HOW TO
So führen Sie ein lokales LLM unter Windows aus (keine Cloud erforderlich)
Letzte Aktualisierung:
Wenn Sie ein LLM lokal ausführen, befindet sich das Modell auf Ihrem PC, und Ihre Eingaben (sowie alle Dateien, die Sie ihm zuführen) müssen Ihren Rechner nicht verlassen. Kein Cloud-Konto. Keine API-Schlüssel. Kein „Wir trainieren mit Ihren Daten … wahrscheinlich nicht … vielleicht.“ Nur Sie, Ihr PC und ein Modell, das jede Aufgabe erledigt, die Sie ihm stellen.
Was genau ist ein „Local LLM“?
Ein lokales LLM ist ein großes Sprachmodell, das auf Ihrem Computer statt auf einem Remote-Server läuft. In der Praxis bedeutet das in der Regel, dass Sie Modelldateien herunterladen, sie in eine lokale App laden und mit ihnen auf dieselbe Weise chatten, wie Sie mit einem Cloud-Assistenten chatten würden – nur dass der „Server“ Ihr PC ist.
Ein LLM lokal „auszuführen“ bedeutet fast immer, Inferenz zu betreiben (Antworten zu generieren), und nicht, ein völlig neues Modell von Grund auf zu trainieren.
Warum einen lokalen LLM betreiben?
Es gibt einige Gründe, warum Nutzer von Cloud-basierten LLMs auf lokale Modelle umsteigen:
- Datenschutz: Ihre Eingaben bleiben auf dem Gerät gespeichert (sofern Sie keine Cloud-Verbindungen nutzen).
- Offline-Nutzung: Sobald das Modell heruntergeladen ist, können Sie es ohne Internetverbindung ausführen.
- Keine Nutzungsbeschränkungen: Keine Geschwindigkeitsbegrenzungen, kein „Sie haben Ihr Tageskontingent aufgebraucht“, keine unerwarteten Rechnungen.
- Auswahl: Wählen Sie das gewünschte Modell aus – Sie sind nicht an ein Abonnement gebunden.
Natürlich tauscht man Komfort gegen Kontrolle ein. Ein Cloud-Modell kann wie Zauberei wirken; ein lokales Modell kann – je nach Hardware – ebenfalls wie Zauberei wirken.
Was braucht man, um ein lokales LLM zu betreiben?
Kurz gesagt: Die CPU leistet die Arbeit, die GPU unterstützt sie, und der Arbeitsspeicher ist entscheidend.
Folgende Faktoren entscheiden tatsächlich darüber, ob du eine schöne Zeit haben wirst:
- RAM / VRAM: Größere Modelle benötigen mehr Speicher. Wenn der Speicher knapp wird, bricht das Modell ab.
- Speicherplatz: Modelle können sehr groß sein. Einige Bibliotheken weisen darauf hin, dass der Speicherbedarf je nach heruntergeladenem Modell mehrere zehn bis mehrere hundert GB betragen kann.
- GPU: Wenn Ihre App Ihre GPU unterstützt, werden Sie in der Regel eine deutliche Geschwindigkeitssteigerung feststellen.
Ein moderner Windows 10/11-Rechner mit mindestens 32 GB RAM ist eine solide Grundlage für kleinere lokale Modelle, und mit mehr Arbeitsspeicher lassen sich größere Modelle komfortabler ausführen.
Wähle eine App für „lokale LLM-Ausführung“
LM Studio (benutzerfreundliche Oberfläche)
LM Studio ist eine Desktop-Anwendung, mit der Sie Models herunterladen und lokal mit ihnen chatten können. Außerdem enthält sie eine programmierbare lokale API für Entwickler.
Ollama (einfache Befehlszeilenschnittstelle + lokale API)
Ollama läuft als native Windows-Anwendung und bietet Ihnen einen Befehlszeilen-Workflow sowie einen lokalen HTTP-API-Endpunkt. Es unterstützt ausdrücklich NVIDIA- und AMD Radeon-GPUs unter Windows.
llama.cpp (für Tüftler)
Wenn Sie maximale Kontrolle wünschen, ist „llama.cpp“ eine beliebte Open-Source-Inferenz-Engine mit Anleitungen zur Erstellung und mehreren Backends.

Installieren und starten Sie Ihr erstes Modell
Größere Modelle benötigen mehr RAM und/oder VRAM. Wenn du nicht genug davon hast, kommt es zu Leistungseinbußen, Abstürzen oder ständigem Auslagern auf die Festplatte (was sich so anfühlt, als würde dein PC in Zeitlupe arbeiten).
Eine sichere Faustregel für int4-quantisierte Modelle:
- 8 GB RAM → ~3B-Modelle
- 16 GB RAM → Modelle der 7B-Serie
- 32 GB RAM → Modelle der ~13B-Serie
Und wenn Sie auf GPU-Beschleunigung setzen:
- 6 GB VRAM → ~3 Milliarden Modelle
- 8 GB VRAM → ~7 Milliarden Modelle
- 12 GB VRAM → ~13 Milliarden Modelle
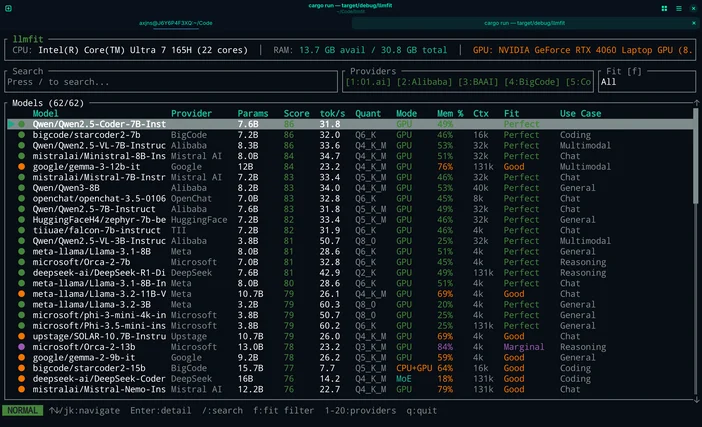
Oder wenn Sie nicht raten möchten, können Sie LLMfit verwenden, um Modelle genau auf Ihre Hardware abzustimmen.
LLMfit ist ein Terminal-Tool, das Ihre CPU, Ihren Arbeitsspeicher und Ihre GPU/VRAM erkennt und anschließend Modelle nach Eignung, erwarteter Geschwindigkeit, Kontext und Qualitäteinstuft , sodassSie schon vor dem Herunterladen sehen können, welche Modelle gut laufen werden.
Wofür es gut ist:
- Modelle finden, die tatsächlich zu deinen RAM-/VRAM-Grenzen passen
- Empfohlene Quantisierungswerte anzeigen (damit Sie nicht zu viel Speicher belegen)
- Eine sortierte Auswahlliste statt Modell-Hubs zum „Doomscrolling“
So wird es in diesem Arbeitsablauf verwendet:
- Führen Sie llmfit aus, um Ihre Systemhardware zu scannen
- Schau dir die obersten „Treffer“ / Empfehlungen an
- Wähle eine Modellgröße aus, die zu deiner Maschine passt, und lade sie dann in LM Studio / Ollama / llama herunter
Das war's!
Das war’s schon. Wählen Sie eine Laufzeitumgebung aus, laden Sie ein für Ihre Hardware passendes Modell herunter und legen Sie los! Alles bleibt auf Ihrem Rechner. Sie brauchen weder einen Informatikabschluss noch ein Cloud-Abonnement oder ein Wochenende voller Fehlerbehebung. Der gesamte Vorgang dauert etwa so lange wie die Installation eines Spiels. Und sobald es läuft, haben Sie einen privaten, offline arbeitenden KI-Assistenten, der sich ganz nach Ihren Vorstellungen richtet.
Wo der CORSAIR AI300 zum Einsatz kommt
Wenn Sie ernsthaft daran interessiert sind, lokale LLMs unter Windows auszuführen – insbesondere, wenn Sie größere Modelle, größere Kontextfenster oder eine flüssigere Leistung wünschen –, dann ist hier CORSAIR AI Workstation 300 (AI300) und der CORSAIR AI Software Stack dabei helfen, das nächste Level zu erreichen.
Lokale Inferenz stößt in der Regel an ihre Grenzen, was Speicherplatz und Durchsatz angeht. Der AI300 wurde unter Berücksichtigung dieser Tatsache entwickelt:
- Eine kompakte Workstation für lokale KI-Workflows
- Eine Konfiguration mit großem Arbeitsspeicher, die Ihnen Spielraum für umfangreichere Modelle bietet
- Verhalten des Grafikspeichers, das auf Skalierbarkeit für KI-Anwendungsfälle ausgelegt ist
- Ein Leistungswähler auf Hardware-Ebene (Leise / Ausgewogen / Max), damit Sie entscheiden können, ob Sie Ruhe oder Geschwindigkeit bevorzugen

Benötige ich eine NVIDIA-GPU, um ein lokales LLM unter Windows auszuführen?
Nein. Einige Tools unterstützen AMD unter Windows ausdrücklich; so wird beispielsweise in der Windows-Dokumentation von Ollama sowohl die Unterstützung für NVIDIA- als auch für AMD Radeon-GPUs erwähnt.
Kann ich ein lokales LLM komplett offline ausführen?
Ja, nachdem Sie die App und die Modelldateien heruntergeladen haben. Für die Erstinstallation und das Herunterladen der Modelle ist in der Regel eine Internetverbindung erforderlich, aber die Inferenz kann offline ausgeführt werden, sobald sich alles lokal befindet.
Ist lokale KI automatisch privat?
Das kann sein, hängt aber von Ihrer Konfiguration ab. Lokale Inferenz bedeutet, dass das Modell auf Ihrem Gerät ausgeführt wird, doch manche Apps bieten optionale Cloud-Verbindungen an. Wenn Ihr Ziel „keine Cloud erforderlich“ lautet, lassen Sie die Cloud-Integrationen deaktiviert und verwenden Sie ausschließlich lokale Modelle.
Warum läuft mein lokales Modell so langsam?
Meistens eines davon:
- Das Modell ist zu groß für Ihren verfügbaren Arbeitsspeicher/Grafikspeicher
- Du nutzt nur die CPU, obwohl eine GPU-Beschleunigung verfügbar ist
- Du hast eine hohe Kontextlänge gewählt, und das beansprucht viel Speicherplatz
- Dein Speicher ist voll (ja, das ist wichtig)
PRODUKTE IM ARTIKEL
Stay up to date with CORSAIR. Get our latest News, Guides, and Product Updates in your Google feeds.
Add CORSAIR as a preferred source
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.