Om du kör AI lokalt har du säkert stött på rådet: ”Skaffa en bra GPU.” Men vad innebär det egentligen? Och är din CPU verkligen så värdelös? Svaret är inte så enkelt som ”GPU bra, CPU dålig”. Det som spelar roll är hur respektive processor hanterar beräkningarna bakom AI-inferens och vilken som kan flytta data tillräckligt snabbt för att hänga med.
Vad händer egentligen under AI-inferens?
När du kör en lokal LLM-modell eller bildmodell utför din hårdvara samma sak om och om igen: matrismultiplikation. Modellen tar emot din indata, omvandlar den till siffror och bearbetar dessa siffror genom miljarder matematiska operationer i sina olika lager. Ju snabbare din hårdvara kan bearbeta dessa operationer, desto snabbare får du ett svar.
Detta är en inferens, där man genererar resultat från en tränad modell. Du tränar inte modellen på nytt. Du kör bara igenom beräkningarna, ett token i taget.
Hur en CPU hanterar AI-arbete
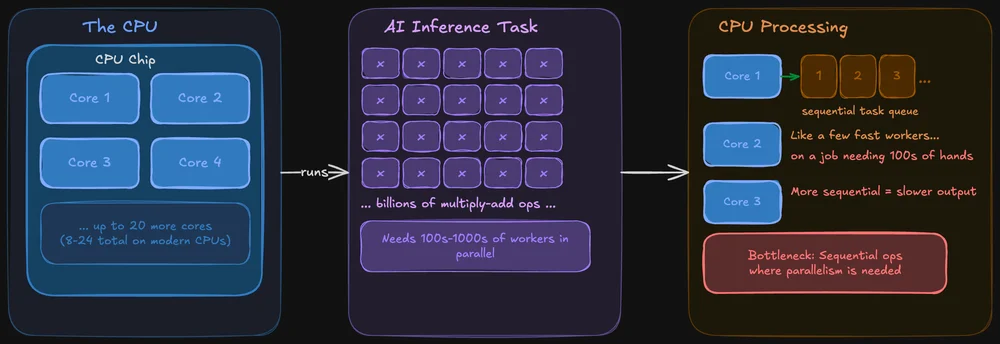
En CPU är konstruerad för att klara allt. Den hanterar operativsystemet, flikarna i webbläsaren, filsystemet och ja, den kan även köra AI-modeller. Moderna CPU:er har flera kärnor (vanligtvis 8–24 i konsumentchips), och varje kärna är kraftfull och flexibel.
Problemet: AI-inferens innebär att samma operation utförs samtidigt på enorma datamängder. En CPU klarar detta, men den bearbetar operationerna mer sekventiellt. Det är som att ha några få mycket snabba arbetare som försöker klara ett jobb som egentligen kräver hundratals händer som arbetar samtidigt.
Med det sagt är CPU:er inte helt hopplösa för lokal AI. Verktyg som llama.cpp är särskilt optimerade för inferens på CPU, och om din modell får plats i systemets RAM-minne kan du absolut köra den enbart på CPU:n. Det kommer bara att gå långsammare – ibland märkbart, ibland inte – beroende på modellens storlek.
Hur en GPU hanterar AI-uppgifter
En GPU är utformad för parallellbearbetning. Medan en CPU kan ha 8–24 kärnor, har en modern GPU tusentals mindre kärnor som alla kan bearbeta delar av samma problem samtidigt. Detta gör att GPU:er är exceptionellt bra på den typ av storskaliga beräkningar som AI-modeller är beroende av.
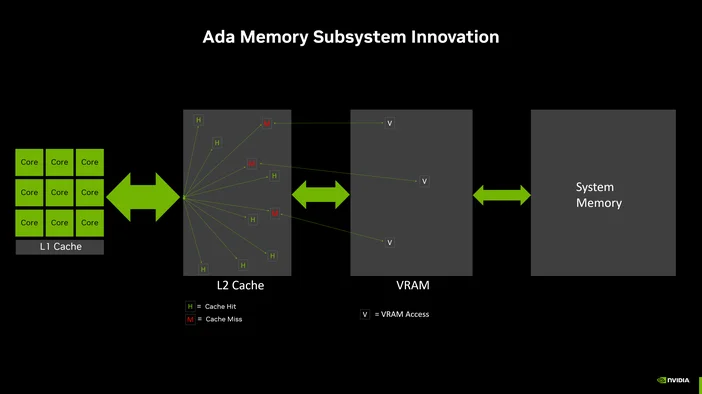
Dessutom har grafikkort ett eget dedikerat minne (VRAM) med betydligt högre bandbredd än systemets RAM-minne. Denna bandbredd är avgörande, eftersom den avgör hur snabbt data kan matas in till de tusentals kärnorna. Mer bandbredd innebär mindre väntetid och mer tid för beräkningar.
När det gäller lokal LLM-inferens handlar GPU:ns fördelar i huvudsak om två saker: parallellbearbetningskapacitet och minnesbandbredd. Båda dessa faktorer påverkar direkt hur många token per sekund som visas i utdata.
Minnesbandbredd
Här är något som överraskar de flesta: när det gäller lokal LLM-inferens är det ofta inte den rena datorkraften som är den begränsande faktorn. Det är minnesbandbredden.
Vid inferens måste modellens vikter läsas in från minnet för varje enskilt token som genereras. Om minnet inte kan mata data till processorn tillräckligt snabbt spelar det ingen roll hur många kärnor du har – de står bara där och väntar.
Det är därför VRAM-bandbredden är så viktig. Ett typiskt systemminne med DDR5 kan erbjuda en bandbredd på 50–90 GB/s. Ett modernt grafikkort som ett RTX 5090 levererar över 1 000 GB/s. Det är en skillnad i storleksordningen.
Om din modell ryms helt i VRAM kommer inferensen nästan alltid att gå snabbare på GPU än på CPU, enbart av den anledningen.
När det faktiskt är vettigt att använda enbart CPU
GPU är inte alltid lösningen. Det finns situationer där det är bättre att köra på CPU:
- Du kör en liten modell (3B-parametrar eller färre) där hastighetsskillnaden knappt märks.
- Du har inte ett kompatibelt grafikkort, eller så har ditt grafikkort inte tillräckligt med VRAM för att hantera modellen.
- Du vill utnyttja hela systemets RAM-minne (som oftast är betydligt större än VRAM) för att köra en större modell med lägre hastighet.
- Du använder en bärbar dator eller en dator där strömförbrukningen eller värmeutvecklingen från grafikkortet är ett problem.
Inferens på CPU har blivit betydligt bättre tack vare kvantisering (där modellens precision minskas för att använda mindre minne) och ramverk som är optimerade för detta. En kvantiserad 7B-modell på en modern CPU med 32 GB RAM fungerar tillräckligt bra för många uppgifter.


Hur är det med avlastning?
Om din modell är för stor för VRAM men du ändå vill ha GPU-acceleration, stöder de flesta lokala LLM-verktyg partiell avlastning. Det innebär att vissa lager i modellen körs på GPU:n medan resten körs på CPU:n.
Det är en avvägning: man får en del av GPU:ns hastighetsfördelar, men de CPU-begränsade lagren blir en flaskhals. Ju fler lager man får plats med i VRAM, desto snabbare blir det. Och om bara ett fåtal lager hamnar på GPU:n kan den extra belastningen som uppstår när data flyttas fram och tillbaka faktiskt göra det långsammare än ren CPU-inferens.
En tumregel: om du inte får plats med minst hälften av modellen i VRAM är det förmodligen bättre att köra den helt på CPU:n och slippa krånglet.
NVIDIA mot AMD inom lokal AI
NVIDIA dominerar just nu den lokala AI-marknaden, främst tack vare CUDA – deras egenutvecklade beräkningsramverk som nästan alla AI-verktyg bygger på. Om du använder LM Studio, Ollama eller llama.cpp på Windows kommer NVIDIA-grafikkort att ge dig den smidigaste upplevelsen med minst möjliga problem.
AMD håller på att komma ikapp. ROCm (AMDs svar på CUDA) har gjort stora framsteg, och verktyg som Ollama stöder uttryckligen AMD Radeon-grafikkort i Windows. Men ekosystemet är fortfarande mer begränsat, och du kan stöta på kompatibilitetsproblem beroende på vilket grafikkort du har och vilket verktyg du använder.
Om du köper en enhet specifikt för lokal AI är NVIDIA det säkraste valet just nu. Om du redan har ett AMD-grafikkort är det absolut värt att prova, men kolla först i verktygets dokumentation vilka modeller som stöds.

Var CORSAIR AI300 passar in
Om din nuvarande konfiguration orsakar flaskhalsar – oavsett om det handlar om otillräckligt med VRAM, långsam minnesbandbredd eller ett system som överhettas så fort du laddar en 13B-modell – är det just den här typen av problem som CORSAIR AI Workstation 300 (AI300) är utvecklad för att lösa.
AI300 är en kompakt arbetsstation som är utformad med hänsyn till de faktiska förhållandena vid lokal AI-inferens:
- Konfiguration med stort minne som ger utrymme för större modeller och större kontextfönster.
- Grafikminne som är skalbart för AI-arbetsbelastningar (och lite spelande).
- En prestandaväljare på hårdvarunivå (Tyst / Balanserad / Max) så att du kan prioritera hastighet när du behöver det och tystnad när du inte gör det.
- CORSAIR AI Software Stack, som förenklar installationen så att du kan ägna mindre tid åt konfigurering och mer tid åt att köra modeller.
Om du har försökt få ut det mesta av lokal AI ur ett system som inte är utformat för det, erbjuder AI300 en maskin där både hårdvaran och mjukvaran faktiskt är anpassade efter arbetsbelastningen.

PRODUKTER I ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.