BLOG
Gemma 4: Il nuovo modello aperto di Google e perché funziona al meglio sui PC di uso comune
Ultimo aggiornamento:
Google ha appena lanciato Gemma 4, la sua famiglia di modelli a parametri liberi più potente mai realizzata, e si tratta di una novità importante per chiunque utilizzi l'IA in locale su hardware di uso comune. Rilasciata il 31 marzo 2026 con una licenza Apache 2.0 completamente permissiva, Gemma 4 è progettata per offrire prestazioni all'avanguardia su GPU di consumo e persino su laptop, senza bisogno di alcun abbonamento.
La gamma comprende quattro dimensioni: E2B (2,3 miliardi di parametri effettivi), E4B (4,5 miliardi di parametri effettivi), una variante Mixture-of-Experts da 26 miliardi con soli 4 miliardi di parametri attivi e un modello denso da 31 miliardi. Ciò consente di disporre, all’interno di un’unica famiglia, di modelli che spaziano da quelli ottimizzati per l’edge computing a quelli quasi all’avanguardia, il tutto eseguibile su PC del tipo che gli appassionati stanno già assemblando.

Cosa distingue Gemma 4
Gemma 4 non è solo più grande, ma anche più intelligente sotto ogni aspetto. Ecco alcuni punti salienti:
- Ragionamento avanzato e agenti: pianificazione in più fasi, matematica, programmazione e flussi di lavoro autonomi pronti all'uso.
- Multimodale: gestisce testo e immagini in modo nativo, con supporto audio nelle varianti più compatte E2B ed E4B. L'analisi dei documenti, il riconoscimento dei grafici e l'OCR della scrittura manuale funzionano tutti con un unico comando.
- Contesto esteso: 128.000 token per i modelli E2B/E4B e ben 256.000 token per i modelli 26B MoE e 31B, una lunghezza sufficiente per caricare un intero codice sorgente o una pila di documenti.
- Multilingue: addestrato su oltre 140 lingue, con un ottimo supporto predefinito per decine di esse.
È disponibile su Hugging Face in versioni pre-addestrate e ottimizzate per istruzioni specifiche, ed è immediatamente compatibile con gli strumenti che già utilizzi, quali Ollama, LM Studio, llama.cpp, vLLM e Transformers.
Perché i PC consumer rappresentano il punto di forza di Gemma 4
Gemma 4 è stato progettato ponendo l'inferenza locale come obiettivo prioritario, e i dati lo confermano. NVIDIA e Google hanno collaborato alle ottimizzazioni "day-zero" per le schede RTX, e il recente lavoro su llama.cpp ha ridotto l'utilizzo della memoria della cache KV di quasi il 40% in scenari con contesti lunghi.
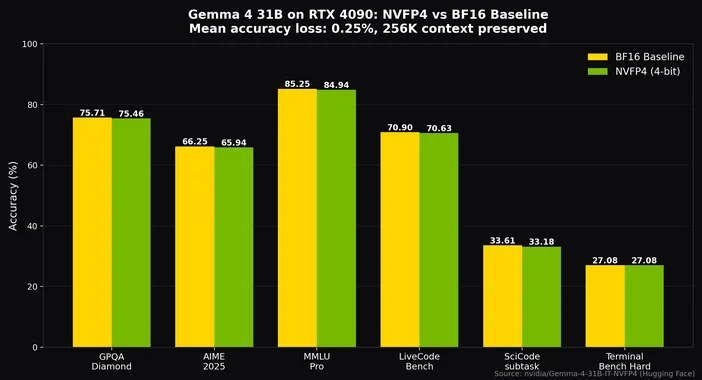
Con la quantizzazione Q4_K_M, il punto di equilibrio ideale per la maggior parte delle configurazioni, è possibile far stare il modello MoE da 26 miliardi di parametri su una scheda da 24 GB come una RTX 4090 o una 3090, lasciando spazio per un contesto da 8.000 token, e raggiungere comunque ben oltre 20 token al secondo. Con la quantizzazione NVFP4 di NVIDIA, anche il modello denso da 31 miliardi di parametri si adatta a una singola RTX 4090 con una perdita di precisione di solo circa lo 0,25%, preservando al contempo l'intero contesto da 256K.
Guida rapida alla costruzione
E2B / E4B (edge e bassa latenza): una RTX 3060 o 4060 con 8 o 12 GB di VRAM e un moderno Ryzen 5 o Core i5 è più che sufficiente. Abbinatela a 32 GB di DDR5 e a un sistema di raffreddamento AIO silenzioso se prevedete di effettuare sessioni prolungate.
26B MoE / 31B dense (per il ragionamento e l'elaborazione multimodale): punta su una RTX 4090 (o una 3090 se ne possiedi già una), un Ryzen 7 / Core i7 o superiore, 64 GB di DDR5, un SSD NVMe Gen4 veloce per il caricamento dei modelli e un alimentatore da 850 W o più in un case con un'ottima ventilazione. Un sistema come il CORSAIR iCUE LINK TITAN RX RGB 360mm AIO mantiene la GPU e la CPU a temperature ottimali sotto carichi di inferenza prolungati.

La serie RTX 50 offre a Gemma 4 ancora più margine di manovra per contesti più ampi e un'inferenza più veloce.
Guida rapida sul PC
1. Installa Ollama o LM Studio.
2. Scarica un modello Gemma 4 da Hugging Face (inizia con gemma4:e4b se sei alle prime armi, oppure con gemma4:31b se disponi di VRAM sufficiente).
3. Eseguire l'inferenza e prevedere una velocità di 50, 100+ token al secondo sulle schede RTX serie 40 per i modelli più piccoli.
4. Prova la funzione multimodale: carica un'immagine insieme a un prompt e lascia che analizzi uno screenshot, un grafico o una foto.
Gemma 4 On-Device: ora è disponibile anche in versione mobile
La funzionalità Edge Focus di Gemma 4 è estesa anche agli smartphone. Le varianti più compatte E2B ed E4B funzionano con CPU Arm e GPU mobili, garantendo una latenza quasi nulla per il riconoscimento vocale, l'analisi delle immagini e gli assistenti integrati nel dispositivo, senza bisogno del cloud. Lo stack AI Edge di Google e Android AICore ne rendono possibile l'utilizzo a livello di sistema su Android, mentre gli sviluppatori iOS possono sfruttare CPU e GPU tramite Metal.
Gemma 4 è la prova più evidente finora che i PC consumer di fascia alta non sono solo macchine da gioco, ma vere e proprie workstation per l'IA. Pesi aperti, una licenza permissiva, un livello di ragionamento all'avanguardia e una finestra di contesto da 256K che sta effettivamente su una singola GPU. Se possiedi già un sistema CORSAIR moderno, sei già a metà strada verso una vera workstation per l'IA locale. Se ne state configurando una, puntate su una scheda da 24 GB, 64 GB di DDR5 e un sistema di raffreddamento a circuito chiuso che non ceda sotto un carico prolungato.

Vuoi eseguire Gemma in locale? Scopri la CORSAIR AI Workstation 300
Se cerchi un modo senza compromessi per eseguire Gemma 4 (e altri modelli open source) interamente sul tuo hardware, la CORSAIR AI Workstation 300 è stata progettata proprio per questo. Combina un AMD Ryzen AI Max+ 395 con l'iGPU Radeon 8060S e fino a 96 GB di VRAM unificata su 128 GB di memoria LPDDR5X-8000, offrendoti spazio sufficiente per caricare e mettere a punto grandi varianti di Gemma localmente senza ricorrere al paging su disco. Una NPU dedicata da 50 TOPS accelera l'inferenza e l'intero sistema sta in uno chassis da 4,4 litri che puoi mettere sulla tua scrivania. Per sviluppatori e ricercatori che vogliono privacy, bassa latenza e costi zero per token, è uno dei modi migliori per mettere Gemma al lavoro.
PRODOTTI DELL'ARTICOLO
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.