Att köra en LLM lokalt innebär att modellen finns på din dator, och att dina inmatningar (samt eventuella filer du matar in) inte behöver lämna din dator. Inget molnkonto. Inga API-nycklar. Inget ”vi tränar modellen på dina data… kanske inte… kanske.” Bara du, din dator och en modell som utför alla uppgifter du ger den.
Vad är egentligen en ”lokal LLM”?
En lokal LLM är en stor språkmodell som körs på din dator istället för på en fjärrserver. I praktiken innebär det oftast att du laddar ner modellfilerna, öppnar dem i en lokal app och chattar med dem på samma sätt som du skulle chatta med en molnbaserad assistent, med den skillnaden att ”servern” är din dator.
Att ”köra” en LLM lokalt innebär nästan alltid inferens (att generera svar), inte att träna en helt ny modell från grunden.
Varför använda en lokal LLM?
Det finns flera skäl till varför människor byter från molnbaserade stora språkmodeller till lokala:
- Sekretess: Dina inmatningar sparas på enheten (så länge du inte använder molnanslutningar).
- Offlineanvändning: När modellen har laddats ner kan du köra den utan internetuppkoppling.
- Inga användningsbegränsningar: Inga hastighetsbegränsningar, inga meddelanden om att ”dagens kvot är förbrukad” och inga oväntade räkningar.
- Kontroll: Välj den modell du vill ha – du är inte bunden till något abonnemang.
Naturligtvis byter du bekvämlighet mot kontroll. En molnbaserad modell kan kännas som ren magi; en lokal modell kan kännas som ren magi beroende på vilken hårdvara du har.
Vad krävs för att köra en lokal LLM?
Kort sagt: Processorn sköter jobbet, grafikkortet hjälper till, och minnet spelar roll.
Det här är vad som faktiskt avgör om du kommer att ha roligt:
- RAM/VRAM: Större modeller kräver mer minne. Om minnet tar slut kommer modellen att sluta fungera.
- Lagringsutrymme: Modellerna kan vara stora. Vissa bibliotek varnar för att lagringsutrymmet för modellerna kan uppgå till tiotals eller hundratals GB, beroende på vilken modell du laddar ner.
- GPU: Om din app stöder din GPU brukar du märka en betydande hastighetsökning.
En modern dator med Windows 10/11 och minst 32 GB RAM är en bra utgångspunkt för mindre lokala modeller, och med mer minne kan du köra större modeller utan problem.
Välj en app för ”lokala LLM-körningar”
LM Studio (användarvänligt gränssnitt)
LM Studio är ett datorprogram som gör det möjligt att ladda ner modeller och chatta med dem lokalt. Det innehåller även ett programmerbart lokalt API för utvecklare.
Ollama (enkel kommandoradsgränssnitt + lokalt API)
Ollama körs som en inbyggd Windows-app och erbjuder ett arbetsflöde via kommandoraden samt en lokal HTTP-API-ändpunkt. Programmet har uttryckligt stöd för NVIDIA- och AMD Radeon-grafikkort i Windows.
llama.cpp (för den som gillar att experimentera)
Om du vill ha maximal kontroll är llama.cpp ett populärt inferensmotor med öppen källkod som innehåller bygginstruktioner och flera backend-alternativ.

Installera och kör din första modell
Större modeller kräver mer RAM-minne och/eller VRAM. Om du inte har tillräckligt med minne kan det leda till långsam prestanda, krascher eller ständiga överföringar till hårddisken (vilket känns som om datorn arbetar i snigelfart).
En säker tumregel för modeller med int4-kvantisering:
- 8 GB RAM → ~3 miljarder modeller
- 16 GB RAM → ~7 miljarder modeller
- 32 GB RAM → ~13 miljarder modeller
Och om du använder GPU-acceleration:
- 6 GB VRAM → ~3 miljarder modeller
- 8 GB VRAM → ~7 miljarder modeller
- 12 GB VRAM → ~13 miljarder modeller
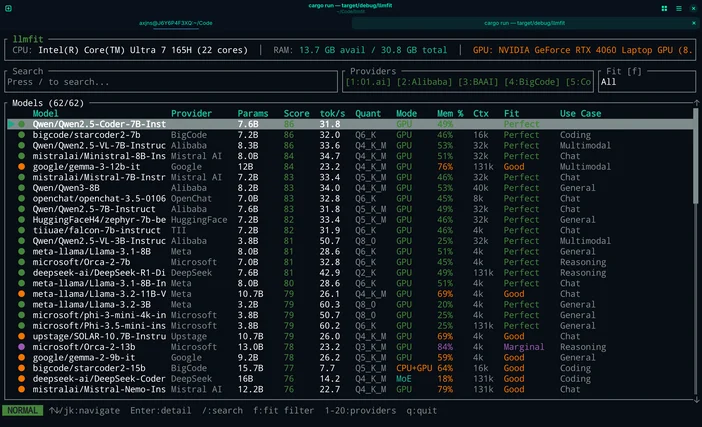
Eller om du inte vill gissa kan du använda LLMfit för att anpassa modellerna till just din hårdvara.
LLMfit är ett terminalt verktyg som identifierar din CPU, RAM och GPU/VRAM, och sedan rangordnar modellerna efter lämplighet, förväntad hastighet, sammanhang och kvalitet, så attdu kan se vilka som kommer att fungera bra innan du laddar ner något.
Vad den passar till:
- Hitta modeller som verkligen passar dina RAM-/VRAM-begränsningar
- Se rekommenderad kvantisering (så att du inte reserverar för mycket minne)
- Att få en rankad kortlista istället för plattformar som bygger på ”doomscrolling”
Så här använder du det i det här arbetsflödet:
- Kör llmfit för att skanna systemets hårdvara
- Titta på de bästa ”matchningarna”/rekommendationerna
- Välj en modellstorlek som passar din maskin och ladda sedan ner den i LM Studio / Ollama / llama
Nu är du klar!
Det är allt. Välj en körmiljö, ladda ner en modell som passar din hårdvara och börja ge kommandon! Allt finns på din egen dator. Du behöver varken en examen i datavetenskap, ett molnabonnemang eller en hel helg med felsökning. Hela processen tar ungefär lika lång tid som att installera ett spel. Och när det väl är igång har du en privat AI-assistent som fungerar offline och enligt dina villkor.
Var CORSAIR AI300 passar in
Om du verkligen vill köra lokala stora språkmodeller (LLM) på Windows, särskilt om du vill ha större modeller, större kontextfönster eller smidigare prestanda, är det här CORSAIR AI Workstation 300 (AI300) och CORSAIR AI Software Stack hjälper dig att nå nästa nivå.
Lokal inferens stöter oftast på flaskhalsar när det gäller minne och genomströmning. AI300 är utformad med hänsyn till detta:
- En kompakt arbetsstation utvecklad för lokala AI-arbetsflöden
- En konfiguration med stort minne som ger dig utrymme för större modeller
- Grafikminnets beteende som är utformat för att skala upp för AI-tillämpningar
- En prestandaväljare på hårdvarunivå (Tyst / Balanserad / Max) så att du kan välja om du vill ha tystnad eller hastighet

Behöver jag ett NVIDIA-grafikkort för att köra en lokal stor språkmodell (LLM) i Windows?
Nej. Vissa verktyg stöder uttryckligen AMD i Windows; i Ollamas Windows-dokumentation nämns till exempel stöd för både NVIDIA- och AMD Radeon-grafikkort.
Kan jag köra en lokal LLM helt offline?
Ja, efter att du har laddat ner appen och modellfilerna. Den första installationen och nedladdningen av modellerna kräver vanligtvis internetuppkoppling, men inferensen kan köras offline när allt finns lokalt.
Är lokal AI automatiskt privat?
Det kan det vara, men det beror på hur du har konfigurerat det. Lokal inferens innebär att modellen körs på din enhet, men vissa appar erbjuder valfria molnanslutningar. Om ditt mål är att ”inte behöva använda molnet” bör du hålla molnintegrationerna inaktiverade och använda modeller som endast körs lokalt.
Varför är min lokala modell så långsam?
Vanligtvis något av följande:
- Modellen är för stor för ditt tillgängliga RAM-minne/grafikminne
- Du kör enbart med CPU trots att GPU-acceleration finns tillgänglig
- Du har valt en lång kontextlängd och det slukar minne
- Ditt lagringsutrymme är fullt (ja, det spelar roll)
PRODUKTER I ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.