大規模言語モデル(LLM)を自分のPCで動かすのは難しそうに思えますが、実は驚くほど手軽です。「ローカルLLM」とは、クラウドもアカウントも使わず、AIを自分のハードウェア上で実行し、データは全て手元に残すことを意味します。オンラインに何も送信せずに、プライベートなブレインストーミングやコード支援、文書Q&Aを実現できるのです。興味が湧いたら、ゼロから最初のプロンプトまで一緒に進めましょう。
どのようなツールを使用していますか?
現在最も初心者向けの選択肢は Ollamaです。これは無料アプリで、ワンラインコマンドで幅広いオープンモデルのダウンロードと実行が可能です(現在はWindowsとmacOSのデスクトップアプリを提供しているため、ターミナル環境で作業する必要はありません)。
より視覚的でオールインワンの体験をお好みなら、 LM Studio(こちらも無料)は、ローカルモデルの発見・実行・管理に最適な選択肢です。Open WebUIは軽量なセルフホスト型チャットインターフェースで、Ollama上に設置可能です。いずれか一つを選ぶか、組み合わせてご利用ください。


必要なもの(ハードウェアとOS)
- オペレーティングシステム:Windows 10/11、macOS、または Linux(以下では Windows の例を示します)。
- メモリとストレージ:7~13Bパラメータモデルには16~32GBのRAMが快適です。より多くのRAMは大きなコンテキスト処理に役立ちます。モデルとキャッシュ用にSSD上に数十GBの空き領域を確保してください。
- GPU(任意だが有用):最新のGPUは処理を高速化し、より大規模なモデルの運用を可能にします。Windowsでは、OllamaがGPUアクセラレーションをサポートし、AMD最適化ビルドを公開しています。
- AMD統合グラフィックス(APU)に関する注記:新型Ryzen AI Max+システムでは、適切な設定によりシステムメモリを「可変グラフィックスメモリ」として共有可能。これにより最大96GBのVRAMをiGPUに割り当てられ、家庭環境での大規模モデル処理に有効です。
クイックスタート(Windows):最初のプロンプトへの最短ルート
- Ollamaをインストールする
- OllamaからWindowsインストーラーをダウンロードするか、Winget経由でインストールしてください: "winget install --id Ollama.Ollama"
インストール後、Ollamaアプリ(GUI)とコマンドラインツールの両方が利用可能になります
- 起動して確認する
- Ollamaデスクトップアプリを開き、プロンプトが表示されたらサインインしてください(ローカル利用にはクラウド不要)。
- またはCLIを確認してください: "ollama --version"。(バージョン番号が表示されます。)
- スターターモデルを引っ張る
- アプリ内でモデルを閲覧・ダウンロードしてください。またはターミナルで:"ollama run llama3:8b"
- これでモデルがダウンロードされ、プロンプト画面が表示されます。質問を入力して実行してください。Ollamaライブラリでは、Gemma、Llama、Qwen、OLMoなど多数のモデルを閲覧できます。
- (オプション) GPUアクセラレーションを有効にする
- グラフィックスドライバを最新の状態に保ってください。OllamaはAMDアクセラレーション対応のWindowsビルドを提供しており、AMDはRadeon上でのLLM向けDirectML/ROCmパスを文書化しています。Ollamaアプリでは、GPUが検出されていることを確認してください(または生成中にタスクマネージャーでGPU使用率を確認してください)。
どのモデルを最初に試すべきですか?
- 「小型で軽快」: gemma3:1bまたはllama3:8bは、素早い応答と低スペックハードウェアに最適。
- 「バランス型」:7B–13Bモデル(例:olmo2:7b、llama3:8b instruct)は汎用的に安定している。
- 「より大きな脳」:200億以上のパラメータを持つモデル(例:gpt-oss:20b、より大規模なLlamaのバリエーション)は、より多くのRAM/VRAMと忍耐を必要としますが、より困難なタスクで真価を発揮します。これらのモデルは、アプリ内で直接、または`ollama run <model>`コマンドで実行できます。
ローカルLLMを最適化するためのヒント
- コンテキスト長:長ければ良いとは限らない。巨大なコンテキスト(例:32k~64kトークン)は生成速度を劇的に低下させる。4k~8kから始め、必要な場合にのみ増やすこと。
- 量子化: ほとんどのアプリ提供モデルは既に量子化済みです。これにより、限られたVRAMに大きなモデルを収めるのに便利です。
- ストレージ:モデルはSSDに保存してください。HDDでは動作が重く感じられます。
- ドライバー: GPUドライバーとアプリを定期的に更新してください。ローカルAIは急速に進化しています。
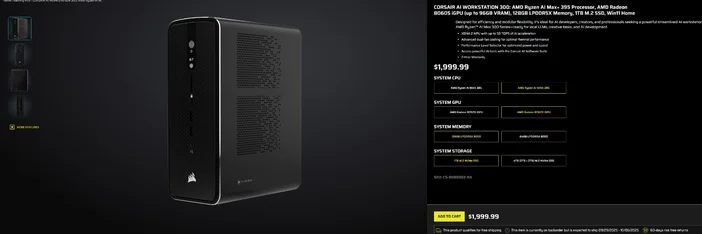
CORSAIR AI WORKSTATION 300 の使用
パーツを組み立てる手間を省き、コンパクトで静音性に優れたデスクトップPCを即座にローカルLLM用に活用したいなら、 CORSAIR AI WORKSTATION 300はクリエイターや開発者にとって多くの要件を満たします:
- CPU/GPU/NPU: AMDRyzen™ AI Max+ 395、Radeon™ 8060S iGPU(最大96GB VRAM)、XDNA 2 NPU(最大50 TOPS)
- メモリとストレージ:128GB LPDDR5X-8000、4TB NVMe (2TB+2TB)
- OS: Windows 11 Home
- デザイン:4.4L小型フォームファクター筐体、デュアルファン冷却、パフォーマンスレベルセレクター搭載
Radeon iGPUの「最大96GB VRAM」は、特にWindowsツール群との相性が良く、必要に応じて大規模なローカルモデルや長いコンテキスト処理に便利な大容量の共有メモリをGPUに割り当てられます。これは容量を犠牲にすることなく、ローカルAI開発へクリーンかつコンパクトにアクセスする道筋を提供します。
よくある質問
ローカルLLMを実行するには専用GPUが必要ですか?
いいえ。CPUのみのシステムでも小型モデルは実行できますが、応答速度は遅くなります。大容量の共有メモリを備えた最新のGPUまたは高性能APUを使用すると、処理速度が向上し、より大規模なモデルを扱えるようになります。
これはプライベートですか?
はい。OllamaやLM Studioなどのローカルツールでは、プロンプトとデータはデフォルトでローカルマシン上に保存されます。(追加する統合機能によっては動作が異なる場合があります。常に設定を確認してください。)
モデルはどこで見つけられますか?
Ollamaライブラリは、人気のある最新のオプション(Llama、Gemma、Qwen、OLMoなど)を一覧表示します。各モデルページにはサイズとサンプルコマンドが表示されます。
CORSAIR AI WORKSTATION 300は大規模なモデルを処理できますか?
ローカルLLM向けに設計されており、128GBのメモリと 最大96GBのVRAMにアクセス可能なiGPUを搭載。高度なローカルワークロードや長いコンテキスト処理に十分な余裕を提供し、特にAMDのWindowsドライバーが大規模割り当てのサポートを拡大する中でその真価を発揮します。実際のスループットはモデルサイズ、量子化、設定によって異なります。
記事内の製品
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat the latest PC, tech, and gaming trends, our community is the place for you.