Att köra en stor språkmodell (LLM) på din egen dator låter skrämmande, men det är förvånansvärt lätt. En ”lokal LLM” innebär helt enkelt att AI:n körs på din hårdvara utan moln, utan konto, och dina data stannar hos dig. Tänk privat brainstorming, kodhjälp och dokumentfrågor och svar, allt utan att skicka något online. Om det låter bra, låt oss ta dig från noll till första prompten.
Vilka verktyg använder vi?
Det mest nybörjarvänliga alternativet just nu är Ollama, en gratisapp som laddar ner och kör ett brett utbud av öppna modeller med enradiga kommandon (den levereras nu med en Windows- och macOS-app, så du behöver inte sitta i en terminal).
Om du föredrar en mer visuell, allt-i-ett-upplevelse, LM Studio (också gratis) ett annat utmärkt val för att upptäcka, köra och hantera lokala modeller. Open WebUI är ett lättviktigt, självhostat chattgränssnitt som kan placeras ovanpå Ollama. Välj ett eller kombinera dem.


Vad du behöver (hårdvara och operativsystem)
- Operativsystem: Windows 10/11, macOS eller Linux (vi visar Windows-exempel nedan).
- Minne och lagring: 16–32 GB RAM är tillräckligt för modeller med 7–13B-parametrar; mer RAM hjälper vid större sammanhang. Håll tiotals GB ledigt på en SSD för modeller och cacher.
- GPU (valfritt men användbart): En modern GPU snabbar upp processen och gör det möjligt att köra större modeller. I Windows stöder Ollama GPU-acceleration och publicerar AMD-optimerade versioner.
- Anmärkning om AMD-integrerad grafik (APU): Nya Ryzen AI Max+-system kan dela systemminne som ”variabelt grafikminne” och därmed exponera upp till 96 GB VRAM för iGPU med rätt konfiguration – användbart för större modeller hemma.
Snabbstart (Windows): Den snabbaste vägen till din första prompt
- Installera Ollama
- Ladda ner Windows-installationsprogrammet från Ollama eller installera via Winget: "winget install --id Ollama.Ollama"
Efter installationen har du både Ollama-appen (GUI) och kommandoradsverktyget.
- Starta och verifiera
- Öppna Ollama-skrivbordsappen och logga in om du blir ombedd att göra det (ingen molntjänst krävs för lokal användning).
- Eller verifiera CLI: "ollama --version". (Du kommer att se ett versionsnummer.)
- Dra en startmodell
- I appen kan du bläddra bland och ladda ner en modell. Eller i en terminal: "ollama run llama3:8b
- "Detta kommer att ladda ner modellen och ta dig till en prompt – skriv en fråga och kör igång. Du kan bläddra bland många modeller (Gemma, Llama, Qwen, OLMo och fler) i Ollama-biblioteket.
- (Valfritt) Aktivera GPU-acceleration
- Håll dina grafikdrivrutiner uppdaterade. Ollama tillhandahåller Windows-versioner med AMD-acceleration, och AMD dokumenterar DirectML/ROCm-vägar för LLM på Radeon. I Ollama-appen bekräftar du att GPU:n har upptäckts (eller övervakar GPU-användningen i Aktivitetshanteraren under genereringen).
Vilken modell ska du prova först?
- ”Liten och snabb”: gemma3:1b eller llama3:8b bra för snabba svar och lågpresterande hårdvara.
- ”Balanserad”: 7B–13B-modeller (t.ex. olmo2:7b, llama3:8b instruct) är stabila för allmänt bruk.
- ”Större hjärnor”: Modeller med över 20 miljarder enheter (t.ex. gpt-oss:20b, större Llama-varianter) kräver mer RAM/VRAM och tålamod, men briljerar i svårare uppgifter. Du kan hämta någon av dessa direkt i appen eller via ollama run <model>.
Tips för att optimera din lokala LLM
- Kontextlängd: Större är inte alltid bättre. Stora kontexter (t.ex. 32k-64k tokens) kan bromsa genereringen avsevärt. Börja med 4k–8k och öka endast vid behov.
- Kvantisering: De flesta appar som tillhandahåller modeller är redan kvantiserade, vilket är praktiskt för att passa större modeller i begränsat VRAM.
- Lagring: Förvara modellerna på en SSD; HDD-diskar kommer att kännas tröga.
- Drivrutiner: Uppdatera GPU-drivrutiner och appen regelbundet Lokal AI utvecklas snabbt.
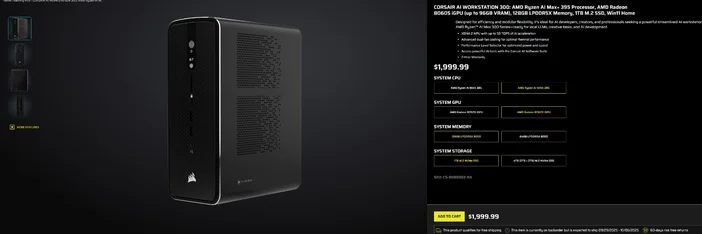
Användning av CORSAIR AI WORKSTATION 300
Om du hellre vill hoppa över den stegvisa monteringen och vill ha en kompakt, tyst stationär dator som är redo för lokala LLM:er direkt ur lådan, är CORSAIR AI WORKSTATION 300 uppfyller många krav för kreatörer och utvecklare:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (upp till 96 GB VRAM), XDNA 2 NPU upp till 50 TOPS
- Minne och lagring: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB+2 TB)
- Operativsystem: Windows 11 Home
- Design: 4,4 liters chassi med liten formfaktor, dubbla fläktar för kylning och en prestandanivåväljare
De "upp till 96 GB VRAM" på Radeon iGPU passar särskilt bra ihop med Windows-verktyg som kan allokera stort delat minne till GPU:n, vilket är praktiskt för större lokala modeller och längre sammanhang när du behöver dem. Det är en ren och kompakt väg till lokal AI-utveckling utan att kompromissa med kapaciteten.
Vanliga frågor
Behöver jag ett dedikerat grafikkort för att köra en lokal LLM?
Nej. Du kan köra mindre modeller på system med endast CPU, men svarstiderna blir långsammare. En modern GPU eller en avancerad APU med stort delat minne förbättrar hastigheten och gör att du kan öka modellstorleken.
Är detta privat?
Ja. Med lokala verktyg som Ollama eller LM Studio förblir kommandon och data som standard på din dator. (Integrationer som du lägger till kan fungera annorlunda, så kontrollera alltid inställningarna.)
Var hittar jag modeller?
Ollama Library listar populära, uppdaterade alternativ (Llama, Gemma, Qwen, OLMo och fler). Varje modellida visar storlekar och exempelkommandon.
Kan CORSAIR AI WORKSTATION 300 hantera stora modeller?
Den är utformad för lokala LLM:er, med 128 GB minne och en iGPU som kan komma åt upp till 96 GB VRAM, vilket ger utmärkt utrymme för avancerade lokala arbetsbelastningar och långa sammanhang, särskilt eftersom AMD:s Windows-drivrutiner utökar stödet för stora allokeringar. Den faktiska genomströmningen beror på modellstorlek, kvantisering och inställningar.
PRODUKTER I ARTIKEL
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.