HOW TO
Como executar um LLM local no Windows (sem necessidade de recorrer à nuvem)
Última atualização:
Executar um LLM localmente significa que o modelo fica no seu computador e que as suas instruções (e quaisquer ficheiros que lhe forneça) não precisam de sair do seu computador. Sem conta na nuvem. Sem chaves API. Sem «vamos treinar com os seus dados… provavelmente não… talvez». Apenas você, o seu computador e um modelo a realizar qualquer tarefa que lhe atribuir.
O que é, exatamente, um «LLM local»?
Um LLM local é um modelo de linguagem de grande dimensão que funciona no seu computador, em vez de num servidor remoto. Na prática, isso significa normalmente que descarrega os ficheiros do modelo, os carrega numa aplicação local e conversa com eles da mesma forma que conversaria com um assistente na nuvem, só que o «servidor» é o seu PC.
«Executar» um LLM localmente significa quase sempre fazer inferências (gerar respostas), e não treinar um modelo totalmente novo a partir do zero.
Por que utilizar um LLM local?
Existem algumas razões pelas quais as pessoas mudam dos LLMs na nuvem para os locais:
- Privacidade: As suas instruções permanecem no dispositivo (desde que não utilize conectores na nuvem).
- Utilização offline: Depois de descarregar o modelo, pode executá-lo sem ligação à Internet.
- Sem limites de utilização: sem restrições de velocidade, sem mensagens do tipo «já esgotou a quota de hoje», sem surpresas na fatura.
- Controlo: Escolha o modelo que desejar, não está vinculado a um modelo de subscrição.
É claro que está a trocar a conveniência pelo controlo. Um modelo na nuvem pode parecer mágico; um modelo local pode parecer mágico, dependendo do seu hardware.
O que é necessário para executar um LLM local?
Resumindo: a CPU funciona, a GPU ajuda e a memória é importante.
Eis o que realmente influencia se vais divertir-te:
- RAM / VRAM: Os modelos maiores requerem mais memória. Se a memória se esgotar, o modelo deixará de funcionar.
- Armazenamento: Os modelos podem ser grandes. Algumas bibliotecas alertam que o espaço de armazenamento necessário pode atingir dezenas a centenas de GB, dependendo do modelo que descarregar.
- GPU: Se a sua aplicação for compatível com a sua GPU, normalmente irá notar um grande aumento de velocidade.
Um computador moderno com Windows 10/11 e 32 GB ou mais de RAM constitui uma base sólida para modelos locais de menor dimensão, e uma maior quantidade de memória permite executar modelos de maior dimensão com maior facilidade.
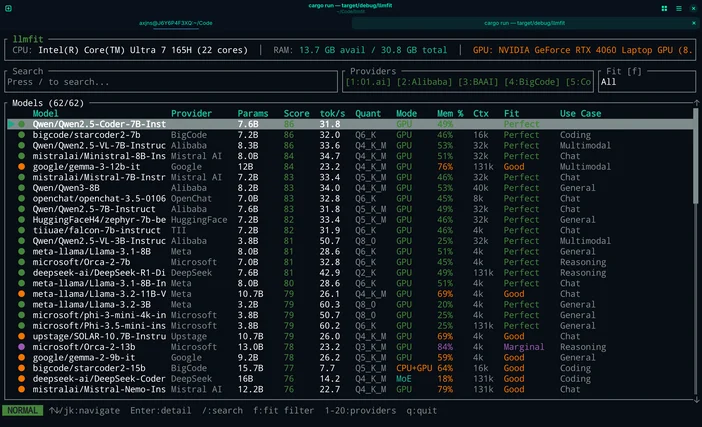
Escolha uma aplicação de «execução de LLM local»
LM Studio (interface gráfica intuitiva)
O LM Studio é uma aplicação para computador que permite descarregar modelos e conversar com elas localmente. Também inclui uma API local programável para programadores.
Ollama (interface de linha de comandos simples + API local)
O Ollama funciona como uma aplicação nativa do Windows e oferece um fluxo de trabalho de linha de comandos, além de um ponto de extremidade de API HTTP local. É compatível com GPUs NVIDIA e AMD Radeon no Windows.
llama.cpp (para quem gosta de mexer no código)
Se pretende o máximo controlo, o llama.cpp é um motor de inferência de código aberto muito utilizado, que inclui instruções de compilação e vários backends.

Instale e execute o seu primeiro modelo
Os modelos maiores requerem mais RAM e/ou VRAM. Se não tiver memória suficiente, irá enfrentar um desempenho lento, falhas ou uma troca constante de dados para o disco (o que dá a sensação de que o seu PC está a funcionar a passo de caracol).
Uma regra prática segura para modelos quantizados em int4:
- 8 GB de RAM → ~3 mil milhões de modelos
- 16 GB de RAM → ~7 mil milhões de modelos
- 32 GB de RAM → ~13 mil milhões de modelos
E se estiver a recorrer à aceleração por GPU:
- 6 GB de VRAM → ~3 mil milhões de modelos
- 8 GB de VRAM → ~7 mil milhões de modelos
- 12 GB de VRAM → ~13 mil milhões de modelos
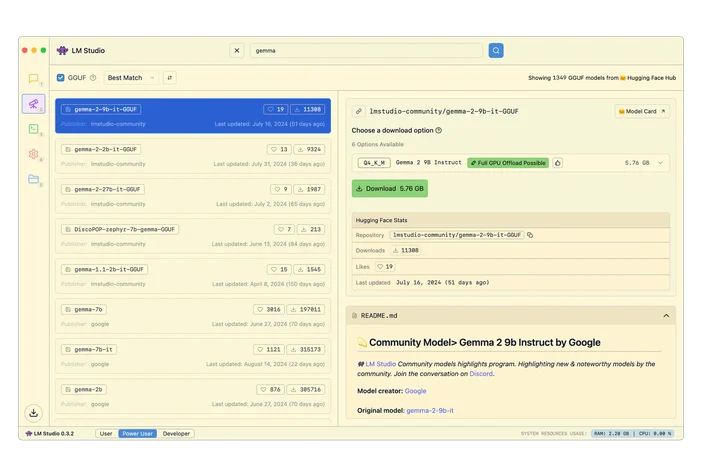
Ou, se não quiser adivinhar, pode usar o LLMfit para ajustar os modelos ao seu hardware específico.
O LLMfit é uma ferramenta de terminal que identifica a sua CPU, RAM e GPU/VRAM e, em seguida, classifica os modelos com base na compatibilidade, velocidade prevista, contexto e qualidade, para quepossa ver o que funcionará bem antes de fazer qualquer download.
Para que serve:
- Encontrar modelos que se ajustem realmente aos seus limites de RAM/VRAM
- Verificar a quantização recomendada (para não sobrecarregar a memória)
- Obter uma lista de finalistas classificada em vez de navegar sem fim por plataformas de modelos
Como utilizá-lo neste fluxo de trabalho:
- Execute o llmfit para analisar o hardware do seu sistema
- Veja as principais sugestões / recomendações
- Escolha um tamanho de modelo adequado à sua máquina e, em seguida, faça o download no LM Studio / Ollama / llama
Está tudo pronto!
É isso mesmo. Escolha um executável, descarregue um modelo compatível com o seu hardware e comece a dar instruções! Tudo fica no seu computador. Não precisa de uma licenciatura em informática, de uma assinatura de serviços na nuvem nem de passar o fim de semana a resolver problemas. Todo o processo demora mais ou menos o mesmo tempo que instalar um jogo. E assim que estiver a funcionar, terá um assistente de IA privado e offline que funciona ao seu ritmo.
Onde se encaixa o CORSAIR AI300
Se pretende realmente executar LLMs locais no Windows, especialmente se deseja modelos maiores, janelas de contexto mais amplas ou um desempenho mais fluido, é aqui que entra CORSAIR AI Workstation 300 (AI300) e o Pacote de Software CORSAIR AI o ajudam a atingir o próximo nível.
A inferência local costuma ser limitada pela memória e pela largura de banda. O AI300 foi concebido tendo em conta essa realidade:
- Uma estação de trabalho compacta concebida para fluxos de trabalho de IA locais
- Configuração com grande capacidade de memória que lhe dá margem para trabalhar com modelos de maior dimensão
- Comportamento da memória gráfica concebido para se adaptar a casos de utilização de IA
- Um seletor de desempenho ao nível do hardware (Silencioso / Equilibrado / Máximo) para que possa decidir se prefere silêncio ou velocidade

Preciso de uma GPU NVIDIA para executar um LLM local no Windows?
Não. Algumas ferramentas suportam explicitamente a AMD no Windows; por exemplo, a documentação do Ollama para Windows menciona o suporte tanto para GPUs NVIDIA como para GPUs AMD Radeon.
É possível executar um LLM local totalmente offline?
Sim, depois de ter descarregado a aplicação e os ficheiros do modelo. A instalação inicial e o download dos modelos requerem normalmente ligação à Internet, mas a inferência pode ser executada offline assim que tudo estiver armazenado localmente.
A IA local é automaticamente privada?
Pode ser, mas depende da sua configuração. A inferência local significa que o modelo é executado no seu dispositivo, mas algumas aplicações oferecem ligações opcionais à nuvem. Se o seu objetivo for «não necessitar da nuvem», mantenha as integrações com a nuvem desativadas e utilize modelos exclusivamente locais.
Por que é que o meu modelo local é lento?
Normalmente, uma destas opções:
- O modelo é demasiado grande para a RAM/VRAM disponível
- Está a utilizar apenas a CPU quando a aceleração por GPU está disponível
- Escolheu um comprimento de contexto elevado e isso está a consumir muita memória
- O seu espaço de armazenamento está cheio (sim, isso é importante)
PRODUTOS NO ARTIGO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.