

AI & DEEP LEARNING
THE COMPLETE AI COMPUTE STACK—DESK TO RACK
Whether you're a researcher or enterprise, CORSAIR Pro Systems offers GPU platforms built for every AI pipeline stage.
AI DEVELOPMENT PIPELINE
FROM PROTOTYPE TO PRODUCTION — WITHOUT LEAVING YOUR DESK
Whether you're building a proof-of-concept, validating an architecture before scaling to servers, or deploying a local AI assistant for your team — a multi-GPU workstation is the starting point.
TRAINING & FINE-TUNING
NVIDIA GB300 combines a high-performance Grace CPU and Blackwell Ultra GPU through NVLink C2C interconnect, delivering compute density comparable to rack-scale systems in a single deskside chassis.PRE-VALIDATION & EXPERIMENTATION
Validate model architectures and data pipelines on deskside hardware before committing to expensive data center GPU time. Catch problems early, ship faster.ON-PREMISES INFERENCE
Serve local LLMs, AI chatbots, or internal tools on hardware you control. RTX PRO Blackwell GPUs deliver strong inference throughput for small-scale and few-client deployments.
PLATFORMS
TWO PATHS, ONE PIPELINE
Start with a workstation for development and prototyping, then scale to rack-mounted GPU servers for production training and inference — or go directly to server-class hardware.


FEATURED PLATFORMS
PURPOSE-BUILT FOR EVERY SCALE
From a compact single-GPU workstation to a full 8-GPU HGX training server — every platform is configured, validated, and shipped ready to run.

FlexPrime V20R
- Form Factor
- Small
- CPU
- 1x AMD Ryzen 9000 Series
- GPU
- Up to 1x Double-Wide GPU
- MEMORY
- Up to 4x DDR5

FlexPrime V50R
- FORM FACTOR
- Mid Tower
- CPU
- 1x AMD Ryzen 9000 Series
- GPU
- Up to 2x Double-Wide GPU
- MEMORY
- Up to 4x DDR5

FlexPrime V80T
- FORM FACTOR
- Full Tower
- CPU
- 1x AMD Threadripper PRO 9000WX
- GPU
- Up to 4x Double-Wide GPU
- MEMORY
- Up to 8x DDR5 ECC/R

FlexPrime R80T
- FORM FACTOR
- Full Tower / Rackmount Convertible
- CPU
- 1x AMD Threadripper PRO 9000WX
- GPU
- Up to 4x Double-Wide GPU
- MEMORY
- Up to 8x DDR5 ECC/R




QUICK REFERENCE
WHICH PLATFORM DO I NEED?
Match your workload to the right platform at a glance.
CAPABILITIES
ACROSS THE AI LIFECYCLE
Our platforms support every phase — from early experimentation on a workstation to production-grade training and inference on GPU servers.

MODEL TRAINING
Full fine-tuning, LoRA, QLoRA, or training from scratch — configure single or multi-GPU systems to match your model size and data pipeline requirements.
INFERENCE & MODEL SERVING
Host models on your own infrastructure for real-time responses, batch processing, or multi-tenant serving. Keep data on-premises and eliminate per-query cloud costs.
RAG & AI ASSISTANTS
Deploy retrieval-augmented generation pipelines and domain-specific AI tools on hardware your organization owns and controls — no third-party API dependencies.

RESEARCH & PROTOTYPING
Explore new architectures, run ablation studies, and iterate on designs without competing for shared cloud GPU time or burning through pay-as-you-go credits.
COMPUTER VISION
Image classification, object detection, segmentation, and video analysis — GPU acceleration cuts training time dramatically for large-scale visual datasets.
NLP & LANGUAGE MODELS
Pre-train, fine-tune, and serve language models at any scale — from lightweight classifiers to 70B+ instruction-tuned LLMs running across multiple GPUs.
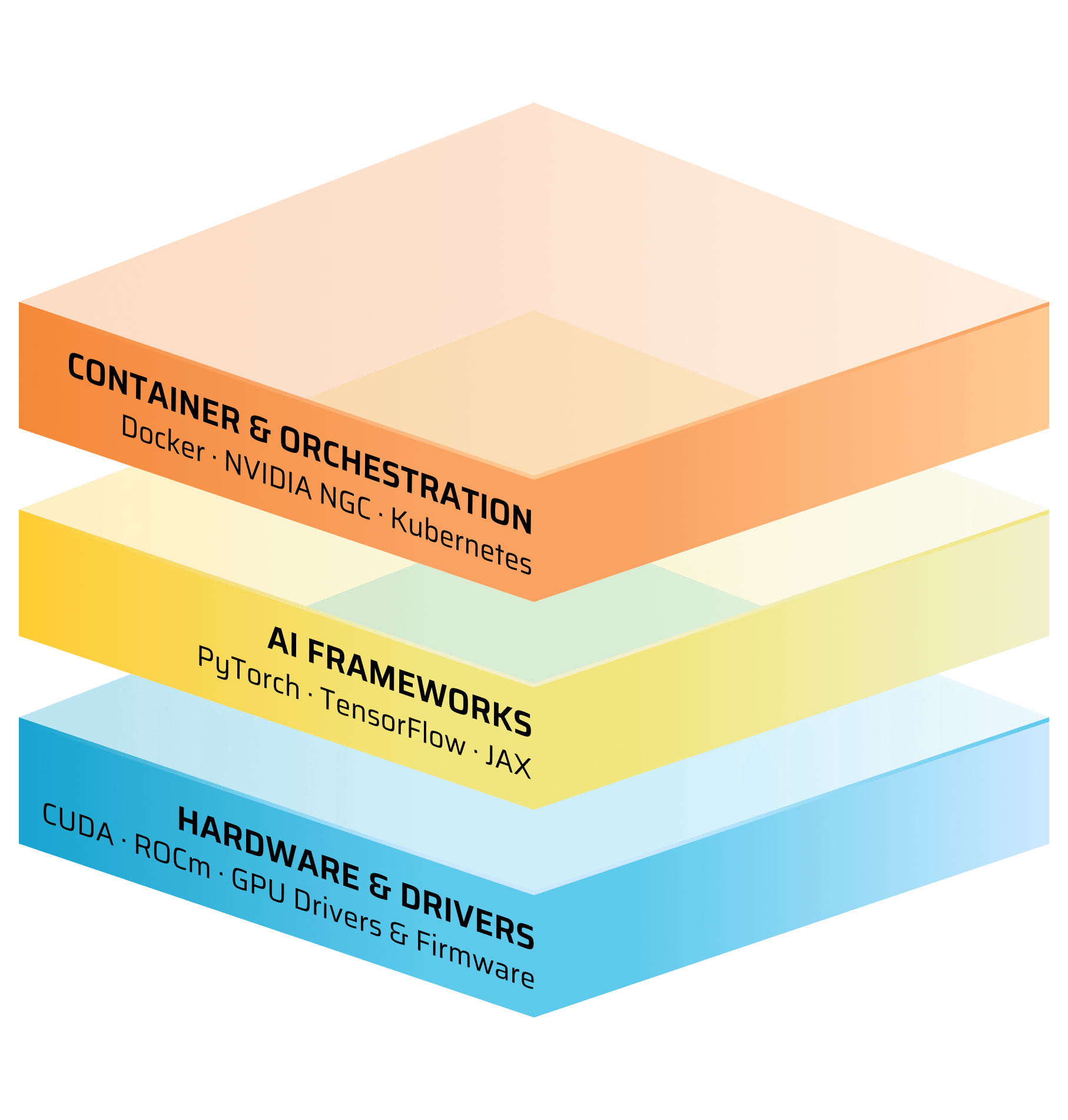
SOFTWARE STACK
SHIP-READY AI SOFTWARE STACK
Every workstation is built to your workload requirements. We install, configure, and validate your AI toolchain before shipping — so you can start training from day one, not day ten.
- Multi-GPU architecture — single to 4-GPU configs for parallel training and faster iteration
- Fully customizable — choose your CPU, memory, storage, and GPU mix to match your pipeline
- Validated software stack — AI frameworks, drivers, and containers installed and tested before delivery
ECOSYSTEM
VALIDATED AI SOFTWARE ECOSYSTEM
Every platform ships with your choice of frameworks, drivers, and containers — configured and tested for your workload.
- PyTorch
- TensorFlow
- Docker
- CUDA
- cuDNN
- vLLM
- Hugging Face
- DeepSpeed
- Triton Inference Server
- ONNX Runtime
- Jupyter
- RAPIDS
- NGC Containers
- Ubuntu
HOW TO CHOOSE SERVERS
KEY DIFFERENTIATORS
Not all AI systems are created equal. The right platform depends on your workload, GPU topology needs, and budget.

CPU TOPOLOGY
Single vs. dual socket — AMD dominant for more cores and PCIe lanes. Dual-socket for heavy data preprocessing pipelines.

GPU DENSITY
4-GPU for focused workloads and budget builds. 8-GPU for maximum parallel throughput in training and large-model inference.

GPU TOPOLOGY
PCIe for inference and budget training. HGX/SXM for serious training — GPU-to-GPU interconnect makes a massive difference.

WORKLOAD INTENT
Training is GPU↔GPU constrained — topology matters immensely. Inference focuses on latency, throughput, and memory capacity.