자신의 PC에서 대규모 언어 모델(LLM)을 실행한다는 건 부담스러워 보일 수 있지만, 의외로 접근하기 쉽습니다. "로컬 LLM"이란 단순히 AI가 클라우드나 계정 없이 사용자의 하드웨어에서 실행되며, 데이터는 모두 사용자에게 남는다는 의미입니다. 온라인으로 아무것도 전송하지 않고도 개인적인 브레인스토밍, 코드 도움말, 문서 Q&A를 생각해 보세요. 마음에 드신다면, 이제 처음부터 시작해 첫 프롬프트까지 함께 해보겠습니다.
우리는 어떤 도구를 사용하고 있나요?
현재 가장 초보자에게 친숙한 옵션은 Ollama입니다. 이 무료 앱은 한 줄 명령어로 다양한 오픈 소스 모델을 다운로드하고 실행할 수 있습니다(이제 Windows 및 macOS용 데스크톱 앱을 제공하므로 터미널 환경에 갇혀 지낼 필요가 없습니다).
시각적이고 올인원 경험을 선호하신다면, LM Studio (무료)는 로컬 모델을 발견하고 실행하며 관리하는 데 또 다른 훌륭한 선택지입니다. Open WebUI는 Ollama 위에 설치할 수 있는 가볍고 자체 호스팅 가능한 채팅 인터페이스입니다. 하나를 선택하거나 혼합하여 사용하세요.


필요한 사항 (하드웨어 및 OS)
- 운영 체제: Windows 10/11, macOS 또는 Linux (아래에서는 Windows 예시를 보여드리겠습니다).
- 메모리 및 저장 공간: 7~13B 매개변수 모델에는 16~32GB RAM이 적당하며, 더 큰 컨텍스트에는 더 많은 RAM이 도움이 됩니다. 모델과 캐시를 위해 SSD에 수십 GB의 여유 공간을 확보하세요.
- GPU(선택 사항이지만 유용함): 최신 GPU는 작업 속도를 높이고 더 큰 모델을 실행할 수 있게 합니다. Windows에서 Ollama는 GPU 가속을 지원하며 AMD 최적화 빌드를 제공합니다.
- AMD 통합 그래픽(APU) 관련 참고 사항: 새로운 Ryzen AI Max+ 시스템은 시스템 메모리를 "가변 그래픽 메모리"로 공유할 수 있어, 적절한 구성 시 최대 96GB의 VRAM을 내장 그래픽 프로세서(iGPU)에 할당할 수 있습니다. 이는 가정에서 더 큰 모델을 처리할 때 유용합니다.
빠른 시작 (Windows): 첫 프롬프트를 위한 가장 빠른 길
- 올라마 설치
- Ollama에서 Windows 설치 프로그램을 다운로드하거나 Winget을 통해 설치하세요: "winget install --id Ollama.Ollama"
설치 후에는 Ollama 앱 (GUI)과 명령줄 도구 모두를 사용할 수 있습니다.
- 실행 및 검증
- Ollama 데스크톱 앱을 열고 요청 시 로그인하세요(로컬 사용 시 클라우드 필요 없음).
- 또는 CLI를 확인하세요: "ollama --version". (버전 번호가 표시됩니다.)
- 스타터 모델을 뽑다
- 앱에서 모델을 찾아 다운로드하세요. 또는 터미널에서: "ollama run llama3:8b"
- 이모델을 다운로드하면 프롬프트 화면으로 이동합니다. 질문을 입력하고 실행하세요. Ollama 라이브러리에서 다양한 모델(Gemma, Llama, Qwen, OLMo 등)을 찾아볼 수 있습니다.
- (선택 사항) GPU 가속 활성화
- 그래픽 드라이버를 최신 상태로 유지하세요. Ollama는 AMD 가속이 적용된 Windows 빌드를 제공하며, AMD는 Radeon에서 LLM용 DirectML/ROCm 경로를 문서화합니다. Ollama 앱에서 GPU가 감지되었는지 확인하세요(또는 생성 중 작업 관리자에서 GPU 사용량을 모니터링하세요).
어떤 모델을 먼저 시도해 볼까요?
- “작고 날렵함”: gemma3:1b 또는 llama3:8b 빠른 응답과 저사양 하드웨어에 적합합니다.
- “균형 잡힌”: 7B–13B 모델(예: olmo2:7b, llama3:8b instruct)은 일반적인 용도로 견고합니다.
- "더 큰 뇌": 200억 이상 파라미터 모델(예: gpt-oss:20b, 더 큰 Llama 변형 모델)은 더 많은 RAM/VRAM과 인내가 필요하지만, 더 어려운 작업에서 빛을 발합니다. 앱 내에서 직접 또는 ollama run <모델명> 명령어로 이 모델들을 실행할 수 있습니다.
로컬 LLM 최적화를 위한 팁
- 컨텍스트 길이: 길다고 항상 좋은 것은 아닙니다. 지나치게 큰 컨텍스트(예: 32k-64k 토큰)는 생성 속도를 현저히 저하시킬 수 있습니다. 4k–8k로 시작하여 필요한 경우에만 늘리십시오.
- 양자화: 대부분의 앱에서 제공하는 모델은 이미 양자화되어 있어, 제한된 VRAM에 더 큰 모델을 적용하기에 편리합니다.
- 저장: 모델은 SSD에 보관하십시오; HDD는 느리게 느껴질 것입니다.
- 드라이버: GPU 드라이버와 앱을 정기적으로 업데이트하세요. 로컬 AI는 빠르게 진화하고 있습니다.
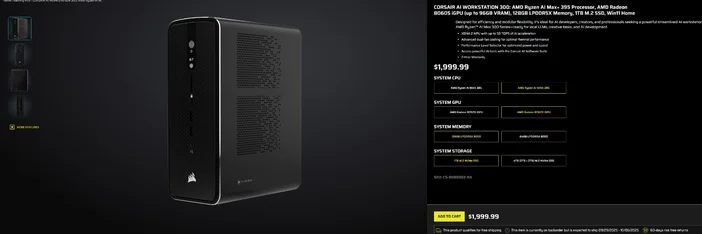
CORSAIR AI 워크스테이션 300 사용하기
조립 과정을 생략하고 즉시 사용 가능한 소형 저소음 데스크탑으로 로컬 LLM을 활용하고 싶다면, CORSAIR AI WORKSTATION 300 은 크리에이터와 개발자에게 필요한 많은 요소를 충족시킵니다:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S 내장 그래픽 프로세서(최대 96GB VRAM), XDNA 2 신경망 프로세서(최대 50 TOPS)
- 메모리 및 저장 공간: 128GB LPDDR5X‑8000, 4TB NVMe (2TB+2TB)
- 운영 체제: Windows 11 Home
- 디자인: 듀얼 팬 냉각 및 성능 레벨 선택기가 적용된 4.4L 소형 폼 팩터 섀시
라데온 내장 그래픽 프로세서(iGPU)의 "최대 96GB VRAM"은 특히 윈도우 도구와 잘 어울립니다. 이 도구는 필요할 때 더 큰 로컬 모델과 더 긴 컨텍스트를 위해 GPU에 대용량 공유 메모리를 할당할 수 있습니다. 이는 용량을 희생하지 않으면서 로컬 AI 개발을 위한 깔끔하고 간결한 경로를 제공합니다.
자주 묻는 질문
로컬 LLM을 실행하려면 전용 GPU가 필요한가요?
아니요. CPU 전용 시스템에서도 소규모 모델은 실행할 수 있지만 응답 속도가 느려집니다. 현대적인 GPU 또는 대용량 공유 메모리를 갖춘 고급 APU를 사용하면 속도가 향상되고 모델 규모를 확대할 수 있습니다.
이건 사적인 건가요?
예. Ollama나 LM Studio 같은 로컬 도구에서는 프롬프트와 데이터가 기본적으로 사용자의 컴퓨터에 저장됩니다. (추가하는 통합 기능은 다르게 동작할 수 있으니 항상 설정을 확인하세요.)
모델은 어디서 찾을 수 있나요?
올라마 라이브러리는 인기 있고 최신 옵션(라마, 젬마, 큐웬, OLMo 등)을 나열합니다. 각 모델 페이지에는 크기 및 예제 명령어가 표시됩니다.
CORSAIR AI WORKSTATION 300은 대형 모델을 처리할 수 있나요?
이 제품은 로컬 LLM을 위해 설계되었으며, 128GB 메모리와 최대 96GB VRAM에 접근 가능한 iGPU를 탑재해 고급 로컬 워크로드 및 긴 컨텍스트 처리에 탁월한 여유 공간을 제공합니다. 특히 AMD의 Windows 드라이버가 대용량 할당 지원 범위를 확장함에 따라 더욱 효과적입니다. 실제 처리량은 모델 크기, 양자화 수준 및 설정에 따라 달라집니다.
기사의 제품
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.