En CUDA-kärna är en av de små matematiska enheterna inuti en NVIDIA GPU som utför grovjobbet för grafik och parallellberäkning. Varje kärna finns i ett större block som kallas Streaming Multiprocessor (SM), och på moderna GeForce ”Blackwell”-GPU:er innehåller varje SM 128 CUDA-kärnor. Det är därför du ser totala antal som 21 760 CUDA-kärnor på en RTX 5090. Chipet har helt enkelt många SM:er, var och en fylld med dessa kärnor.
CUDA (NVIDIAs parallella beräkningsplattform) är mjukvarusidan av historien: den låter appar och ramverk skicka massivt parallella uppgifter som rendering, AI och simulering till dessa kärnor på ett effektivt sätt.

Hur fungerar CUDA-kärnor?
Tänk på en GPU som en fabrik utformad för stora arbetsuppgifter. CUDA-kärnor hanterar arbete i warps-grupper om 32 trådar som utför samma instruktion på olika data (en modell som NVIDIA kallar SIMT). Det är så GPU:er kan hantera tusentals operationer samtidigt. Varje SM har schemaläggare som håller många warps igång för att dölja minneslatens och hålla kärnorna sysselsatta.
En användbar mental bild:
- CUDA-kärna = en enskild arbetare (utför aritmetiska operationer som addition och multiplikation).
- SM = en arbetsyta med egna schemaläggare, cacher, specialfunktioner, Tensor Core(s) etc.
- GPU = hela fabriken, med många SM som arbetar parallellt.
CUDA-kärnor jämfört med CPU-kärnor (och andra GPU-kärnor)
- Inte CPU-kärnor: En CUDA-kärna är en enklare aritmetisk bana som är optimerad för genomströmning, inte en stor, latensanpassad CPU-kärna för allmänt bruk. GPU:er skalar genom att ha många av dessa små banor som arbetar tillsammans. (CUDA:s programmeringsguide förklarar denna genomströmningsorienterade design.)
- Skillnad från specialiserade GPU-kärnor:
- Tensor Cores är matrismatematiska motorer som superladdar AI/ML och funktioner som DLSS.
- RT-kärnor accelererar strålspårning (BVH-genomgång, strål-/triangeltester).
Dessa avlastar specifika uppgifter så att CUDA-kärnorna kan fokusera på skuggning/beräkning.

Bildkälla: NVIDIA
Betyder fler CUDA-kärnor alltid bättre prestanda?
Vanligtvis, men inte på egen hand. Arkitekturen spelar stor roll. Till exempel fördubblade NVIDIAs Ampere-generation FP32-genomströmningen per SM jämfört med Turing, så effekten per kärna förändrades mellan generationerna. Ada utökade också cachen avsevärt (särskilt L2), vilket ökar många arbetsbelastningar utan att ändra antalet kärnor. Kort sagt: att jämföra antalet CUDA-kärnor mellan olika generationer är inte att jämföra äpplen med äpplen.
Andra viktiga faktorer:
- Klockhastigheter och effektmarginal (hur snabbt kärnorna körs).
- Minnesbandbredd och cacheminnesstorlek (matar kärnorna).
- Användning av Tensor/RT-kärnor (AI och strålspårning avlastar CUDA-kärnor).
- Drivrutiner och programvara (hur väl en app använder GPU via CUDA).
Vad gör CUDA-kärnor egentligen i praktiken?
- Spel/grafik: De kör shaderprogram (vertex, pixel, compute) under huven. RT-kärnor hanterar de tunga ray tracing-stegen; CUDA-kärnor utför fortfarande mycket skuggning och beräkningar kring dem.
- Innehållsskapande och simulering: Fysiklösare, brusreducerare, renderingskärnor, videoeffekter – många är skrivna för att dra nytta av CUDA:s parallella modell.
- AI/ML: Tensoroperationer går till Tensor Cores, men mycket förbehandling, efterbehandling och icke-matrisarbete körs fortfarande på CUDA-kärnor.
Hur många CUDA-kärnor behöver jag?
En bra tumregel:
- Spel med hög FPS 1080p–1440p: Titta på hela GPU:n (arkitektur, klockfrekvenser, minne, RT/Tensor-funktioner), inte bara antalet kärnor. Benchmarktest är viktigare än rena siffror.
- 4K eller tung strålspårning: Du får fördelar av fler SM/CUDA-kärnor och starka RT/Tensor-block, plus bandbredd och cache.
- AI/beräkning: Kärnantalet hjälper, men Tensor Core-kapacitet, VRAM-storlek och minnesbandbredd avgör ofta genomströmningen.
Om du vill göra en snabb kontroll av skalan, har RTX 5090 21 760 CUDA-kärnor, vilket visar hur NVIDIA räknar per SM-kärnor över många SM. Men återigen kommer prestandaförbättringarna från den totala designen, inte bara från antalet.
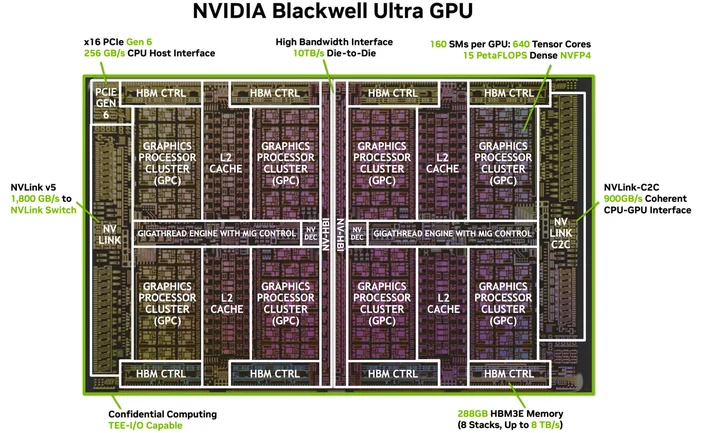
Bildkälla: NVIDIA
Behöver jag speciell programvara eller kablar? (CUDA:s ”HDMI för 4K”)
Du behöver ingen speciell kabel, men du behöver rätt programvara. CUDA är NVIDIAs plattform; appar använder den via drivrutiner, verktygssatser och bibliotek. Många populära applikationer och ramverk är redan byggda för att utnyttja CUDA-acceleration när dina NVIDIA-drivrutiner och (vid behov) CUDA Toolkit är installerade. Kompatibla appar använder den helt enkelt.
Vilka GPU:er stöder CUDA?
CUDA körs på CUDA-kompatibla NVIDIA-GPU:er i alla produktlinjer (GeForce/RTX för spel och skapande, professionella RTX och GPU:er för datacenter). Programmeringsguiden anger att modellen kan skalas över många GPU-generationer och SKU:er. NVIDIA har en lista över CUDA-kompatibla GPU:er och deras beräkningskapacitet.
Är en CUDA-kärna samma sak som en ”shader-kärna”?
I vardagligt GPU-språk, ja på NVIDIA GPU:er, avser ”CUDA-kärnor” de programmerbara FP32/INT32 ALU:er som används för skuggning och allmän beräkning inuti varje SM.
Varför skiljer sig antalet CUDA-kärnor så mycket mellan olika generationer?
Eftersom arkitekturer utvecklas. Ampere ändrade FP32-datavägar (mer arbete per klockcykel) och Ada omarbetade cacharna så att prestandan inte skalar linjärt med antalet kärnor.
Vad är en varp igen?
En grupp om 32 trådar som körs i lock-step på SM. Appar startar tusentals trådar; GPU:n schemalägger dem som warps för att hålla hårdvaran sysselsatt.
Hjälper CUDA-kärnor till med AI?
Ja, men de stora acceleratorerna för modern AI är Tensor Cores. CUDA-kärnor hanterar fortfarande mycket av arbetet i dessa pipelines.
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.