CUDA 코어는 NVIDIA GPU 내부에 있는 작은 연산 유닛 중 하나로, 그래픽스와 병렬 연산을 위한 기본 작업을 수행합니다. 각 코어는 스트리밍 멀티프로세서(SM)라 불리는 더 큰 블록 안에 존재하며, 최신 GeForce "Blackwell" GPU에서는 각 SM이 128개의 CUDA 코어를 포함합니다. 그래서 RTX 5090과 같은 제품에서 총 21,760개의 CUDA 코어가 표시되는 것입니다. 칩 자체에 다수의 SM이 탑재되어 있으며, 각 SM이 해당 코어들로 구성되어 있기 때문입니다.
CUDA(엔비디아의 병렬 컴퓨팅 플랫폼)는 소프트웨어 측면의 이야기입니다: 애플리케이션과 프레임워크가 렌더링, AI, 시뮬레이션과 같은 대규모 병렬 작업을 해당 코어에 효율적으로 전송할 수 있게 합니다.

CUDA 코어는 어떻게 작동하나요?
GPU를 대량 작업을 처리하도록 설계된 공장으로 생각해보세요. CUDA 코어는 32개의 스레드로 구성된 워프 그룹에서 동일한 명령어를 서로 다른 데이터에 대해 실행합니다(NVIDIA가 SIMT라고 부르는 모델). 이것이 GPU가 한 번에 수천 개의 연산을 처리하는 방식입니다. 각 SM에는 메모리 지연 시간을 숨기고 코어를 바쁘게 유지하기 위해 여러 워프를 동시에 실행하는 스케줄러가 있습니다.
유용한 마음속 그림:
- CUDA 코어 = 개별 작업자(덧셈, 곱셈과 같은 연산을 수행함).
- SM = 자체 스케줄러, 캐시, 특수 기능 유닛, 텐서 코어 등을 갖춘 작업 공간
- GPU = 병렬로 작동하는 다수의 SM(스트림 멀티프로세서)을 갖춘 전체 공장.
CUDA 코어 대 CPU 코어 (및 기타 GPU 코어)
- CPU 코어가 아님: CUDA 코어는 처리량에 최적화된 단순한 산술 레인으로, 지연 시간에 맞춰 조정된 대형 범용 CPU 코어가 아닙니다. GPU는 이러한 소형 레인을 다수 동원해 협업함으로써 확장성을 확보합니다. (CUDA 프로그래밍 가이드에서 이 처리량 중심 설계에 대해 설명합니다.)
- 특화된 GPU 코어와는 다르게:
- 텐서 코어는 AI/ML 및 DLSS와 같은 기능을 가속화하는 행렬 연산 엔진입니다;
- RT 코어는 레이 트레이싱(BVH 탐색, 레이/삼각형 테스트)을 가속화합니다.
이러한 작업들은 특정 작업을 오프로드하여 CUDA 코어가 셰이딩/컴퓨팅에 집중할 수 있도록 합니다.

이미지 출처: NVIDIA
CUDA 코어가 많을수록 항상 성능이 더 높을까?
일반적으로는 그렇지만 단독으로는 아닙니다. 아키텍처가 매우 중요합니다. 예를 들어, NVIDIA의 Ampere 세대는 Turing 대비 SM당 FP32 처리량을 두 배로 늘렸으므로 세대 간 '코어당' 성능이 달라졌습니다. Ada는 또한 캐시(특히 L2)를 크게 확장하여 코어 수를 변경하지 않고도 많은 워크로드를 향상시킵니다. 요약하자면: 서로 다른 세대의 CUDA 코어 수를 비교하는 것은 동등한 비교가 아닙니다.
다른 주요 변수들:
- 클럭 속도와 전력 헤드룸 (코어의 실행 속도).
- 메모리 대역폭 및 캐시 크기 (코어에 공급).
- 텐서/RT 코어 사용 (AI 및 레이 트레이싱 작업이 CUDA 코어에서 전환됨).
- 드라이버 및 소프트웨어 (앱이 CUDA를 통해 GPU를 얼마나 잘 활용하는지).
CUDA 코어는 실제로 어떤 역할을 할까?
- 게임/그래픽: 내부적으로 셰이더 프로그램(버텍스, 픽셀, 컴퓨트)을 실행합니다. RT 코어는 복잡한 레이 트레이싱 단계를 처리하며, CUDA 코어는 여전히 주변에서 많은 셰이딩 및 컴퓨팅 작업을 수행합니다.
- 콘텐츠 제작 및 시뮬레이션: 물리 솔버, 노이즈 제거기, 렌더 커널, 비디오 효과 등 많은 기술이 CUDA의 병렬 모델을 활용하도록 설계되었습니다.
- AI/ML: 텐서 연산은 텐서 코어로 처리되지만, 많은 전처리, 후처리 및 비행렬 작업은 여전히 CUDA 코어에서 실행됩니다.
CUDA 코어는 몇 개나 필요할까요?
친절한 경험칙:
- 고프레임률 1080p–1440p 게이밍: 코어 수뿐만 아니라 GPU 전체(아키텍처, 클럭, 메모리, RT/텐서 기능)를 살펴보세요. 벤치마크 결과가 단순한 숫자보다 더 중요합니다.
- 4K 또는 고강도 레이 트레이싱: 더 많은 SM/CUDA 코어와 강력한 RT/텐서 블록, 그리고 대역폭 및 캐시의 혜택을 누릴 수 있습니다.
- AI/컴퓨팅: 코어 수는 도움이 되지만, 텐서 코어 성능, VRAM 용량, 메모리 대역폭이 처리량을 좌우하는 경우가 많습니다.
규모에 대한 간단한 검증으로, RTX 5090은 21,760개의 CUDA 코어를 표기하며 NVIDIA가 다수의 SM에 걸쳐 SM당 코어를 어떻게 집계하는지 보여줍니다. 하지만 다시 말해, 성능 향상은 단순히 코어 수만이 아닌 전체 설계에서 비롯됩니다.
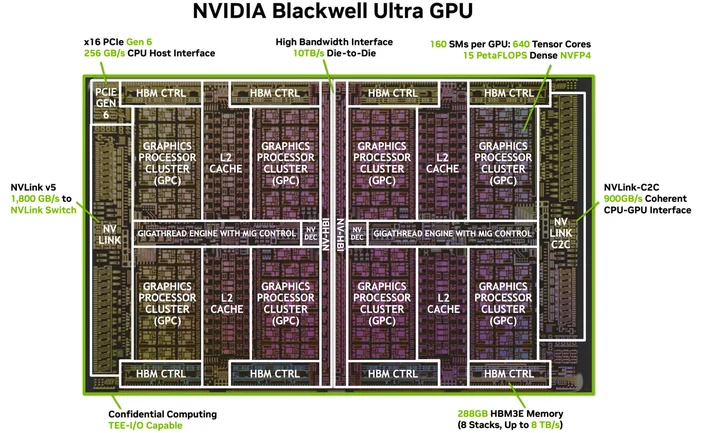
이미지 출처: NVIDIA
특별한 소프트웨어나 케이블이 필요한가요? (CUDA의 "4K용 HDMI" 같은 것)
특별한 케이블은 필요하지 않지만, 올바른 소프트웨어 스택은 필요합니다. CUDA는 NVIDIA의 플랫폼으로, 애플리케이션은 드라이버, 툴킷, 라이브러리를 통해 이를 활용합니다. NVIDIA 드라이버와 (필요한 경우) CUDA 툴킷이 설치되면, 많은 인기 애플리케이션과 프레임워크가 이미 CUDA 가속을 활용하도록 구축되어 있어 지원되는 애플리케이션은 그냥… 사용하기만 하면 됩니다.
어떤 GPU가 CUDA를 지원하나요?
CUDA는 NVIDIA GPU 제품군 전반(게이밍 및 크리에이션용 GeForce/RTX, 프로페셔널 RTX, 데이터센터 GPU)에서 CUDA 지원 GPU에서 실행됩니다. 프로그래밍 가이드에 따르면 해당 모델은 여러 GPU 세대와 SKU에 걸쳐 확장 가능하며, NVIDIA는 CUDA 지원 GPU 목록과 컴퓨팅 성능을 유지 관리합니다.
CUDA 코어는 "셰이더 코어"와 같은 것인가요?
일상적인 GPU 용어에서, 네비디아 GPU의 경우 "CUDA 코어"는 각 SM 내부에서 셰이딩 및 일반 연산을 위해 사용되는 프로그래밍 가능한 FP32/INT32 산술 연산 장치(ALU)를 가리킵니다.
왜 CUDA 코어 수는 세대마다 이렇게 다른가요?
아키텍처는 진화하기 때문이다. 앰퍼는 FP32 데이터 경로를 변경했으며(클럭당 작업량 증가), 아다는 캐시를 전면 개편하여 성능이 코어 수에 선형적으로 비례하지 않도록 했다.
워프가 뭐였더라?
SM에서 동기화되어 실행되는 32개의 스레드 그룹. 애플리케이션은 수천 개의 스레드를 생성하며, GPU는 하드웨어를 지속적으로 활용하기 위해 이를 워프로 스케줄링합니다.
CUDA 코어가 AI에 도움이 되나요?
네, 하지만 현대 AI의 주요 가속기는 텐서 코어입니다. CUDA 코어는 여전히 해당 파이프라인에서 주변 작업을 많이 처리합니다.
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.