Ejecutar un modelo de lenguaje grande (LLM) en tu propio PC puede parecer intimidante, pero es sorprendentemente accesible. Un «LLM local» simplemente significa que la IA se ejecuta en tu hardware, sin nube, sin cuenta, y tus datos permanecen contigo. Piensa en una lluvia de ideas privada, ayuda con el código y preguntas y respuestas sobre documentos, todo sin enviar nada a Internet. Si te parece bien, vamos a llevarte de cero al primer prompt.
¿Qué herramientas estamos utilizando?
La opción más adecuada para principiantes en este momento es Ollama, una aplicación gratuita que descarga y ejecuta un amplio catálogo de modelos abiertos con comandos de una sola línea (ahora incluye una aplicación de escritorio para Windows y macOS, por lo que no es necesario vivir en un terminal).
Si prefieres una experiencia más visual y completa, LM Studio (también gratuito) es otra gran opción para descubrir, ejecutar y gestionar modelos locales. Open WebUI es una interfaz de chat ligera y autohospedada que puede instalarse sobre Ollama. Elige una o combínalas.


Lo que necesitarás (hardware y sistema operativo)
- Sistema operativo: Windows 10/11, macOS o Linux (a continuación mostraremos ejemplos de Windows).
- Memoria y almacenamiento: entre 16 y 32 GB de RAM son suficientes para modelos de 7 a 13 mil millones de parámetros; una mayor cantidad de RAM ayuda con contextos más grandes. Mantenga decenas de GB libres en un SSD para modelos y cachés.
- GPU (opcional pero útil): una GPU moderna acelera el proceso y permite ejecutar modelos más grandes. En Windows, Ollama admite la aceleración por GPU y publica compilaciones optimizadas para AMD.
- Nota sobre los gráficos integrados AMD (APU): los nuevos sistemas Ryzen AI Max+ pueden compartir la memoria del sistema como «memoria gráfica variable», exponiendo hasta 96 GB de VRAM a la iGPU con la configuración adecuada, lo que resulta útil para modelos más grandes en el hogar.
Inicio rápido (Windows): la forma más rápida de acceder a su primer indicador
- Instalar Ollama
- Descargue el instalador de Windows desde Ollama o instálelo a través de Winget:«winget install --id Ollama.Ollama».
Después de la instalación, tendrás tanto la aplicación Ollama (GUI) como la herramienta de línea de comandos.
- Iniciar y verificar
- Abre la aplicación de escritorio Ollama e inicia sesión si se te solicita (no se requiere conexión a la nube para el uso local).
- O verifica la CLI: «ollama --version».(Verás un número de versión).
- Elige un modelo inicial.
- En la aplicación, busca y descarga un modelo. O en un terminal: «ollama run llama3:8b».
- Estodescargará el modelo y te llevará a un indicador: escribe una pregunta y listo. Puedes explorar muchos modelos (Gemma, Llama, Qwen, OLMo y más) en la biblioteca Ollama.
- (Opcional) Habilitar la aceleración por GPU
- Mantenga actualizados los controladores gráficos. Ollama ofrece compilaciones de Windows con aceleración AMD, y AMD documenta las rutas DirectML/ROCm para LLM en Radeon. En la aplicación Ollama, confirme que se detecta la GPU (o observe el uso de la GPU en el Administrador de tareas mientras se genera).
¿Qué modelo deberías probar primero?
- «Pequeño y ágil»: gemma3:1b o llama3:8b, ideal para respuestas rápidas y hardware de gama baja.
- «Equilibrado»: modelos 7B-13B (por ejemplo, olmo2:7b, llama3:8b instruct) sólidos para uso general.
- «Cerebros más grandes»: los modelos de más de 20 mil millones (por ejemplo, gpt-oss:20b, variantes Llama más grandes) necesitan más RAM/VRAM y paciencia, pero destacan en tareas más difíciles. Puedes acceder a cualquiera de ellos directamente en la aplicación o mediante ollama run <model>.
Consejos para optimizar tu LLM local
- Longitud del contexto: más grande no siempre es mejor. Los contextos enormes (por ejemplo, de 32 000 a 64 000 tokens) pueden ralentizar considerablemente la generación. Empieza con 4000-8000 y aumenta solo cuando sea necesario.
- Cuantificación: la mayoría de los modelos proporcionados por la aplicación ya están cuantificados, lo que resulta útil para ajustar modelos más grandes a una VRAM limitada.
- Almacenamiento: Guarde los modelos en un SSD; los discos duros se sentirán lentos.
- Controladores: Actualiza los controladores de la GPU y la aplicación con regularidad. La IA local está evolucionando rápidamente.
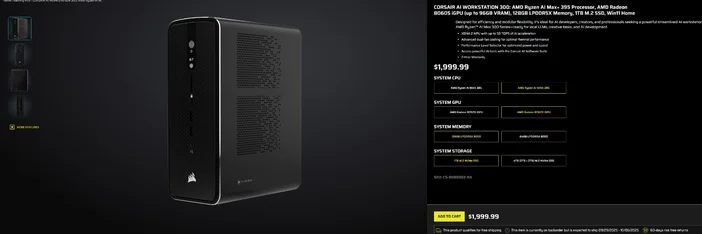
Uso de la CORSAIR AI WORKSTATION 300
Si prefiere evitar el montaje por piezas y desea un ordenador de sobremesa compacto y silencioso que esté listo para LLM locales nada más sacarlo de la caja, el CORSAIR AI WORKSTATION 300 cumple muchos requisitos para creadores y desarrolladores:
- CPU/GPU/NPU: AMD Ryzen™ AI Max+ 395, Radeon™ 8060S iGPU (hasta 96 GB de VRAM), XDNA 2 NPU hasta 50 TOPS
- Memoria y almacenamiento: 128 GB LPDDR5X‑8000, 4 TB NVMe (2 TB + 2 TB)
- Sistema operativo: Windows 11 Home
- Diseño: chasis de formato pequeño de 4,4 litros con refrigeración por doble ventilador y selector de nivel de rendimiento.
Los «hasta 96 GB de VRAM» de la iGPU Radeon combinan especialmente bien con las herramientas de Windows, que pueden asignar una gran cantidad de memoria compartida a la GPU, lo que resulta muy útil para modelos locales más grandes y contextos más largos cuando se necesitan. Es una vía limpia y compacta hacia el desarrollo local de IA sin comprometer la capacidad.
Preguntas frecuentes
¿Necesito una GPU dedicada para ejecutar un LLM local?
No. Puede ejecutar modelos más pequeños en sistemas que solo cuentan con CPU, aunque las respuestas serán más lentas. Una GPU moderna o una APU avanzada con una gran memoria compartida mejora la velocidad y le permite aumentar el tamaño del modelo.
¿Es esto privado?
Sí. Con herramientas locales como Ollama o LM Studio, las indicaciones y los datos permanecen en tu equipo de forma predeterminada. (Las integraciones que añadas pueden comportarse de forma diferente, comprueba siempre la configuración).
¿Dónde puedo encontrar modelos?
La biblioteca Ollama enumera opciones populares y actualizadas (Llama, Gemma, Qwen, OLMo y más). Cada página de modelo muestra los tamaños y ejemplos de comandos.
¿La CORSAIR AI WORKSTATION 300 puede manejar modelos grandes?
Está diseñado para LLM locales, con 128 GB de memoria y una iGPU que puede acceder a hasta 96 GB de VRAM, lo que ofrece un excelente margen para cargas de trabajo locales avanzadas y contextos largos, especialmente ahora que los controladores de Windows de AMD amplían la compatibilidad con asignaciones de gran tamaño. El rendimiento real depende del tamaño del modelo, la cuantificación y la configuración.
PRODUCTOS EN EL ARTÍCULO
JOIN OUR OFFICIAL CORSAIR COMMUNITIES
Join our official CORSAIR Communities! Whether you're new or old to PC Building, have questions about our products, or want to chat about the latest PC, tech, and gaming trends, our community is the place for you.