppを使用する場合、NVIDIAのGPUを使えば、トラブルシューティングの手間を最小限に抑えつつ、最もスムーズな体験を得ることができます。
AMDは追い上げている。ROCm(AMD版CUDA)は着実に進歩しており、OllamaのようなツールはWindows上でAMD Radeon GPUを明示的にサポートしている。しかし、エコシステムは依然として限定的であり、使用するGPUやツールの組み合わせによっては、互換性の問題に直面する可能性がある。
ローカルAI専用に購入するのであれば、現時点ではNVIDIAの方が無難な選択です。すでにAMDのGPUをお持ちの場合は、ぜひ試してみる価値がありますが、その前に、お使いのツールのドキュメントで対応モデルを確認してください。

CORSAIR AI300の適した場所
現在お使いの環境が、VRAMの不足、メモリ帯域幅の低さ、あるいは130億ポリゴンのモデルを読み込んだ瞬間にシステムが過熱してしまうといったボトルネックに悩まされているなら、CORSAIR AI Workstation 300(AI300)はまさにこうした問題を解決するために設計された製品です。
AI300は、ローカルAI推論の現場の実情に合わせて設計されたコンパクトなワークステーションです:
- 大容量メモリ構成により、より大規模なモデルやより大きなコンテキストウィンドウに対応可能です。
- AIワークロード(およびちょっとしたゲーム)に合わせて拡張可能なグラフィックスメモリ。
- ハードウェアレベルのパフォーマンスセレクター(静音/バランス/最大)により、必要なときは速度を優先し、そうでないときは静音性を優先することができます。
- 「CORSAIR AI Software Stack」は、セットアップを簡素化し、設定に費やす時間を減らして、モデルの実行により多くの時間を割けるようにします。
AI300なら、もともとAI向けに設計されていないシステムでローカルAIを何とか活用しようとしていた方にも、そのワークロードに合わせてハードウェアとソフトウェアが最適化されたマシンをご提供します。

記事内の製品
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.