Uruchomienie dużego modelu językowego (LLM) na własnym komputerze może wydawać się trudne, ale w rzeczywistości jest to zaskakująco proste. „Lokalny LLM” oznacza po prostu, że sztuczna inteligencja działa na Twoim sprzęcie, bez chmury, bez konta, a Twoje dane pozostają u Ciebie. Pomyśl o prywatnych burzach mózgów, pomocy w pisaniu kodu i pytaniach i odpowiedziach dotyczących dokumentów, a wszystko to bez wysyłania czegokolwiek do sieci. Jeśli brzmi to dobrze, przejdźmy od zera do pierwszego polecenia.
Jakich narzędzi używamy?
Najbardziej przyjazną dla początkujących opcją jest obecnie Ollama, darmowa aplikacja, która pobiera i uruchamia szeroki katalog otwartych modeli za pomocą jednowierszowych poleceń (obecnie jest dostępna jako aplikacja na komputery z systemem Windows i macOS, więc nie musisz żyć w terminalu).
Jeśli wolisz bardziej wizualne, kompleksowe doświadczenie, LM Studio (również bezpłatny) jest kolejnym doskonałym wyborem do odkrywania, uruchamiania i zarządzania lokalnymi modelami. Open WebUI to lekki, samodzielnie hostowany interfejs czatu, który może działać na bazie Ollama. Wybierz jeden lub połącz je ze sobą.


Wymagania sprzętowe i systemowe
- System operacyjny: Windows 10/11, macOS lub Linux (poniżej przedstawimy przykłady dla systemu Windows).
- Pamięć i pamięć masowa: 16–32 GB pamięci RAM jest wystarczające dla modeli o parametrach 7–13B; większa ilość pamięci RAM pomaga w przypadku większych kontekstów. Należy zachować kilkadziesiąt GB wolnego miejsca na dysku SSD dla modeli i pamięci podręcznej.
- GPU (opcjonalne, ale pomocne): Nowoczesny procesor graficzny przyspiesza działanie i pozwala na uruchamianie większych modeli. W systemie Windows Ollama obsługuje przyspieszenie GPU i publikuje wersje zoptymalizowane pod kątem AMD.
- Uwaga dotycząca zintegrowanych układów graficznych AMD (APU): Nowe systemy Ryzen AI Max+ mogą współdzielić pamięć systemową jako „zmienną pamięć graficzną”, udostępniając do 96 GB pamięci VRAM dla iGPU przy odpowiedniej konfiguracji — przydatne w przypadku większych modeli w domu.
Szybki start (Windows): najszybsza droga do pierwszego monitu
- Zainstaluj Ollama
- Pobierz instalator dla systemu Windows z Ollama lub zainstaluj za pomocą Winget:„winget install --id Ollama.Ollama”.
Po instalacji będziesz mieć zarówno aplikację Ollama (GUI), jak i narzędzie wiersza poleceń.
- Uruchom i sprawdź
- Otwórz aplikację Ollama na komputerze i zaloguj się, jeśli pojawi się monit (do korzystania lokalnego nie jest wymagana chmura).
- Lub sprawdź CLI: „ollama --version”.(Zobaczysz numer wersji).
- Wyciągnij model startowy
- W aplikacji przeglądaj i pobieraj modele. Lub w terminalu: „ollama run llama3:8b
- „Spowoduje to pobranie modelu i wyświetlenie monitu — wpisz pytanie i gotowe. W bibliotece Ollama możesz przeglądać wiele modeli (Gemma, Llama, Qwen, OLMo i inne).
- (Opcjonalnie) Włącz przyspieszenie GPU
- Aktualizuj sterowniki graficzne. Ollama udostępnia kompilacje dla systemu Windows z przyspieszeniem AMD, a AMD dokumentuje ścieżki DirectML/ROCm dla modeli LLM na Radeon. W aplikacji Ollama sprawdź, czy karta graficzna została wykryta (lub obserwuj wykorzystanie karty graficznej w Menedżerze zadań podczas generowania).
Który model warto wypróbować jako pierwszy?
- „Mały i szybki”: gemma3:1b lub llama3:8b – dobry do szybkich odpowiedzi i sprzętu o niskiej wydajności.
- „Zrównoważone”: modele 7B–13B (np. olmo2:7b, llama3:8b instruct) solidne do ogólnego zastosowania.
- „Większe mózgi”: modele 20B+ (np. gpt-oss:20b, większe warianty Llama) wymagają więcej pamięci RAM/VRAM i cierpliwości, ale doskonale sprawdzają się w trudniejszych zadaniach. Można je pobrać bezpośrednio w aplikacji lub za pomocą polecenia ollama run <model>.
Wskazówki dotyczące optymalizacji lokalnego LLM
- Długość kontekstu: większy nie zawsze znaczy lepszy. Ogromne konteksty (np. 32–64 tys. tokenów) mogą znacznie spowolnić generowanie. Zacznij od 4–8 tys. i zwiększaj tylko w razie potrzeby.
- Kwantyzacja: Większość modeli dostarczanych przez aplikacje jest już skwantyzowana, co ułatwia dopasowanie większych modeli do ograniczonej pamięci VRAM.
- Przechowywanie: Modele należy przechowywać na dyskach SSD; dyski HDD będą działały wolno.
- Sterowniki: Regularnie aktualizuj sterowniki GPU i aplikację. Lokalna sztuczna inteligencja szybko się rozwija.
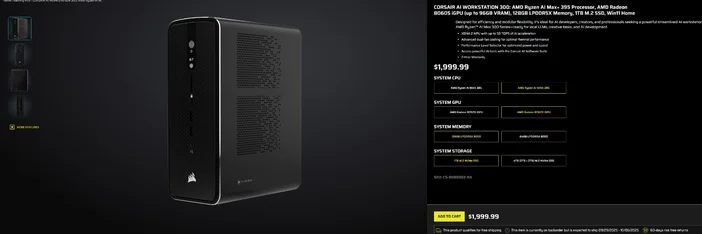
Korzystanie z CORSAIR AI WORKSTATION 300
Jeśli wolisz pominąć stopniową budowę i chcesz mieć kompaktowy, cichy komputer stacjonarny, który jest gotowy do lokalnego uczenia się modeli LLM od razu po wyjęciu z pudełka, to CORSAIR AI WORKSTATION 300 spełnia wiele wymagań twórców i programistów:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (do 96 GB pamięci VRAM), XDNA 2 NPU do 50 TOPS
- Pamięć i pamięć masowa: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB + 2 TB)
- System operacyjny: Windows 11 Home
- Konstrukcja: obudowa o niewielkich rozmiarach i pojemności 4,4 l z podwójnym wentylatorem chłodzącym i przełącznikiem poziomu wydajności
Ta „pamięć VRAM o pojemności do 96 GB” w układzie Radeon iGPU szczególnie dobrze współgra z narzędziami systemu Windows, które mogą przydzielać dużą pamięć współdzieloną do procesora graficznego, co jest przydatne w przypadku większych modeli lokalnych i dłuższych kontekstów, gdy są one potrzebne. Jest to przejrzysta, kompaktowa ścieżka do lokalnego rozwoju sztucznej inteligencji bez ograniczania pojemności.
Często zadawane pytania
Czy potrzebuję dedykowanego procesora graficznego, aby uruchomić lokalny model LLM?
Nie. Mniejsze modele można uruchamiać na systemach wyposażonych wyłącznie w procesor CPU, jednak reakcje będą wolniejsze. Nowoczesny procesor graficzny GPU lub zaawansowany procesor APU z dużą pamięcią współdzieloną zwiększa szybkość działania i pozwala na zwiększenie rozmiaru modelu.
Czy to jest prywatne?
Tak. Dzięki lokalnym narzędziom, takim jak Ollama lub LM Studio, polecenia i dane domyślnie pozostają na Twoim komputerze. (Dodane integracje mogą działać inaczej, dlatego zawsze sprawdzaj ustawienia).
Gdzie mogę znaleźć modele?
Biblioteka Ollama zawiera listę popularnych, aktualnych opcji (Llama, Gemma, Qwen, OLMo i inne). Każda strona modelu zawiera rozmiary i przykładowe polecenia.
Czy stacja robocza CORSAIR AI WORKSTATION 300 może obsługiwać duże modele?
Został zaprojektowany z myślą o lokalnych modelach LLM, wyposażony w 128 GB pamięci i zintegrowany procesor graficzny, który może uzyskać dostęp do 96 GB pamięci VRAM, co zapewnia doskonałą rezerwę mocy obliczeniowej dla zaawansowanych lokalnych obciążeń i długich kontekstów, zwłaszcza że sterowniki AMD dla systemu Windows rozszerzają obsługę dużych alokacji. Rzeczywista przepustowość zależy od rozmiaru modelu, kwantyzacji i ustawień.
PRODUKTY W ARTYKULE
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.