CUDAコアは、NVIDIA GPU内部にある小さな演算ユニットの一つであり、グラフィックスや並列計算の骨組みとなる処理を担当します。各コアはストリーミングマルチプロセッサ(SM)と呼ばれるより大きなブロック内に存在し、最新のGeForce「Blackwell」GPUでは各SMが128個のCUDAコアを内蔵しています。これがRTX 5090で21,760個のCUDAコア総数が表示される理由です。チップには多数のSMが搭載されており、それぞれがこれらのコアを詰め込んでいるのです。
CUDA(NVIDIAの並列コンピューティングプラットフォーム)はソフトウェア面を担う:アプリケーションやフレームワークがレンダリング、AI、シミュレーションといった大規模並列処理をこれらのコアに効率的に送信することを可能にする

CUDAコアはどのように動作するのか?
GPUは大量処理を目的に設計された工場のようなものと考えよう。CUDAコアは32スレッドの ワープ群で作業を処理し、異なるデータに対して同一の命令を実行する(NVIDIAがSIMTと呼ぶモデル)。これがGPUが一気に数千の演算を処理する仕組みだ。各SMにはスケジューラが搭載され、多数のワープを同時に稼働させることでメモリレイテンシを隠蔽し、コアを常に稼働状態に保つ。
有用なイメージ:
- CUDAコア= 個々のワーカー(加算や乗算などの演算を実行する)
- SM= 独自のスケジューラ、キャッシュ、特殊機能ユニット、Tensor Coreなどを備えたショップフロア
- GPU= 工場全体であり、多数のSMが並列に動作する。
CUDAコアとCPUコア(およびその他のGPUコア)
- CPUコアではない:CUDAコアはスループット向けに最適化された単純な演算レーンであり、レイテンシ調整された汎用CPUコアではない。GPUはこうした小さなレーンを多数連携させることでスケーリングを実現する。(CUDAのプログラミングガイドはこのスループット指向の設計を説明している。)
- 専用GPUコアとは異なり:
- テンソルコアは行列演算エンジンであり、AI/MLやDLSSなどの機能を強化します。
- RTコアはレイトレーシング(BVH探索、レイ/三角形テスト)を高速化します。
これらのタスクは特定の処理をオフロードするため、CUDAコアはシェーディング/演算処理に集中できる

画像提供:NVIDIA
より多くのCUDAコアは常に高い性能を意味するのか?
通常はそうだが、それだけでは不十分だ。アーキテクチャが非常に重要である。例えば、NVIDIAのアンペール世代では、SMあたりのFP32スループットがチューリング世代の2倍となったため、「コアあたりの性能」は世代間で変化した。また、Adaはキャッシュ(特にL2)を大幅に拡張しており、コア数を変更せずに多くのワークロードを向上させている。要するに:異なる世代間のCUDAコア数を比較することは、単純な比較ではない。
その他の大きな変動要因:
- クロック速度と電力ヘッドルーム(コアの実行速度)。
- メモリ帯域幅とキャッシュサイズ(コアへの供給)。
- Tensor/RTコアの使用(AIおよびレイトレーシング処理はCUDAコアから移行)。
- ドライバーとソフトウェア(アプリがCUDA経由でGPUをどれだけ効率的に使用するかの指標)
CUDAコアは実際にどのような役割を果たすのか?
- ゲーム/グラフィックス:内部ではシェーダープログラム(頂点、ピクセル、コンピュート)を実行する。RTコアがレイトレーシングの負荷の高い処理を担当し、CUDAコアは依然としてそれらに関連する多くのシェーディングと計算を処理する。
- コンテンツ作成とシミュレーション:物理演算ソルバー、ノイズ除去ツール、レンダリングカーネル、ビデオエフェクトなど、その多くはCUDAの並列モデルを活用するために開発されています。
- AI/ML:テンソル演算はテンソルコアで実行されますが、前処理、後処理、および非行列演算の多くは依然としてCUDAコア上で実行されます。
必要なCUDAコア数は?
親しみやすい目安として:
- 高FPS 1080p~1440pゲーミング:コア数だけでなく、GPU全体(アーキテクチャ、クロック、メモリ、RT/テンソル機能)を評価せよ。ベンチマークは単純な数値よりも重要だ。
- 4K解像度や高度なレイトレーシング処理では、より多くのSM/CUDAコアと強力なRT/Tensorブロックに加え、帯域幅とキャッシュの恩恵を受けられます。
- AI/演算処理:コア数は重要だが、Tensor Coreの性能、VRAM容量、メモリ帯域幅がスループットを左右することが多い。
スケールの簡易的な確認として、RTX 5090は21,760個のCUDAコアを搭載していると記載されています。これはNVIDIAが複数のSM(ストリームマルチプロセッサ)にまたがるコア数をSM単位で集計していることを示しています。ただし繰り返しになりますが、性能向上は単純なコア数ではなく、設計全体の総合力によるものです。
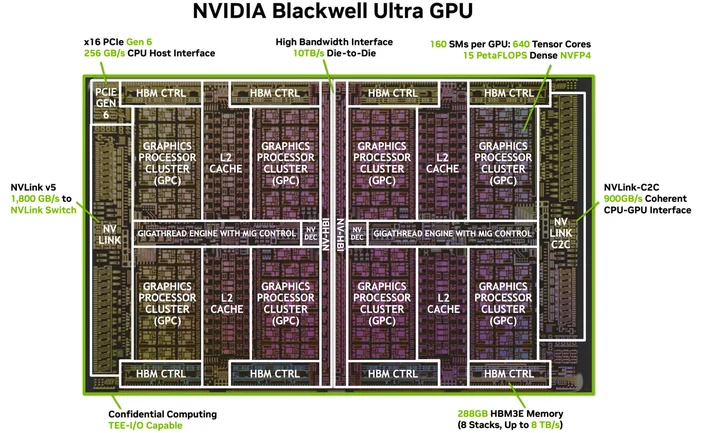
画像提供:NVIDIA
特別なソフトウェアやケーブルは必要ですか?(CUDAにおける「4K対応HDMI」のようなもの)
特別なケーブルは必要ありませんが、適切なソフトウェアスタックは 必須です。CUDAはNVIDIAのプラットフォームであり、アプリケーションはドライバー、ツールキット、ライブラリを通じてこれを利用します。NVIDIAドライバーと(必要な場合)CUDAツールキットをインストールすれば、多くの人気アプリケーションやフレームワークは既にCUDAアクセラレーションを活用する設計となっており、対応アプリは…単にそれを利用するだけです。
どのGPUがCUDAをサポートしていますか?
CUDAは、NVIDIAの全製品ライン(ゲーミングおよびクリエイティブ向けGeForce/RTX、プロフェッショナル向けRTX、データセンター向けGPU)のCUDA対応GPU上で動作します。プログラミングガイドでは、このモデルが多くのGPU世代およびSKUにまたがって拡張可能であることが明記されています。NVIDIAはCUDA対応GPUとその演算能力の一覧を管理しています。
CUDAコアは「シェーダーコア」と同じものですか?
日常的なGPU用語において、NVIDIA GPUでは「CUDAコア」とは、各SM内部でシェーディングや汎用演算に使用されるプログラム可能なFP32/INT32演算ユニットを指します。
なぜCUDAコアの数は世代間でこれほど異なるのか?
アーキテクチャは進化するからだ。アンペールはFP32データパスを変更した(クロック当たりの処理量増加)し、アダはキャッシュを刷新したため、性能はコア数に比例して直線的に向上しなくなった。
ワープって何だっけ?
SM上で同期して実行される32スレッドのグループ。アプリケーションは数千のスレッドを起動し、GPUはハードウェアを稼働状態に保つためそれらをワープとしてスケジューリングする。
CUDAコアはAIに役立つのか?
はい、しかし現代のAIを大きく加速させているのはTensorコアです。CUDAコアは依然として、それらのパイプラインにおける多くの周辺処理を担当しています。
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.