LLMをローカルで実行するということは、モデルが自分のPC上に存在し、プロンプト(およびモデルに読み込ませるファイル)がPCの外に出る必要がないことを意味します。クラウドアカウントも、APIキーも不要です。「あなたのデータでトレーニングします……たぶん……もしかすると……」といった曖昧な説明もありません。あなたとPC、そして与えられたタスクをこなすモデルだけが存在するのです。
「ローカルLLM」とは、具体的にはどのようなものなのでしょうか?
ローカルLLMとは、リモートサーバーではなく、自分のコンピュータ上で動作する大規模言語モデルのことです。実際には、通常、モデルファイルをダウンロードしてローカルアプリに読み込み、クラウドアシスタントと会話するのと同じようにチャットを行うことになります。ただし、「サーバー」の役割を果たすのは自分のPCです。
LLMをローカルで「実行する」とは、ほとんどの場合、推論(応答の生成)を意味し、ゼロから新しいモデルを学習させることではありません。
なぜローカルでLLMを実行するのでしょうか?
人々がクラウド型LLMからローカル型LLMに乗り換える理由はいくつかあります:
- プライバシー:入力内容は端末内に保存されます(クラウドコネクタを使用していない場合)。
- オフラインでの利用:モデルをダウンロードすれば、インターネットに接続していなくても実行できます。
- 利用制限なし:通信速度制限なし、「本日の利用枠を使い切りました」といった表示もなし、予期せぬ請求もありません。
- ご利用方法:ご希望のモデルをお選びください。サブスクリプション契約に縛られることはありません。
もちろん、利便性と引き換えに制御性を犠牲にすることになります。クラウドモデルは魔法のように感じられるかもしれませんが、ローカルモデルも、使用するハードウェア次第では魔法のように感じられることがあります。
ローカルでLLMを実行するには何が必要ですか?
要約すると:CPUが動作し、GPUが補助し、メモリが重要だ。
実際に楽しい時間を過ごせるかどうかは、以下の要素にかかっています:
- RAM / VRAM:大規模なモデルほど多くのメモリを必要とします。メモリが不足すると、モデルは失敗します。
- ストレージ:モデルは容量が大きくなる場合があります。一部のライブラリでは、ダウンロードするモデルによっては、モデルの保存容量が数十GBから数百GBに達する可能性があるとの注意書きがあります。
- GPU:アプリがGPUに対応している場合、通常、処理速度が大幅に向上します。
RAMが32GB以上の最新のWindows 10/11搭載マシンは、小規模なローカルモデルの実行には十分な基本構成であり、メモリ容量を増やすことで、より大規模なモデルも快適に実行できるようになります。
「ローカルLLMランナー」アプリを選んでください
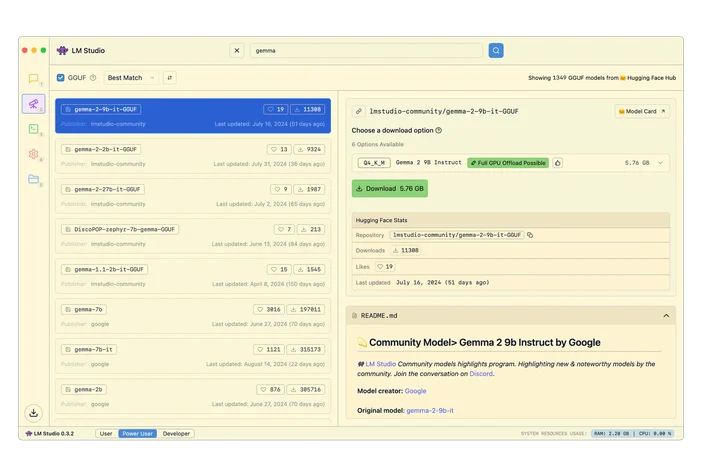
LM Studio(使いやすいGUI)
LM Studioは、モデルをダウンロードしてローカル環境でチャットできるデスクトップアプリです。また、開発者向けにプログラム可能なローカルAPIも備えています。
Ollama(シンプルなCLI + ローカルAPI)
OllamaはネイティブのWindowsアプリとして動作し、コマンドラインでのワークフローに加え、ローカルのHTTP APIエンドポイントを提供します。Windows上のNVIDIAおよびAMD Radeon製GPUを明示的にサポートしています。
llama.cpp(いじり好きな人向け)
最大限の制御性を求めるなら、lama.cppがおすすめです。これは、ビルド手順や複数のバックエンドを備えた、人気のあるオープンソースの推論エンジンです。

最初のモデルをインストールして実行する
大規模なモデルを扱うには、より多くのRAMやVRAMが必要です。これらが不足していると、動作が遅くなったり、クラッシュしたり、ディスクへのスワップが頻繁に行われたり(まるでPCがメープルシロップの中を這うように遅く感じられる)します。
int4量子化モデルにおける安全な目安:
- 8GB RAM → 約30億個のモデル
- 16GB RAM → 約70億のモデル
- 32GB RAM → 約130億個のモデル
また、GPUアクセラレーションを利用している場合は:
- 6GB VRAM → 約30億個のモデル
- 8GB VRAM → 約70億のモデル
- 12GB VRAM → 約130億のモデル
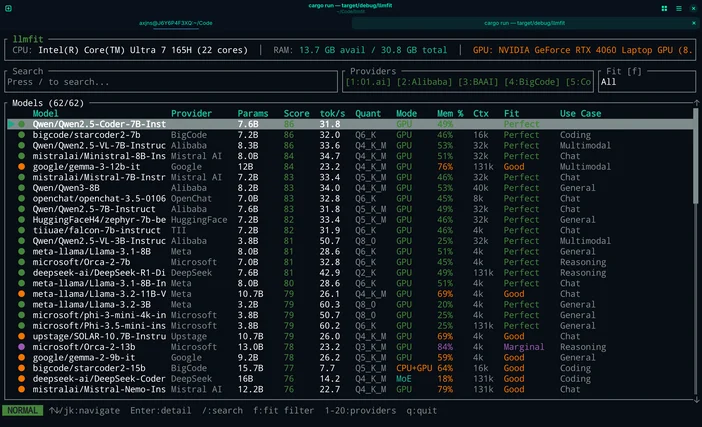
あるいは、推測したくない場合は、LLMfitを使って、お使いのハードウェアにぴったり合うモデルを選択することもできます。
LLMfitは、CPU、RAM、GPU/VRAMを検出し、適合度、予想される処理速度、コンテキスト、品質に基づいてモデルをランク付けするターミナルツールです。これにより、 ダウンロードする前にどのモデルがスムーズに動作するかを確認できます。
こんな時に役立ちます:
- RAM/VRAMの制限に実際に適合するモデルを見つける
- 推奨される量子化を確認する(メモリを過剰に割り当てないようにするため)
- 悲観的なニュースばかりをスクロールするモデルハブではなく、ランク付けされた候補リストを入手する
このワークフローでの使用方法:
- llmfit を実行して、システムのハードウェアをスキャンします
- 上部の「おすすめ」/「提案」をご覧ください
- お使いのマシンに合ったモデルサイズを選び、LM Studio / Ollama / llamaからダウンロードしてください
これで準備完了です!
以上です。ランナを選択し、お使いのハードウェアに適したモデルをダウンロードして、プロンプトを入力し始めましょう!すべてが自分のマシン上で完結します。コンピュータサイエンスの学位も、クラウドサービスの契約も、週末を費やしてトラブルシューティングをする必要もありません。全体のプロセスは、ゲームをインストールするのとほぼ同じくらいの時間しかかかりません。そして、一度動作し始めれば、自分の条件に合わせて動く、プライベートでオフラインのAIアシスタントが手に入るのです。
CORSAIR AI300の適した場所
Windows上でローカルLLMを本格的に運用したい方、特に大規模なモデルやより大きなコンテキストウィンドウ、あるいはよりスムーズなパフォーマンスを求める方には、こちらがおすすめです CORSAIR AI Workstation 300 (AI300) と CORSAIR AI ソフトウェアスタック が、さらなる高みへと導いてくれます。
ローカル推論では、通常、メモリとスループットがボトルネックとなります。AI300はこの現実を踏まえて設計されています:
- ローカルAIワークフロー向けに設計されたコンパクトなワークステーション
- 大規模なモデルにも対応できる余裕のある大容量メモリ構成
- AIのユースケースに合わせて拡張できるように設計されたグラフィックスメモリの動作
- ハードウェアレベルのパフォーマンス選択機能(静音/バランス/最大)により、静音性を重視するか、速度を重視するかを選択できます

WindowsでローカルのLLMを実行するには、NVIDIAのGPUが必要ですか?
いいえ。Windows版では、AMDを明示的にサポートしているツールもあります。例えば、OllamaのWindows向けドキュメントには、NVIDIAとAMD Radeonの両方のGPUがサポートされていると記載されています。
ローカルのLLMを完全にオフラインで実行することはできますか?
はい、アプリとモデルファイルをダウンロードした後です。初期インストールやモデルのダウンロードには通常インターネット接続が必要ですが、すべてがローカルに保存されれば、推論処理はオフラインで実行できます。
ローカルAIは自動的にプライバシーが保護されるのでしょうか?
場合によっては可能ですが、設定次第です。「ローカル推論」とは、モデルがデバイス上で実行されることを意味しますが、一部のアプリではオプションとしてクラウド接続が提供されています。「クラウド不要」が目的の場合は、クラウド連携機能を無効にしたまま、ローカルのみで動作するモデルを使用してください。
なぜ私のローカルモデルは動作が遅いのでしょうか?
通常は、以下のいずれかです:
- モデルが、利用可能なRAM/VRAMの容量に対して大きすぎます
- GPUアクセラレーションが利用可能なのに、CPUのみで実行しています
- コンテキストの長さを長く設定したため、メモリを大量に消費しています
- ストレージ容量がいっぱいです(はい、これは重要なことです)
記事内の製品
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.