BLOG
Gemma 4 : le nouveau modèle ouvert de Google et pourquoi il fonctionne mieux sur les PC grand public
Dernière mise à jour :
Google vient de lancer Gemma 4, sa gamme de modèles à paramètres libres la plus performante à ce jour, ce qui constitue une avancée majeure pour tous ceux qui utilisent l'IA en local sur du matériel courant. Sorti le 31 mars 2026 sous une licence Apache 2.0 entièrement permissive, Gemma 4 est conçu pour offrir des capacités de pointe sur les cartes graphiques grand public et même sur les ordinateurs portables, sans aucun abonnement requis.
La gamme comprend quatre tailles : E2B (2,3 milliards de paramètres effectifs), E4B (4,5 milliards), une variante « Mixture-of-Experts » de 26 milliards de paramètres ne comptant que 4 milliards de paramètres actifs, et un modèle dense de 31 milliards de paramètres. Cela vous offre toute la gamme, des modèles adaptés à la périphérie jusqu’à ceux proches de la frontière, au sein d’une seule famille, et tous fonctionnent sur le type de PC que les assembleurs proposent déjà.

Ce qui distingue Gemma 4
Gemma 4 n'est pas seulement plus puissante, elle est aussi plus performante à tous les niveaux. Voici quelques points forts :
- Raisonnement avancé et agents : planification en plusieurs étapes, mathématiques, programmation et flux de travail autonomes prêts à l'emploi.
- Multimodal : prend en charge nativement le texte et les images, avec une prise en charge audio sur les modèles plus compacts E2B et E4B. L'analyse de documents, la reconnaissance de graphiques et la reconnaissance optique de caractères manuscrits fonctionnent toutes à partir d'une seule commande.
- Contexte massif : 128 000 tokens pour les modèles E2B/E4B, et pas moins de 256 000 tokens pour les modèles denses 26B MoE et 31B, ce qui est largement suffisant pour y intégrer une base de code complète ou une pile de documents.
- Multilingue : formé sur plus de 140 langues, avec une prise en charge immédiate de plusieurs dizaines d'entre elles.
Il est disponible sur Hugging Face sous forme de variantes pré-entraînées et optimisées pour des tâches spécifiques, et fonctionne dès le premier jour avec les outils que vous utilisez déjà : Ollama, LM Studio, llama.cpp, vLLM et Transformers.
Pourquoi les PC grand public constituent le créneau idéal pour Gemma 4
Gemma 4 a été conçu en plaçant l'inférence locale au cœur de ses priorités, et les chiffres le confirment. NVIDIA et Google ont collaboré pour mettre en place des optimisations dès le lancement des cartes RTX, et les récents travaux sur llama.cpp ont permis de réduire l'utilisation de la mémoire du cache KV de près de 40 % dans les scénarios à contexte long.
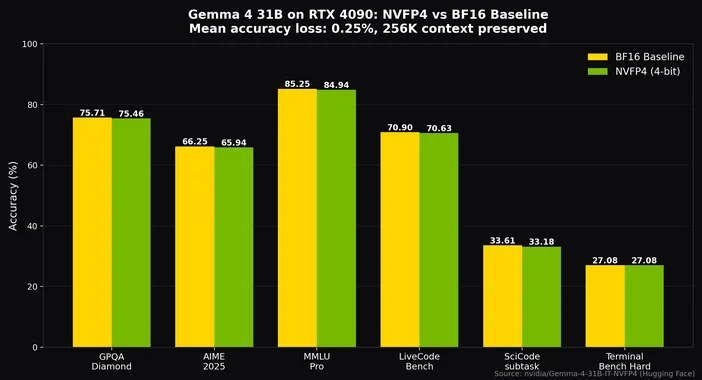
Avec la quantification Q4_K_M, qui constitue le juste milieu pour la plupart des configurations, il est possible de faire tenir le modèle MoE de 26 milliards de paramètres sur une carte de 24 Go, comme une RTX 4090 ou une 3090, tout en conservant de la place pour un contexte de 8 000 tokens, et d'atteindre ainsi largement plus de 20 tokens par seconde. Avec la quantification NVFP4 de NVIDIA, même le modèle dense de 31 milliards de paramètres tient sur une seule RTX 4090 avec une perte de précision d'environ 0,25 % seulement, tout en conservant l'intégralité du contexte de 256 000 tokens.
Guide de montage rapide
E2B / E4B (edge et faible latence) : une RTX 3060 ou 4060 dotée de 8 ou 12 Go de mémoire vidéo, associée à un processeur Ryzen 5 ou Core i5 récent, suffit amplement. Ajoutez-y 32 Go de mémoire DDR5 et un système de refroidissement tout-en-un silencieux si vous prévoyez de longues sessions.
26 milliards de paramètres / 31 milliards de paramètres (pour le raisonnement et le traitement multimodal) : optez pour une RTX 4090 (ou une 3090 si vous en possédez déjà une), un Ryzen 7 / Core i7 ou supérieur, 64 Go de DDR5, un disque NVMe Gen4 rapide pour le chargement des modèles, et un bloc d'alimentation de 850 W ou plus dans un boîtier offrant un excellent flux d'air. Un système tel que le CORSAIR iCUE LINK TITAN RX RGB 360 mm AIO permet de maintenir le GPU et le CPU à une température optimale sous des charges d'inférence soutenues.

La série RTX 50 offre à Gemma 4 encore plus de marge de manœuvre pour des contextes plus vastes et une inférence plus rapide.
Guide de démarrage rapide sur votre PC
1. Installez Ollama ou LM Studio.
2. Téléchargez un modèle Gemma 4 depuis Hugging Face (commencez par gemma4:e4b si vous débutez, ou par gemma4:31b si vous disposez de suffisamment de mémoire vidéo).
3. Lancez l'inférence et attendez-vous à un débit de 50, voire plus de 100 tokens par seconde sur les cartes RTX de la série 40 pour les modèles les plus compacts.
4. Testez la fonctionnalité multimodale : ajoutez une image et une instruction, puis laissez l'application analyser une capture d'écran, un graphique ou une photo.
Gemma 4 sur appareil : désormais disponible en version mobile
L'approche « edge » de Gemma 4 s'étend aux téléphones. Les variantes plus compactes E2B et E4B fonctionnent avec des processeurs Arm et des processeurs graphiques mobiles, offrant une latence quasi nulle pour la reconnaissance vocale, l'analyse d'images et les assistants intégrés, sans nécessiter le cloud. La pile IA Edge de Google et Android AICore permettent de l'utiliser à l'échelle du système sous Android, tandis que les développeurs iOS peuvent exploiter le processeur et le processeur graphique via Metal.
Gemma 4 est la preuve la plus flagrante à ce jour que les PC grand public haut de gamme ne sont pas seulement des machines de jeu, mais de véritables stations de travail dédiées à l'IA. Des poids ouverts, une licence permissive, un raisonnement de pointe et une fenêtre de contexte de 256 Ko qui tient réellement sur un seul GPU. Si vous disposez déjà d'une configuration CORSAIR moderne, vous avez déjà fait le plus gros du chemin vers une véritable station de travail d'IA locale. Si vous êtes en train d'en configurer une, prévoyez une carte de 24 Go, 64 Go de DDR5 et un circuit de refroidissement capable de résister à une charge soutenue.

Vous souhaitez exécuter Gemma en local ? Découvrez la CORSAIR AI Workstation 300
Si vous recherchez une solution sans compromis pour exécuter Gemma 4 (et d'autres modèles ouverts) entièrement sur votre propre matériel, la CORSAIR AI Workstation 300 est spécialement conçue à cet effet. Elle associe un processeur AMD Ryzen AI Max+ 395 à l'iGPU Radeon 8060S et offre jusqu'à 96 Go de VRAM unifiée sur une mémoire totale de 128 Go de LPDDR5X-8000, vous donnant ainsi suffisamment de marge pour charger et affiner localement de grandes variantes de Gemma sans avoir à recourir à la pagination sur disque. Un NPU dédié de 50 TOPS accélère l'inférence, et l'ensemble du système tient dans un châssis de 4,4 L que vous pouvez poser sur votre bureau. Pour les développeurs et les chercheurs qui recherchent la confidentialité, une faible latence et des coûts par jeton nuls, c'est l'un des meilleurs moyens de mettre Gemma à l'œuvre.
PRODUITS DANS L'ARTICLE
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.