로컬에서 AI를 실행하고 있다면 “좋은 GPU를 구하라”는 조언을 한 번쯤 들어보셨을 겁니다. 하지만 그게 실제로 무슨 뜻일까요? 그리고 여러분의 CPU는 정말 그렇게 쓸모없는 걸까요? 답은 단순히 “GPU는 좋고, CPU는 나쁘다”라고 단정 지을 수 있는 문제가 아닙니다. 중요한 것은 각 프로세서가 AI 추론에 필요한 연산을 어떻게 처리하는지, 그리고 어느 쪽이 데이터를 충분히 빠르게 전송해 처리 속도를 따라갈 수 있는지입니다.
AI 추론 과정에서는 실제로 어떤 일이 일어나고 있을까?
로컬 LLM이나 이미지 모델을 실행할 때, 하드웨어는 행렬 곱셈이라는 작업을 끊임없이 반복합니다. 모델은 사용자의 입력을 받아 숫자로 변환한 뒤, 이 숫자들을 여러 레이어에 걸쳐 수십억 번의 수학적 연산에 적용합니다. 하드웨어가 이러한 연산을 더 빠르게 처리할수록 응답 속도도 빨라집니다.
이것은 추론으로, 훈련된 모델을 통해 결과를 산출하는 과정입니다. 별도의 훈련을 진행하는 것이 아닙니다. 단지 토큰을 하나씩 순차적으로 처리하며 연산을 수행할 뿐입니다.
CPU가 AI 작업을 처리하는 방식
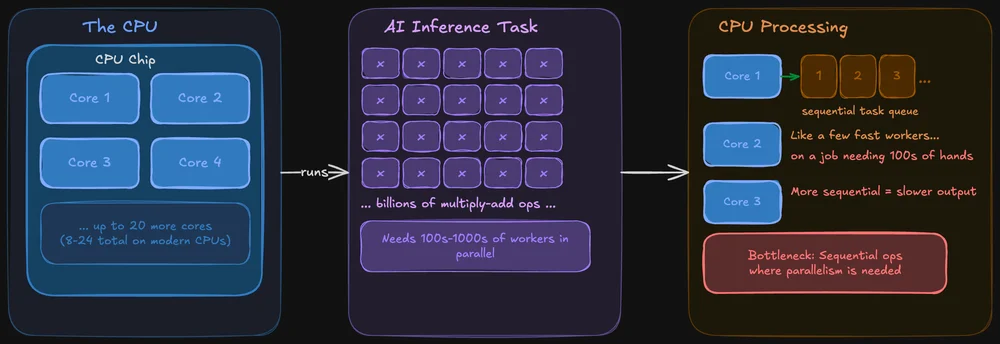
CPU는 모든 작업을 능숙하게 처리하도록 설계되었습니다. 운영 체제, 브라우저 탭, 파일 시스템을 관리할 뿐만 아니라, AI 모델도 실행할 수 있습니다. 최신 CPU는 여러 개의 코어(일반적으로 소비자용 칩의 경우 8~24개)를 갖추고 있으며, 각 코어는 강력하고 유연합니다.
문제는 다음과 같습니다. AI 추론은 방대한 양의 데이터에 대해 동일한 연산을 동시에 수행하는 작업입니다. CPU도 이를 수행할 수 있지만, 연산을 처리하는 방식이 비교적 순차적입니다. 이는 마치 수백 명의 인력이 동시에 투입되어야 할 작업을, 극소수의 매우 빠른 인력만으로 해결하려는 것과 같습니다.
그렇다고 해서 CPU가 로컬 AI에 전혀 쓸모가 없는 것은 아닙니다. llama.cpp와 같은 도구는 CPU 추론을 위해 특별히 최적화되어 있으며, 모델이 시스템 RAM에 들어갈 수 있다면 CPU만으로 충분히 실행할 수 있습니다. 다만 모델의 크기에 따라 속도가 눈에 띄게 느려질 때도 있고, 그렇지 않을 때도 있습니다.
GPU가 AI 작업을 처리하는 방식
GPU는 병렬 처리를 기반으로 설계되었습니다. CPU가 8~24개의 코어를 갖는 반면, 최신 GPU는 수천 개의 소형 코어를 갖추고 있어 동일한 문제의 각 부분을 동시에 처리할 수 있습니다. 덕분에 GPU는 AI 모델이 필요로 하는 대량의 연산 처리에 특히 탁월합니다.
게다가 GPU는 시스템 RAM보다 훨씬 더 높은 대역폭을 가진 전용 메모리(VRAM)를 갖추고 있습니다. 이 대역폭은 수천 개의 코어에 데이터를 얼마나 빠르게 공급할 수 있는지를 결정하는 중요한 요소입니다. 대역폭이 넓을수록 대기 시간은 줄어들고 실제 연산 시간은 늘어납니다.
특히 로컬 LLM 추론의 경우, GPU의 장점은 크게 두 가지로 요약됩니다. 바로 병렬 처리 능력과 메모리 대역폭입니다. 이 두 가지 요소는 출력에서 초당 처리되는 토큰 수에 직접적인 영향을 미칩니다.
메모리 대역폭
대부분의 사람들이 놀랄 만한 사실이 하나 있습니다. 로컬 LLM 추론의 경우, 순수한 연산 성능이 제한 요인이 되는 경우는 드물고, 오히려 메모리 대역폭이 결정적인 요인입니다.
추론 과정에서 생성되는 모든 토큰에 대해 모델 가중치를 메모리에서 읽어와야 합니다. 메모리가 프로세서에 데이터를 충분히 빠르게 공급하지 못하면, 코어가 아무리 많아도 그저 대기 상태에 머물러 있을 뿐입니다.
이것이 바로 VRAM 대역폭이 그토록 중요한 이유입니다. 일반적인 DDR5 시스템 메모리 구성은 50~90GB/s의 대역폭을 제공할 수 있습니다. 반면 RTX 5090과 같은 최신 GPU는 1,000GB/s가 넘는 대역폭을 제공합니다. 이는 한 차원 다른 차이입니다.
모델이 VRAM에 완전히 들어간다면, 이 이유만으로도 추론 작업은 거의 항상 CPU보다 GPU에서 더 빠르게 수행됩니다.
CPU만 사용하는 것이 실제로 타당한 경우
GPU가 항상 해답은 아닙니다. CPU에서 실행하는 것이 더 나은 선택인 실제 상황도 있습니다:
- 현재 실행 중인 모델은 규모가 작아서(매개변수 3B 이하) 속도 차이가 거의 느껴지지 않습니다.
- 호환되는 GPU가 없거나, GPU의 VRAM 용량이 모델을 로드하기에 충분하지 않습니다.
- 더 큰 모델을 더 낮은 프레임 속도로 실행하기 위해 시스템 RAM 전체(보통 VRAM보다 훨씬 용량이 큽니다)를 사용하고 싶은 경우입니다.
- 현재 사용 중인 노트북이나 시스템에서 GPU의 전력 소모나 발열이 문제인 경우입니다.
양자화(메모리 사용량을 줄이기 위해 모델의 정밀도를 낮추는 기술)와 이를 위해 최적화된 프레임워크 덕분에 CPU 기반 추론 성능이 크게 향상되었습니다. 32GB RAM을 탑재한 최신 CPU에서 구동되는 양자화된 70억 파라미터 모델은 많은 작업에서 충분히 원활하게 작동합니다.


오프로딩은 어떨까요?
모델이 VRAM 용량을 초과하지만 GPU 가속을 계속 사용하고 싶은 경우, 대부분의 로컬 LLM 도구는 부분 오프로딩을 지원합니다. 즉, 모델의 일부 레이어는 GPU에서 실행되고 나머지는 CPU에서 실행됩니다.
이는 일종의 절충안입니다. GPU의 속도 이점을 일부 누릴 수 있지만, CPU에 의존하는 레이어들이 병목 현상이 됩니다. VRAM에 더 많은 레이어를 담을 수 있을수록 처리 속도는 빨라집니다. 반면, GPU에 처리되는 레이어가 극히 적다면, 데이터를 오가며 발생하는 오버헤드 때문에 오히려 순수 CPU 추론보다 속도가 더 느려질 수도 있습니다.
일반적인 원칙은 이렇습니다. 모델의 절반 이상을 VRAM에 담을 수 없다면, 차라리 CPU에서 완전히 실행하는 편이 더 나을 수 있으며, 그렇게 하면 복잡한 과정을 피할 수 있습니다.
로컬 AI 분야에서 NVIDIA 대 AMD
현재 NVIDIA는 주로 CUDA 덕분에 국내 AI 시장을 주도하고 있습니다. CUDA는 거의 모든 AI 도구가 구축된 기반이 되는 NVIDIA의 독자적인 컴퓨팅 프레임워크입니다. Windows에서 LM Studio, Ollama 또는 llama.cpp를 사용 중이라면, NVIDIA GPU를 통해 가장 원활한 환경을 경험할 수 있으며 문제 해결에 드는 수고도 최소화할 수 있습니다.
AMD가 빠르게 추격하고 있습니다. ROCm(AMD의 CUDA 대응 기술)은 상당한 진전을 보였으며, Ollama와 같은 도구는 Windows 환경에서 AMD 라데온 GPU를 명시적으로 지원합니다. 하지만 생태계는 여전히 제한적이며, 사용 중인 특정 GPU와 도구에 따라 호환성 문제가 발생할 수 있습니다.
로컬 AI 전용으로 구매하신다면, 현재로서는 NVIDIA가 더 안전한 선택입니다. 이미 AMD GPU를 보유하고 계신다면, 일단 시도해 볼 가치가 충분합니다. 단, 먼저 사용 중인 도구의 설명서를 확인하여 지원되는 모델을 확인하시기 바랍니다.

CORSAIR AI300의 활용처
현재 사용 중인 시스템이 VRAM 부족, 느린 메모리 대역폭, 혹은 130억 폴리곤 모델을 불러오는 순간 과열되는 문제 등으로 인해 성능 병목 현상을 겪고 있다면, 바로 이러한 문제를 해결하기 위해 설계된 제품이 바로 CORSAIR AI Workstation 300(AI300) 입니다.
AI300은 로컬 AI 추론의 실제 환경을 고려하여 설계된 소형 워크스테이션입니다:
- 더 큰 모델과 더 넓은 컨텍스트 윈도우를 수용할 수 있는 대용량 메모리 구성.
- AI 워크로드(그리고 약간의 게임)에 맞춰 확장 가능한 그래픽 메모리.
- 하드웨어 수준의 성능 선택기(조용 / 균형 / 최대)를 통해 필요할 때는 속도를, 그렇지 않을 때는 조용한 환경을 우선시할 수 있습니다.
- CORSAIR AI 소프트웨어 스택은 설정 과정을 간소화하여, 구성에 드는 시간을 줄이고 모델 실행에 더 많은 시간을 할애할 수 있도록 해줍니다.
AI를 위해 설계되지 않은 시스템에서 로컬 AI 기능을 억지로 끌어내려 애써왔다면, AI300은 해당 워크로드를 중심으로 하드웨어와 소프트웨어가 실제로 구축된 시스템을 제공합니다.

기사의 제품
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.